






一、背景分析
有近20年的广告数据,需要对外提供查询分析服务(对数据进行Ad-Hoc式查询,Ad-Hoc:即席查询,允许终端用户灵活的自定义、创建查询条件,后端引擎根据发送过来的查询请求生成用户要求的报表、统计分析结果。即席查询是非定制化的,不可预知的。),当前采用了Apache Impala作为查询分析引擎。这些广告数据涵盖了各种媒介,每种媒介又进行定义了不同的媒体。
因此一条数据可以表示为,谁(广告主)在什么时候(时间)、在哪里(媒体)播放了一条什么样的(产品)广告,这样的一条日志数据。在数据生产的过程中,存在一定的识别误差,在后续的复查环节需要对T-1或者T-7的数据进行修正,但T-1或者T-7的数据已经进入数仓且对外提供数据分析服务(这里已经产生数据震荡),因此需要对数仓中的数据进行修正。
生产环节对数据进行修正的粒度不是行级的,而是媒体/天的粒度(一个媒体这一天的数据都要进行修正),层层传递到数仓也是媒体/天的粒度进行数据的修正更新。这才有了这个按照媒体/天的动态分区。
二、Impala分区
当数据的体量大时,使用分区技术能很好的缩小查询数据的范围,从而提高查询的效率以及节省磁盘的IO、CPU、内存等资源。分区分为两种:静态分区、动态分区。
静态分区:Specifying all the partition columns in a SQL statement is called static partitioning, because the statement affects a single predictable partition. For example, you use static partitioning with an ALTER TABLE statement that affects only one partition, or with an INSERT statement that inserts all values into the same partition:
insert into t1 partition(x=10, y='a') select c1 from some_other_table;
动态分区:When you specify some partition key columns in an INSERT statement, but leave out the values, Impala determines which partition to insert. This technique is called dynamic partitioning:
insert into t1 partition(x, y='b') select c1, c2 from some_other_table;
-- Create new partition if necessary based on variable year, month, and day; insert a single value.
insert into weather partition (year, month, day) select 'cloudy',2014,4,21;
-- Create new partition if necessary for specified year and month but variable day; insert a single value.
insert into weather partition (year=2014, month=04, day) select 'sunny',22;
The more key columns you specify in the PARTITION clause, the fewer columns you need in the SELECT list. The trailing columns in the SELECT list are substituted in order for the partition key columns with no specified value.
三、操作步骤
INSERT INTO medium_data.tv_data partition (media_id,ds)
SELECT
tv.id
,tv.m_type
,tv.ad_date
,tv.sub_id
,tv.ad_cost
,tv.ad_time
,tv.ad_length
,tv.cate_id
,tv.lang_id
,tv.qual_id
,tv.spec_id
,tv.ad_posit
,tv.t_break
,tv.t_b_net
,tv.pre_s_id
,tv.post_s_id
,tv.pre_pg_id
,tv.post_pg_id
,CAST(weekofyear(ad_date) AS INT) AS week_of_year
,concat_ws(' ', substr(AD_Date,1, 10), ad_time) AS ad_timestamp
,CAST(CASE WHEN dayofweek(ad_date) = 1 THEN 7 ELSE dayofweek(ad_date) - 1 END AS INT) AS day_of_week
,year(tv.ad_date) AS `year`
,case when month(ad_date) in (1,2,3) THEN 1 when month(ad_date) in (4,5,6) THEN 2 when month(ad_date) in (7,8,9) THEN 3 when month(ad_date) in (10,11,12) THEN 4 END AS quarter
