









Hadoop部署的文章和介绍网上资料很丰富,涉及各个方面,所以笔者不是要详细介绍如何部署Hadoop,而是以反思为主,记录我们曾经走过的弯路和一些体会。
Hadoop部署
- 环境
机器配置 Centos6.3,CPU: E5507 2.27GHz 4Core,内存:16G,硬盘:8*500G NORAID SCSI,文件系统:XFSIP分别为:192.168.0.120/121/122/123/124/125/126/26/27/28
无DNS服务器NameNode/JobTracker:192.168.0.120DataNode/TaskTracker:192.168.0.121/122/123/124/125/126/26/27/28Apache Hadoop1.0.4(后来升级到了1.2.1)SUN JDK 1.6
Tips:对于只为hadoop使用的磁盘分区使用noatime挂载,提高性能,使用如下命令
mount -o noatime -o nodiratime -o remount /data
- 目录规划
为了简化以后升级,将Hadoop解压到一个特定的目录中,如hadoop-versions。然后通过软链接的方式将在用的hadoop版本链接到一个常用的位置,例如:
ll /usr/local/hadoop-versions/ total 8 drwxr-xr-x 15 root root 4096 Mar 26 15:25 hadoop-1.0.4 drwxr-xr-x 15 root root 4096 Mar 26 16:38 hadoop-1.2.1 ll /opt/ |grep hadoop lrwxrwxrwx 1 root root 34 Apr 11 09:30 hadoop -> /letv/hadoop-versions/hadoop-1.2.1
- 配置主机名
主机名使用FQDN的形式,确保反向DNS查找可靠准确;但是为了方便管理也需加上缩略域名,例如我的/etc/hosts
按照规划的内容来编辑所有节点的/etc/hosts。然后修改每个节点的主机名,首先使用hostname命令让主机名立即生效,如192.168.0.120 mn.dm.com mn 192.168.0.121 dn121.dm.com dn121 192.168.0.122 dn122.dm.com dn122 192.168.0.123 dn123.dm.com dn123 192.168.0.124 dn124.dm.com dn124 192.168.0.126 dn125.dm.com dn125 192.168.0.126 dn126.dm.com dn126 192.168.0.26 dn26.dm.com dn26 192.168.0.27 dn27.dm.com dn27 192.168.0.28 dn28.dm.com dn28
hostname mn.dm.com
然后为了确保服务器重启后主机名仍然有效,编辑/etc/sysconfig/network文件,修改HOSTNAME属性为对应值。
Tips:
(a)千万别忘记修改这个文件放在机器重启域名丢失;
(b)对于hadoop集群的配置管理、文件分发来说,例如修改/etc/hosts,可以使用pssh、pdsh或者mussh这些工具,如果有条件就使用Puppet这样的重器。我们目前用的是pssh,对于我们这个小集群来说已经觉得生活很惬意了。
- 配置SSH无密码登陆
在NameNode节点运行
这个命令会生成两个文件到~/.ssh/目录中:id_dsa和id_dsa.pub。把 id_dsa.pub 追加到本机授权 key 里面ssh-keygen -t dsa -f ~/.ssh/id_dsa
至此,就可以实现本机的无密码登陆,运行ssh localhost试试看吧。类似的操作,将NameNode上的这个id_dsa.pub分发到所有其它节点上,然后追加到每个节点的cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
authorized_keys里,就可以实现从NameNode到任何DateNode的ssh无密码登陆了
- 安装配置hadoop
登陆NameNode进行以下操作
安装没有什么,按照之前的目录规划解压hadoop即可。
配置hadoop不要单纯拷贝缺省配置到conf目录下,然后更改需要的属性,这样以后维护起来太麻烦了。
作为小团队来说,我们的原则是不要一上来就拷贝别人的配置文件,因为应用场景不同,环境不同,许多参数配置并不是万能的,而是只修改必要的属性。在以后的使用中很可能会由于某些属性未正确设置,造成集群出现这样或那样的问题,但是我觉得让问题暴漏出来不是什么坏事情,发现问题之后再查找相关资料进行正确的调整优化,不但保证了配置的简单性,还能让你真正的一步一步的了解hadoop。
配置的文件主要涉及conf下的hadoop-env.sh、masters、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、log4j.properties。
配置完成后使用pssh分发到其它节点,例如:
