





一、复习
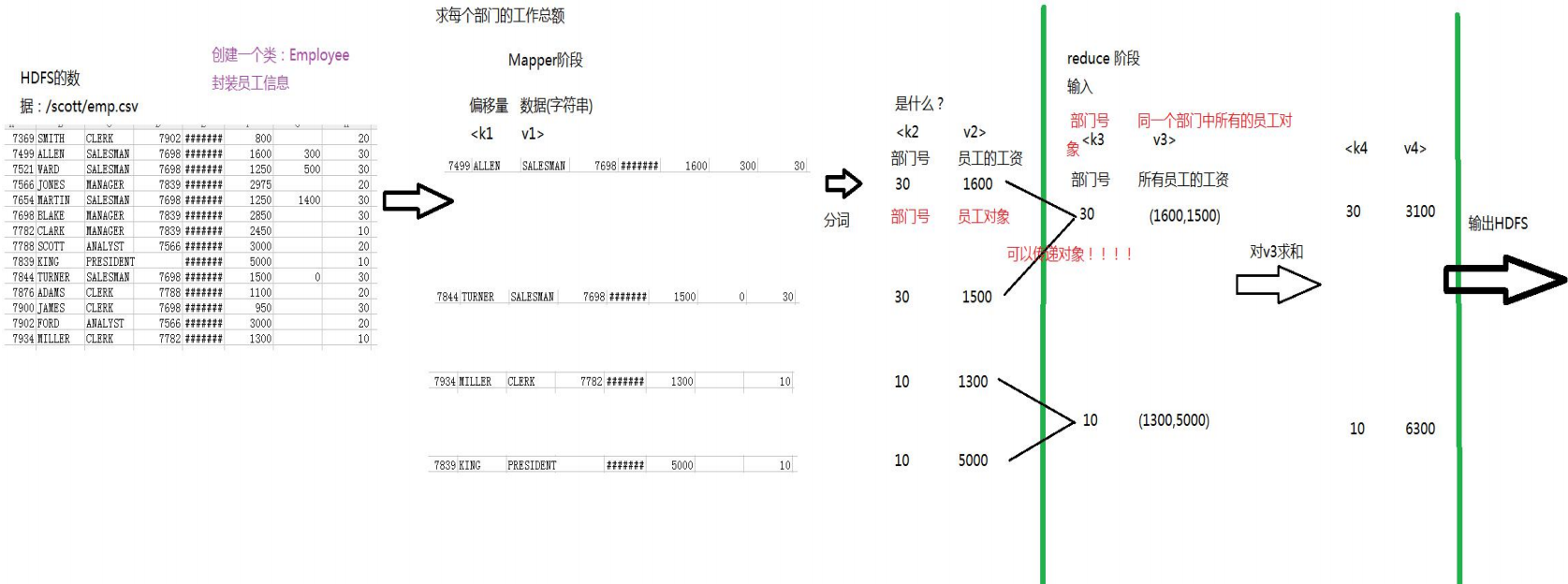
二、案例:求部门的工资总额
SQL: select deptno,sum(sal) from emp group by deptno;
在 Oracle 中 select 中,没有包含在组函数中的列,必须包含的 group by 语句的后面
三、MapReduce 高级开发
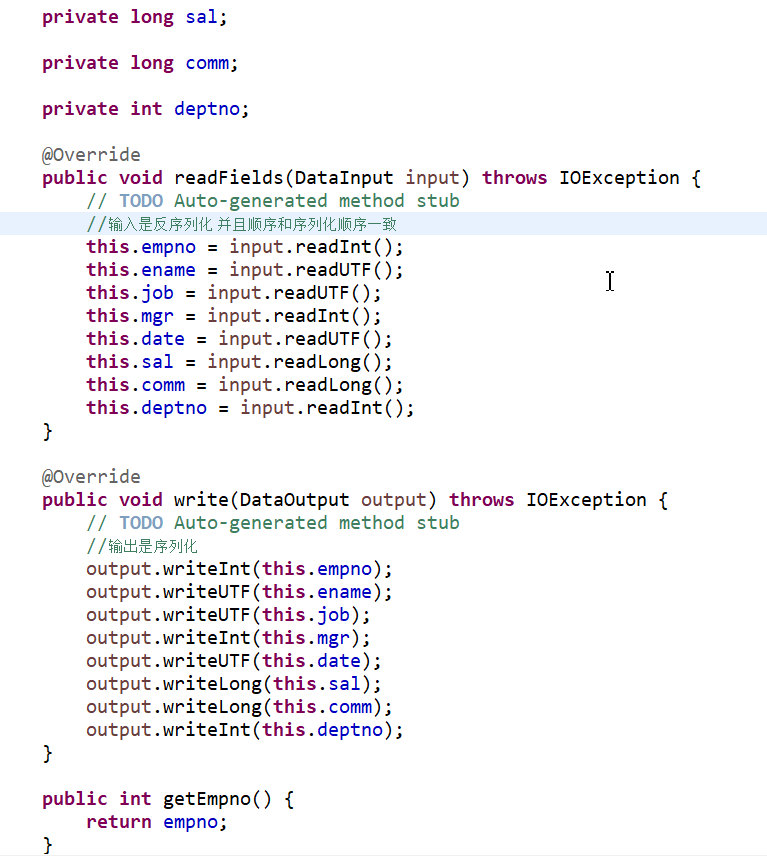
1、序列化 (*)Java 的序列化: 如果一个类实现了 Serializable 接口,该类的对象可以
作为 inputstream 和 outputstream 的对象 (*)Hadoop 的序列化:如果一个类实现了 Hadoop 的序列化接口(Writable),
********一定注意:序列化的过程一定要和反序列化的顺序一样
*******
(1)Oracle 的排序: 员工表
(*)默认升序;降序:desc
(*)order by 后面 + 列名、 表达式、 别名、列序号
表达式:按照年薪排序 select empno,ename,sal,sal*12 from emp_old order by sal*12 desc;