,v.prod_id AS product_id
,v.factory_id
,v.brand_id
,tv.media_id
,from_unixtime(unix_timestamp(ad_date), 'yyyymmdd') AS ds
FROM
kudu.tv_data tv
LEFT JOIN
(
SELECT
vtv.ver_id,
p.prod_id,
p.factory_id,
p.brand_id AS brand_id
FROM
kudu_dim.v_tv vtv
LEFT JOIN
kudu_dim.product p
ON
vtv.prod_id = p.prod_id
WHERE p.valid_flag != 'X'
) v
ON
tv.sub_id = v.ver_id
WHERE tv.s_type = 1
检查SQL的执行计划
+-----------------------------------------------------------------------------------------------------------------------------------------+
| Explain String |
+-----------------------------------------------------------------------------------------------------------------------------------------+
| Max Per-Host Resource Reservation: Memory=80.00MB Threads=7 |
| Per-Host Resource Estimates: Memory=5.11GB |
| WARNING: The following tables are missing relevant table and/or column statistics. |
| kudu.tv_data, kudu_dim.product, kudu_dim.v_tv |
| |
| WRITE TO HDFS [medium_data.tv_data, OVERWRITE=false, PARTITION-KEYS=(media_id,from_unixtime(unix_timestamp(ad_date), 'yyyyMMdd'))] |
| | partitions=unavailable |
| | |
| 08:SORT |
| | order by: media_id ASC NULLS LAST, from_unixtime(unix_timestamp(ad_date), 'yyyyMMdd') ASC NULLS LAST |
| | |
| 07:EXCHANGE [HASH(tv.media_id,from_unixtime(unix_timestamp(ad_date), 'yyyyMMdd'))] |
| | |
| 04:HASH JOIN [LEFT OUTER JOIN, BROADCAST] |
| | hash predicates: tv.sub_id = vtv.ver_id |
| | |
| |--06:EXCHANGE [BROADCAST] |
| | | |
| | 03:HASH JOIN [LEFT OUTER JOIN, BROADCAST] |
| | | hash predicates: vtv.prod_id = p.prod_id |
| | | other predicates: p.valid_flag != 'X' |
| | | |
| | |--05:EXCHANGE [BROADCAST] |
| | | | |
| | | 02:SCAN KUDU [kudu_dim.product p] |
| | | predicates: p.valid_flag != 'X' |
| | | |
| | 01:SCAN KUDU [kudu_dim.v_tv vtv] |
| | |
| 00:SCAN KUDU [kudu.tv_data tv] |
| kudu predicates: tv.subj_type = 1 |
+-----------------------------------------------------------------------------------------------------------------------------------------+
分区信息
| media_id | ds | #Row | #Files | Size | Byte Cached | Cache Replication | Format | Incremental stats | Location
..................
| 1032 | 20190119 | -1 | 2 | 48.00KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190119 |
| 1032 | 20190120 | -1 | 2 | 43.99KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190120 |
| 1032 | 20190121 | -1 | 2 | 44.94KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190121 |
