






参考文档:
https://blog.csdn.net/github_37882837/article/details/90672881
http://c.biancheng.net/view/880.html
https://blog.csdn.net/qq_22613757/article/details/80853391
https://www.iteye.com/topic/816268
前言
网络上关于文件与文件系统的内容比较零散,这里只是搬砖。把各路大神的文章读了之后以自己理解的方式发布出来,供以后查阅。
一、文件系统
1、文件系统概念
文件系统是对一个设备上的数据和元数据进行组织的机制。
各操作系统使用的文件系统各不相同,例如,WINDOWS98以前的微软操作系统使用FAT(FAT16)文件系统,WINDOWS 2000以后的版本使用NTFS文件系统。Linux正统的文件系统是EXT2。
对硬盘进行格式化,只是清除了硬盘中的数据,其实不然,格式化过程中还向硬盘中写入了文件系统。因为不同的操作系统,管理系统中文件的方式也不尽相同(给文件设定的属性和权限也不完全一样),因此,为了使硬盘有效存放当前系统中的文件数据,就需要将硬盘进行格式化,令其使用和操作系统一样(或接近)的文件系统格式。
2、文件系统层次

图1 Linux文件系统层次
由上而下主要分为用户层、VFS层、文件系统层、通用块驱动层、驱动层、物理层
1)Application:最上面用户层就是我们日常使用的各种程序,需要的接口主要是文件的创建、删除、打开、关闭、写、读等。
2)System Call Interface(SCI): 对虚拟文件系统提供的接口进行封装。
3)VFS层:虚拟文件系统,对不同的文件系统抽象,为上层应用提供统一的API接口。用户空间无需关心不同文件系统中不一样的API,VFS提供的这统一API,再经过System Call Interface封装后,用户就可以经过SCI的系统调用来操作不同的文件系统。
4)文件系统层:不同的文件系统实现了VFS的这些函数,通过指针注册到VFS里面。所以,用户的操作通过VFS转到各种文件系统。
5)General Block Driver Layer:隐藏不同硬件设备的细节,为内核提供统一的IO操作接口;如果在这一层做修改会影响所有文件系统,不管是ext3、ext4还是其他文件系统。
6)Device Driver:磁盘驱动层,磁盘的驱动程序把对磁盘的读写命令转化为各自的协议,或者是自己硬件可以识别的自定义命令,发送给磁盘控制器。
7)Physical disk:磁盘物理层,读写物理数据到磁盘介质。
3、文件系统存储结构
以EXT4文件系统为例,EXT4文件系统主要使用块组0中的超级块和块组描述符表,在其他一些特定块组中有超级块和块组描述符表的冗余备份。如果块组中不含冗余备份,那么块组就会以数据块位图开始。当格式化磁盘成为Ext4文件系统的时候,mkfs将在块组描述符表后面分配预留GDT表数据块(“Reserve GDT blocks”)以用于将来扩展文件系统。紧接在预留GDT表数据块后的是数据块位图与inode的表位图,这两个位图分别表示本块组内的数据块与inode的表的使用,索引节点表数据块之后就是存储文件的数据块了。在这些各种各样的块中,超级块,GDT,块位图,索引节点位图都是整个文件系统的元数据,当然的inode表也是文件系统的元数据,但是inode节点表是与文件一一对应的,我更倾向于将索引节点当做文件的元数据,因为在实际格式化文件系统的时候,除了已经使用的十来个外,其他的inode表中实际上是没有任何数据 的,直到创建了相应的文件才会分配的inode表,文件系统才会在索引节点表中写入与文件相关的inode的信息。
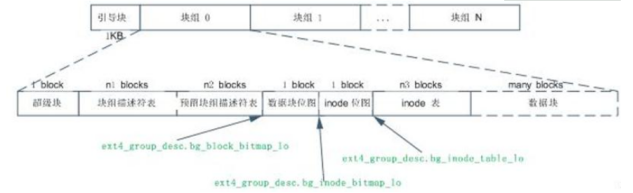
图2 EXT4文件系统的标准磁盘布局
1)超级块:文件系统中的第一个块被称为超级块(录整个文件系统的信息),这个块存放文件系统本身的结构信息。比如,超级块记录数据块个数、inode个数、未被使用的块个数、支持的特性、管理信息等。
2)快组描述符:每个块组都有一个相应的组描述符来描述它,所有的组描述符形成一个组描述符表,组描述符表可能占多个数据块。组描述符就相当于每个块组的超级块,一旦某个组描述符遭到破坏,整个块组将无法使用,所以组描述符表也像超级块那样,在每个块组中进行备份,以防遭到破坏。组描述符表所占的块和普通的数据块一样,在使用时被调入块高速缓存。
3)数据块位图与inode位图:数据块位图跟踪块组中数据块使用情况。Inode位图跟踪块组中Inode使用情况。每个位图一个数据块,每一位用0或1表示一个块组中数据块或inode表中inode的使用情况。如果一个数据块大小是4KB的话,那一个位图块可以表示4*1024*8个数据块的使用情况,这也是单个块组具有的最大数据块个数。这样可以算出一个块组大小是128MB。当然一个位图块也可以表示4*1024*8个inode的使用情况,但是实际上一个块组中即使存满了文件,也不会用到这么多的inode,因为实际系统中基本不会出现所有文件大小都小于等于1个数据块大小的情况。实际上一个块组中有多少个inode,在块组描述符中是确定的,在文件系统格式化过程中也会看到这个数值,如果没记错的话,大概是每4个还是8个数据块分配一个inode空间。
4)node 表包含一份清单,其中列出了对应文件系统的所有 inode 编号。当用户搜索或者访问一个文件时,Linux系统通过 inode 表查找正确的 inode 编号。在找到 inode 编号之后,相关的命令才可以访问该 inode ,并对其进行适当的更改。
4、硬链接与软链接的联系与区别
硬链接 (hard link) 与软链接(又称符号链接,即soft link或symbolic link)。链接为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。
若一个 inode 号对应多个文件名,则称这些文件为硬链接。换言之,硬链接就是同一个文件使用了多个别名(见图3 hard link 就是 file 的一个别名,他们有共同的 inode)。硬链接可由命令 link 或 ln 创建。如下是对文件 oldfile 创建硬链接。
link oldfile newfile 或
ln oldfile newfile
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
1)文件有相同的 inode 及 data block;
2)只能对已存在的文件进行创建;
3)不能交叉文件系统进行硬链接的创建;
4)不能对目录进行创建,只可对文件创建;
5)删除一个硬链接文件并不影响其他有相同 inode 号的文件。
软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块(见图3)。因此软链接的创建与使用没有类似硬链接的诸多限制:
1)软链接有自己的文件属性及权限等;
2)可对不存在的文件或目录创建软链接;
3)软链接可交叉文件系统;
4)软链接可对文件或目录创建;
5)创建软链接时,链接计数 i_nlink 不会增加;
6)删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
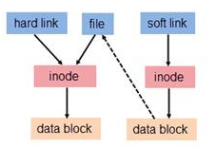
图3 软链接的访问
创建软链接:ln -s oldfile newfile.soft
复制文件、移动文件和删除文件对inode的影响:
1)复制文件是创建文件,并占Inode和Block的。
文件创建过程是:先查找一个空的Inode,写入新的Inode table,创建Directory,对应文件名,向block中写入文件内容;
2)移动文件分两种情况:
在同一个文件系统内移动文件,创建一个新的文件名与inode的对应关系,即在Directory中写入信息,然后在Directory中删除旧的信息,更新CTIME(文件时间),其他信息如inode等均无影响;
在不同文件系统中移动文件时,先查找一个空的inode,写入新的inode table,创建Directory中对应关系,向block中写入文件内容,同时还会更改CTIME。
3)删除文件,实质上就是减少link count,当link count为0时,就表示这个inode可以使用,并把block标记为可写,但并没有消除block里面数据,除非有新的数据要用到这个block。
5、Linux支持的常见文件系统

