









Kafka本地集群搭建完成,简单入门Kafka集群的shell操作后,开始Java代码实现简单功能。
kafka版本说明:此处使用最新版本(现在)—1.1.0版本
1.1.0 is the latest release. The current stable version is 1.1.0.
由于kafka集群环境搭建的遗留问题,导致运行Java代码时会报错,所以首先将环境完善了。
修改主机名和ip映射(在配置bootstrap.servers时统一用主机名,不用ip)
// 修改主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=tyron0
// 修改主机名和IP的映射关系
vi /etc/hosts
192.168.1.100 tyron0
192.168.1.101 tyron1
192.168.1.102 tyron2centos修改主机名的便捷方式:hostnamectl命令,详情如图:
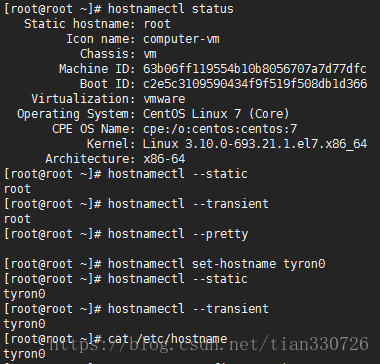
更详细说明可以参考:如何在CentOS 7上修改主机名
同时,本机hosts也配置上映射关系,内容与Linux环境相同。
KafkaProducer
public static void main(String[] args) {
// 定义属性,以了解Producer如何找到集群,对消息进行序列化,并在适当时将消息定向到特定的分区
Properties props = new Properties();
// 这里不是配置broker.id了,这个是配置bootstrap.servers
props.put("bootstrap.servers", "tyron0:9092,tyron1:9092,tyron2:9092");
/*
* 此配置是 Producer 在确认一个请求发送完成之前需要收到的反馈信息的数量。
* acks=0 如果设置为0,则 producer 不会等待服务器的反馈。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。在这种情况下,服务器是否收到请求是没法保证的,并且参数retries也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。
* acks=1 如果设置为1,leader节点会将记录写入本地日志,并且在所有 follower 节点反馈之前就先确认成功。在这种情况下,如果 leader 节点在接收记录之后,并且在 follower 节点复制数据完成之前产生错误,则这条记录会丢失。
* acks=all 如果设置为all,这就意味着 leader 节点会等待所有同步中的副本确认之后再确认这条记录是否发送完成。只要至少有一个同步副本存在,记录就不会丢失。这种方式是对请求传递的最有效保证。acks=-1与acks=all是等效的。
*/
props.put("acks", "all");
// retries若设置大于0的值,则客户端会将发送失败的记录重新发送,尽管这些记录有可能是暂时性的错误。请注意,这种 retry 与客户端收到错误信息之后重新发送记录并无区别。
props.put("retries", 0);
// batch.size:当将多个记录被发送到同一个分区时, Producer 将尝试将记录组合到更少的请求中。这有助于提升客户端和服务器端的性能。这个配置控制一个批次的默认大小(以字节为单位)。
props.put("batch.size", 16384);
// linger.ms:Producer 会将两个请求发送时间间隔内到达的记录合并到一个单独的批处理请求中。通常只有当记录到达的速度超过了发送的速度时才会出现这种情况。然而,在某些场景下,即使处于可接受的负载下,客户端也希望能减少请求的数量。
props.put("linger.ms", 1);
// buffer.memory:Producer 用来缓冲等待被发送到服务器的记录的总字节数。如果记录发送的速度比发送到服务器的速度快, Producer 就会阻塞,如果阻塞的时间超过 max.block.ms 配置的时长,则会抛出一个异常。
props.put("buffer.memory", 33554432);
// 指定key value的序列化方式
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 这个地方和1.0X之前的版本有不一样的,这个是使用kafkaproducer 类来实例化
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("kafka-action", Integer.toString(i), Integer.toString(i)));
producer.close();
}KafkaConsumer
public static void main(String[] args) {
Properties props = new Properties();
// 这里不是配置zookeeper了,这个是配置bootstrap.servers
props.put("bootstrap.servers", "tyron0:9092,tyron1:9092,tyron2:9092");
// 标识该使用者所属的消费者组的唯一字符串。
props.put("group.id", "kafka-action");
// 如果true,消费者的偏移量将在后台定期提交。
props.put("enable.auto.commit", "true");
// 消费者偏移量在毫秒内自动提交给Kafka
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 配置topic
consumer.subscribe(Arrays.asList("kafka-action"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records)
// 直接通过record.offset()得到offset的值
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
代码中注释很详细,还有之前版本的简要说明,最后的结果如图所示:
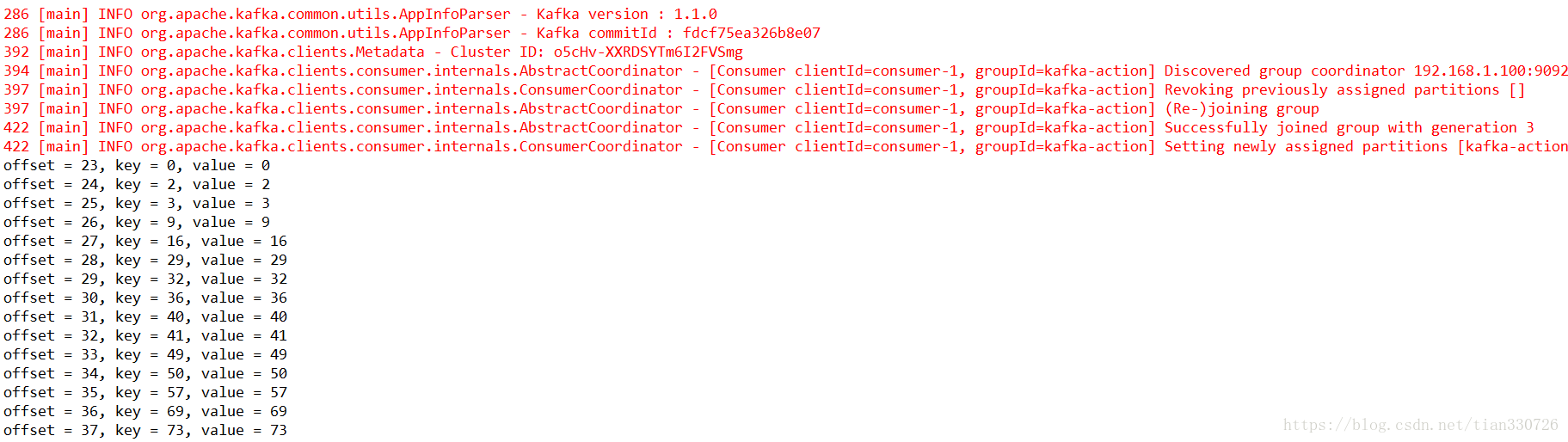














 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