| 1032 | 20190122 | -1 | 2 | 42.78KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190122 |
| 1032 | 20190123 | -1 | 2 | 44.27KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190123 |
| 1032 | 20190124 | -1 | 2 | 44.39KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190124 |
| 1032 | 20190125 | -1 | 2 | 45.65KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190125 |
| 1032 | 20190126 | -1 | 2 | 45.19KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190126 |
| 1032 | 20190127 | -1 | 2 | 43.16KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190127 |
| 1032 | 20190128 | -1 | 2 | 43.96KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190128 |
| 1032 | 20190129 | -1 | 2 | 42.52KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190129 |
| 1032 | 20190130 | -1 | 2 | 43.99KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190130 |
| 1032 | 20190131 | -1 | 2 | 44.68KB | NOT CACHED | NOT CACHED | PARQUET | false | hdfs://nameservice1/user/hive/warehouse/medium_data.db/tv_data/media_id=1032/ds=20190131 |
| Total | | -1 | 38656 | 816.16MB | 0B | | | | |
+----------+----------+-------+--------+----------+--------------+-------------------+---------+-------------------+-----------------------------------------------------------------------------------------------+
Fetched 19376 row(s) in 15.49s
四、结果分析
根据Impala检测平台,整个任务执行完成约1小时20分钟,而执行最耗时的是在Sort阶段,装载扫描数据仅仅耗时几秒;分区的中文件也特别小,大约在50KB左右,总共19376个分区。
完成对一个分区COUNT的统计,需要4.77秒
完成对所有分区的COUNT统计,需要2分50秒
按媒体/天粒度,在分区目录下的文件比较小,这是业务要求;但对于分区粒度不合适,会产生大量的磁盘IO(小文件随机存放,在读取的时候会特别消耗IO),不一定能从整体上提高查询效率。如果在查询中,对分区进行了裁剪,查询还是很快的,随着分区数量的增加,响应时间会慢慢的降低。在Impala中,单表通常分区数量不要超过1万,太多的分区也会造成元数据管理的性能下降,在表元数据同步失败时,就会造成查不出数据或者看不到分区。
PS:Impala Catalog
1、表信息
2、表分区信息
3、表以及分区下的文件、Block块信息
4、表以及分区的统计信息
五、主机配置
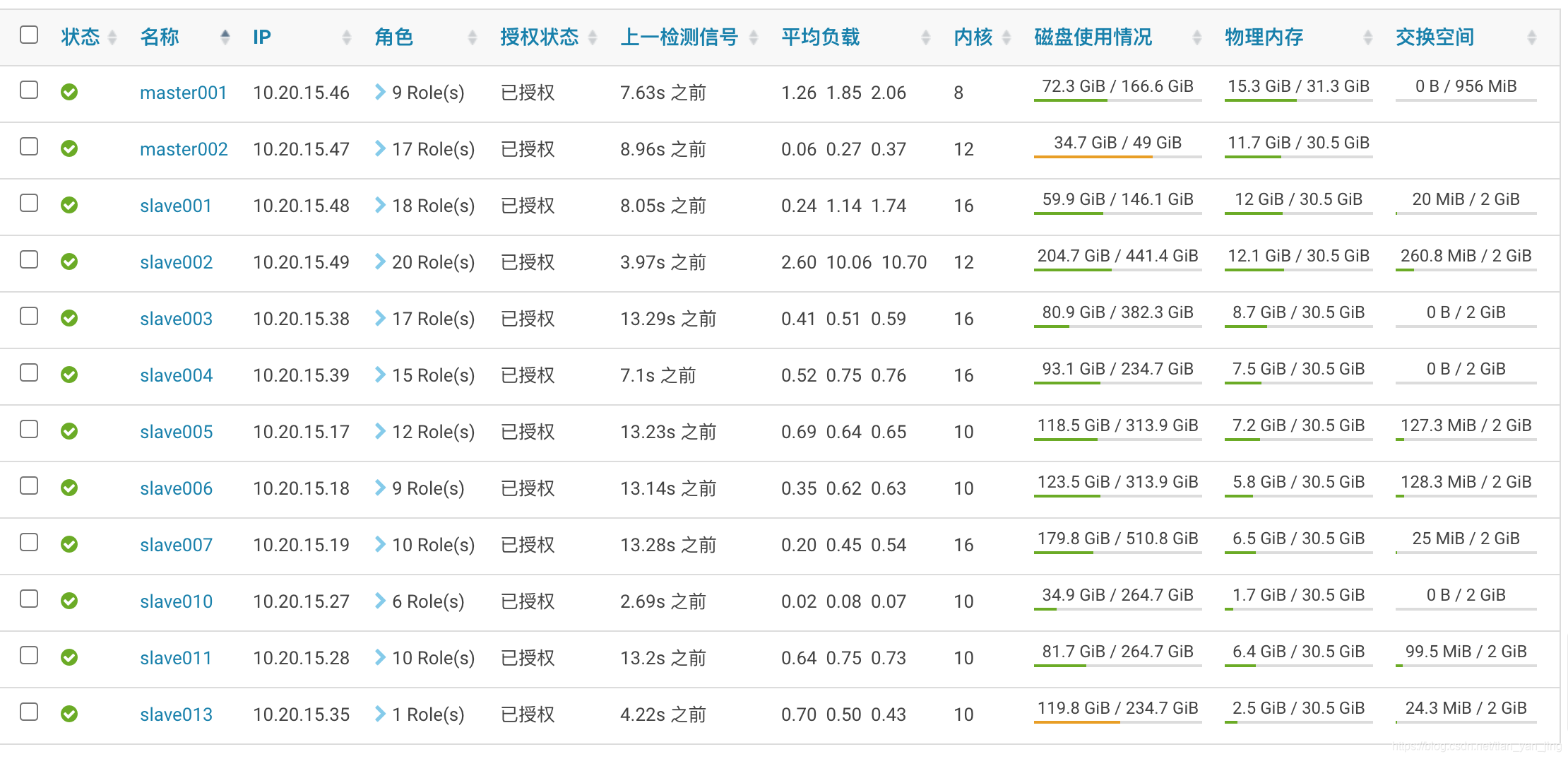
TODO:测试集群的角色规划有些乱,后续会进行角色的规划以及动态资源池、静态资源池的设置。
Impala Daemon(mem_limit)的内存设置为8G(由守护程序本身强制执行的 Impala Daemon 的内存限制(以字节为单位)。如果达到该限制,Impalad Daemon 上运行的查询可能会被停止。将其留空可以让 Impala 选择自己的限制。使用 -1 B 值将指定无任何限制)。
Impala Daemon 的 Java 堆栈大小(Impala Daemon JVM Heap)为4G(Java 进程堆栈内存的最大大小(以字节为单位),已传递到 Java -Xmx。)。
Idle Query Timeout(idle_query_timeout)设置为0(The time that a query may be idle (i.e. no processing work is done and no updates are received from the client) before it is cancelled. If 0, idle queries are never expired.)。这里需要进行修改 空闲查询:如果结果已经取出但没有关闭查询,或者结果部分取出但客户端程序不再请求更多的数据查询。这种情况一般只发生在JDBC、ODBC接口的程序中。














 3438
3438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