#分发hadoop安装(如果hadoop-versions已经存在,只拷贝hadoop特定版本目录即可) #hosts.txt是DataNode节点的主机名列表,详见pssh手册 pscp.pssh -h hosts.txt -r /usr/local/hadoop-versions/ /usr/local/hadoop-versions/ #创建软链接 pssh -h hosts.txt -i "ln -s /letv/hadoop-versions/hadoop-1.2.1 /opt/hadoop"
- 配置环境变量
在/etc/profile中配置必要的环境变量。如下:
JAVA_HOME=/usr/java/jdk1.6.0_43 HADOOP_HOME=/opt/hadoop HBASE_HOME=/opt/hbase-0.94.7 PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$PATH CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME export HADOOP_HOME export HBASE_HOME export PATH export CLASSPATH
- 使用Hadoop
启动集群。
HDFS的web界面:http://mn.dm.com:50070/dfshealth.jsp
MapReduce的web界面:http://mn.dm.com:50030/jobtracker.jsp
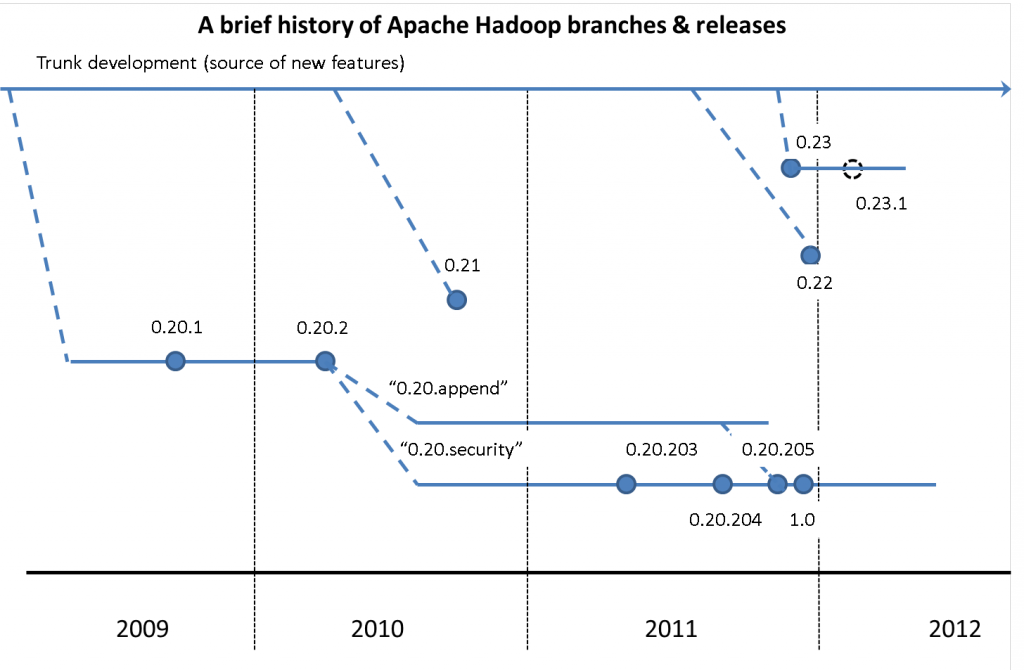
Hadoop版本历史
下图给出了Hadoop2之前的各个版本发展历史
Hadoop当前配置
这些配置仅做参考
- hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.6.0_43 export HADOOP_LOG_DIR=/mycom/logs/hadoop export HADOOP_PID_DIR=/var/hadoop/pids
- core-site.sh
<property> <name>hadoop.tmp.dir</name> <value>/data/slot1/hadoop-${user.name}</value> </property> <property> <name>fs.default.name</name> <value>hdfs://mn:9000</value> </property> <property> <name>hadoop.proxyuser.xxx.groups</name> <value>xxx</value> </property> <property> <name>hadoop.proxyuser.xxx.hosts</name> <value>dn124,dn126</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
- hdfs-site.xml
<property> <name>dfs.data.dir</name> <value>${hadoop.tmp.dir}/dfs/data,/data/slot2/hadoop-${user.name}/dfs/data,/data/slot3/hadoop-${user.name}/dfs/data,/data/slot4/hadoop-${user.name}/dfs/data,/data/slot5/hadoop-${user.name}/dfs/data,/data/slot6/hadoop-${user.name}/dfs/data</value> </property> <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> </property>
- mapred-site.xml
<property> <name>mapred.job.tracker</name> <value>mn:9001</value> </property> <property> <name>mapred.local.dir</name> <value>${hadoop.tmp.dir}/mapred/local,/data/slot2/hadoop-${user.name}/mapred/local,/data/slot3/hadoop-${user.name}/mapred/local,/data/slot4/hadoop-${user.name}/mapred/local,/data/slot5/hadoop-${user.name}/mapred/local,/data/slot6/hadoop-${user.name}/mapred/local</value> </property> <property> <name>mapred.tasktracker.map.tasks.maximum</name> <value>4</value> </property> <property> <name>mapred.tasktracker.reduce.tasks.maximum</name> <value>4</value> </property> <property> <name>mapred.child.java.opts</name> <value>-Xmx1024m</value> </property>














 2343
2343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