别名: select empno,ename,sal,sal*12 annlsal from emp_old order by annlsal desc;
列序号: select empno,ename,sal,sal*12 annlsal from emp_old order by 4 desc;
序号必须是 select 中有的列 select empno,ename,sal,sal*12 annlsal from emp_old order by 5 desc;
多个列的排序: order by 作用于后面所有的列
select * from emp_old order by deptno,sal;
desc 只作用于离他最近的列 select * from emp_old order by deptno desc,sal desc;
(2)Java 的排序
(3)MapReduce 的排序
3、分区
4、合并
四、MapReduce 的核心:Shuffle(洗牌)
二、案例:求部门的工资总额
SQL: select deptno,sum(sal) from emp group by deptno;
在 Oracle 中 select 中,没有包含在组函数中的列,必须包含的 group by 语句的后面
三、MapReduce 高级开发
1、序列化 (*)Java 的序列化: 如果一个类实现了 Serializable 接口,该类的对象可以
作为 inputstream 和 outputstream 的对象 (*)Hadoop 的序列化:如果一个类实现了 Hadoop 的序列化接口(Writable),
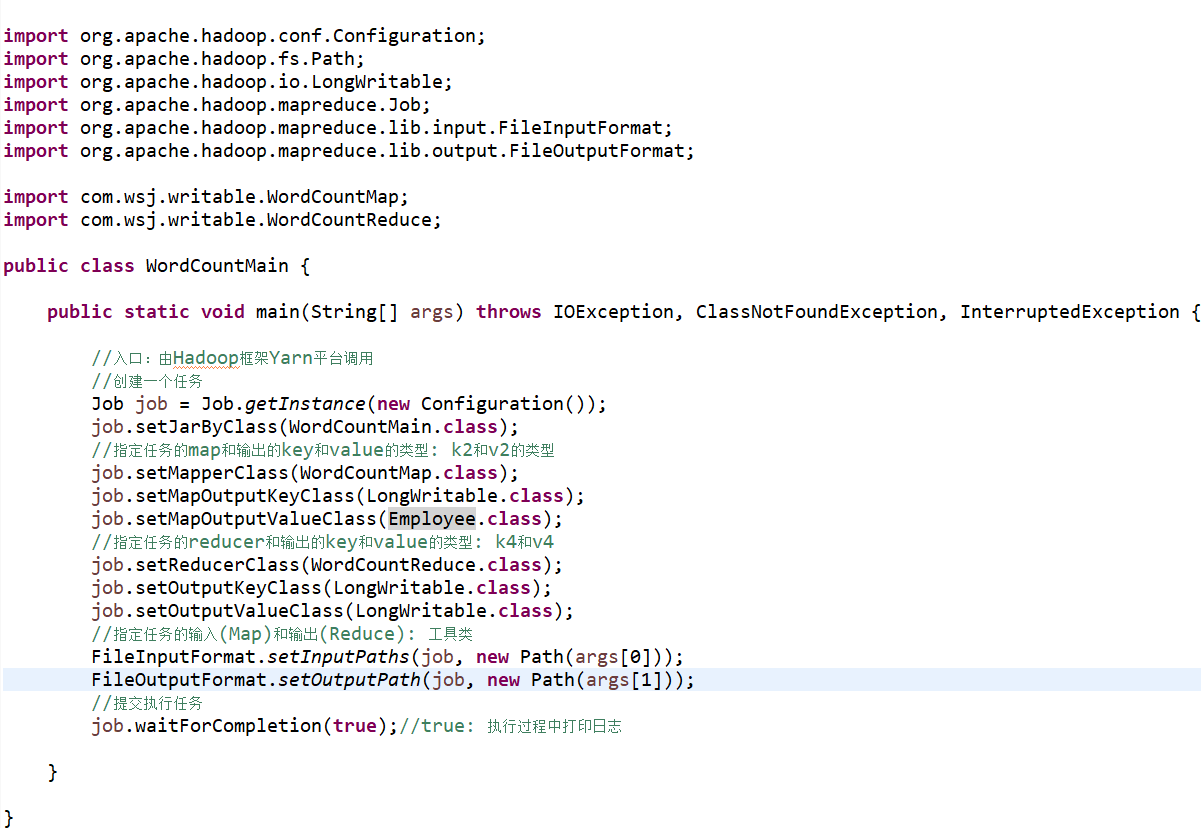
该类的对象就可以作为 Map 和 Reduce 输入和输出的对象举例:使用 Hadoop 的序列化重写:
案例:求部门的工资总额
********一定注意:序列化的过程一定要和反序列化的顺序一样
*******
代码演示
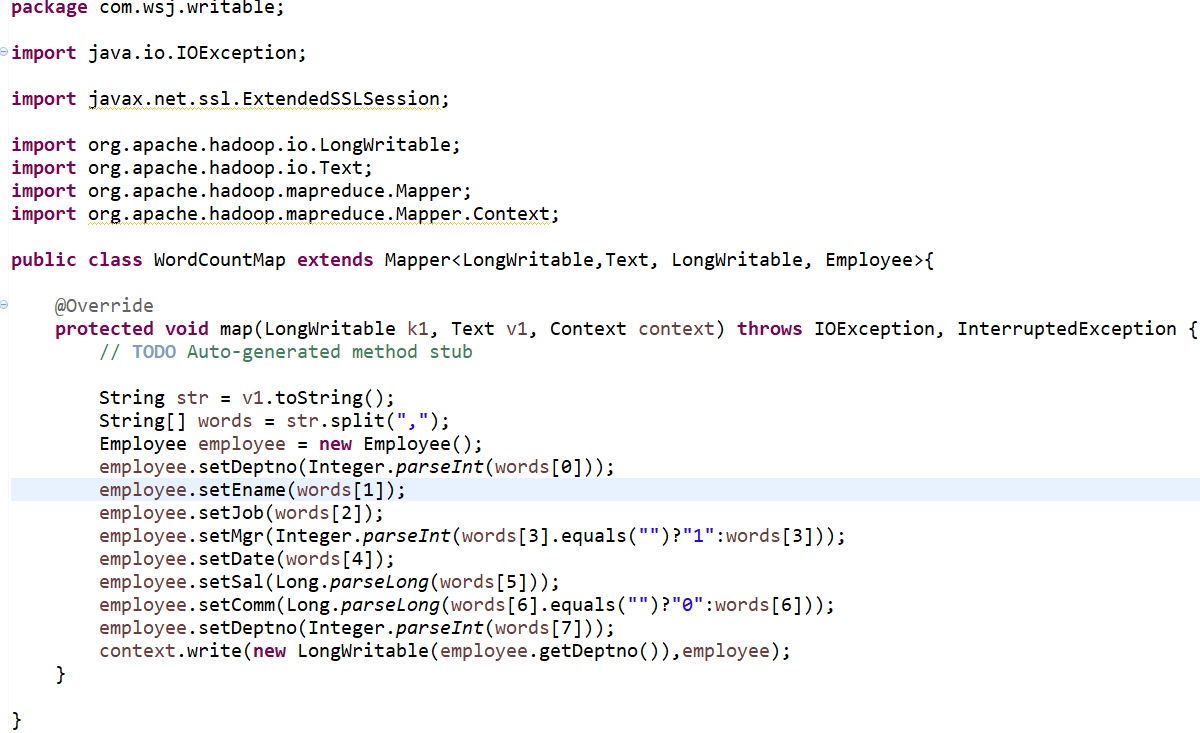
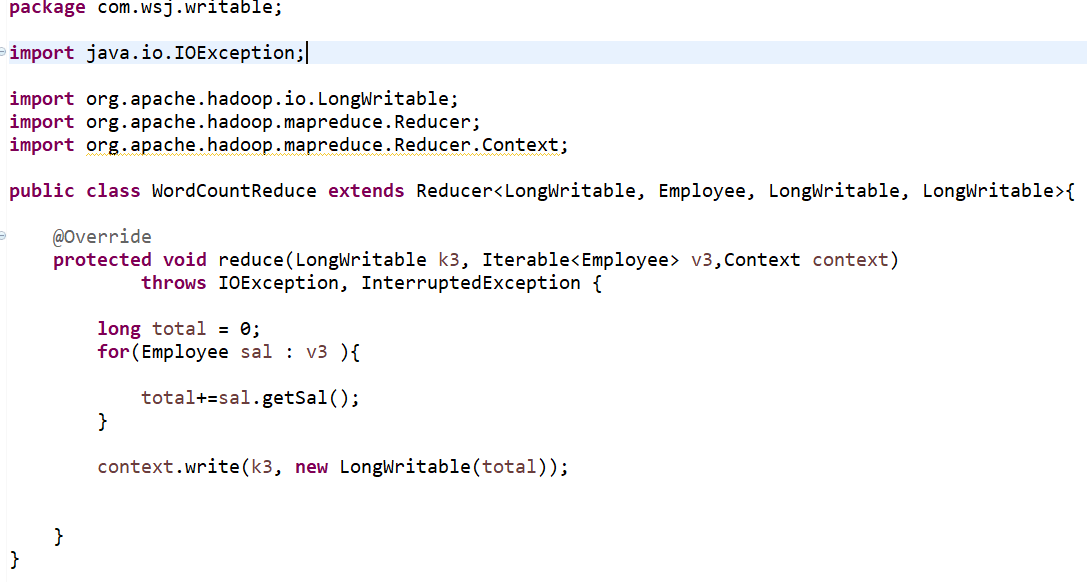
(1)Oracle 的排序: 员工表
(*)默认升序;降序:desc
(*)order by 后面 + 列名、 表达式、 别名、列序号
表达式:按照年薪排序 select empno,ename,sal,sal*12 from emp_old order by sal*12 desc;
别名: select empno,ename,sal,sal*12 annlsal from emp_old order by annlsal desc;
列序号: select empno,ename,sal,sal*12 annlsal from emp_old order by 4 desc;
序号必须是 select 中有的列 select empno,ename,sal,sal*12 annlsal from emp_old order by 5 desc;
多个列的排序: order by 作用于后面所有的列
select * from emp_old order by deptno,sal;
desc 只作用于离他最近的列 select * from emp_old order by deptno desc,sal desc;
(2)Java 的排序
(3)MapReduce 的排序
3、分区
4、合并
四、MapReduce 的核心:Shuffle(洗牌)















 2678
2678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