在设备上查看当前linux系统支持的文件系统类型:cat /proc/filesystems
二、文件
1、文件存储结构
Linux正统的文件系统(如ext2、ext3)一个文件由目录项、inode和数据块组成。
目录项:包括文件名和inode节点号。
Inode:又称文件索引节点,是文件基本信息的存放地和数据块指针存放地。
数据块:文件的具体内容存放地。
Linux正统的文件系统(如ext2、3、4等)将硬盘分区时会划分出目录块、inode Table区块和data block数据区域。一个文件由一个目录项、inode和数据区域块组成。Inode包含文件的属性(如读写属性、owner等,以及指向数据块的指针),数据区域块则是文件内容。当查看某个文件时,会先从inode table中查出文件属性及数据存放点,再从数据块中读取数据。
文件存储结构大概如下:

图4 文件存储结构
其中目录项的结构如下(每个文件的目录项存储在改文件所属目录的文件内容里):
![]()
图5 目录项结构
其中文件的inode结构如下(inode里所包含的文件信息可以通过stat filename查看得到):
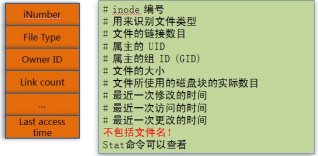
图6 inode结构
以上只反映大体的结构,linux文件系统本身在不断发展。但是以上概念基本是不变的。且如ext2、ext3、ext4文件系统也存在很大差别,如果要了解可以查看专门的文件系统介绍。
2、文件系统如何存取文件
1)根据文件名,通过Directory里的对应关系,找到文件对应的inode编号(inode节点号);
2)查找Inode table,找到inode编号对应的inode节点(节点中存储了对应数据块的地址);
3)根据inode节点中的数据块指针读取到相应的数据块;
注意:
1)这里有一个重要的内容,就是Directory,他不是我们通常说的目录,而是一个列表,记录了一个文件/目录名称对应的 Inode number。
2)inode节点并不存储文件的文件名,因为文件名是文件所在目录的数据,所以会保存在上一级目录的数据块中。
3.文件类型
Linux下面的文件类型主要有:
1)普通文件:C语言元代码、SHELL脚本、二进制的可执行文件等。分为纯文本和二进制。
2)目录文件:目录,存储文件的唯一地方。
3)链接文件:指向同一个文件或目录的的文件。
4)特殊文件:与系统外设相关的,通常在/dev下面。分为块设备和字符设备。
可以通过ls –l, file, stat几个命令来查看文件的类型等相关信息。
a:常规文件,即f:
d:directory,目录文件
b:block device,块设备文件,支持以块为单位进行随机访问
c:character device,字符设备文件,支持以字符为单位进行访问
major number:主设备号,用于表示设备型号,进而确定要加载的驱动程序
minor number:次设备号,用于标识同类型中不同的设备
l:symbolic link ,符号链接文件
p:pipe,命名管道
s:socket,套接字文件















 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









