








这一篇我们拿一些实例来看看。
所有的数据下载地址:https://gitee.com/tianyalei/machine_learning,按对应章节查找。
还是要提醒一句,逻辑回归很简单,很多时候效果可以,但不够优秀,可以作为BaseLine。在选择算法前,可以先观察数据,根据经验推断是否符合线性(直线、曲线、圆形、抛物线等等),只要是比较连续的,能用线隔开的,一般逻辑回归都能给出一个还算凑合的答案。
1简单逻辑回归——鸢尾花
还是去UCI去找数据,这次我们用Most Popular Data Sets 里的鸢尾花——iris.csv。
sepal length in cm,sepal width in cm,petal length in cm,petal width in cm,iris
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa就是通过一些属性来判断是哪种类型的iris。
导入iris.csv,将iris字段改为Nominal类型
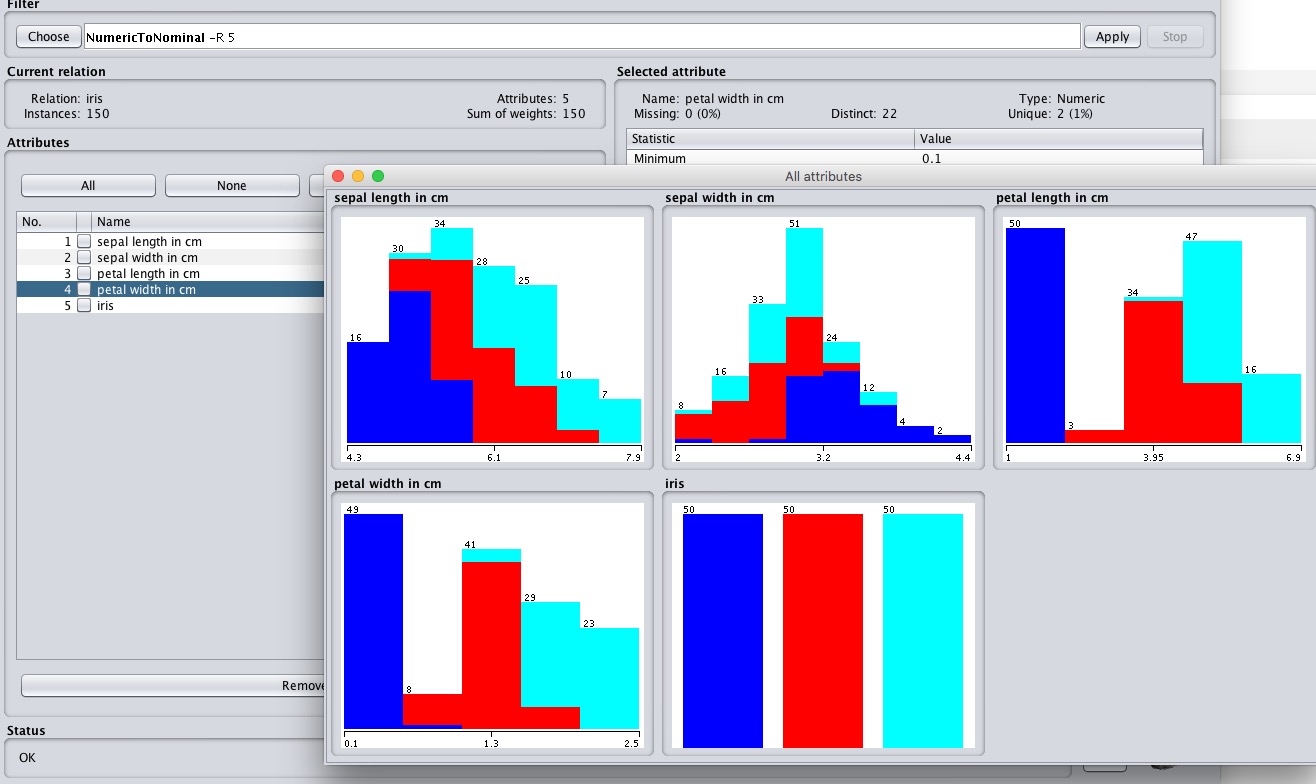
通过Visualize All我们可以简单看看各属性对于Iris的分类影响 。
好了,直接开始上算法吧。选择逻辑回归,选择交叉验证10次。
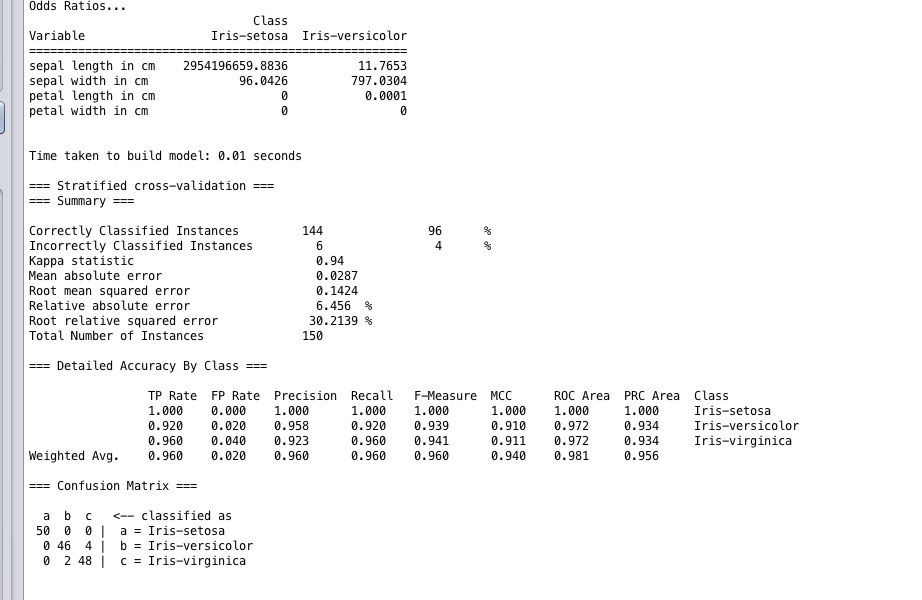
结果如图,大概96%正确率,效果OK。当然这个比较简单,当个开胃菜。
2多项式逻辑回归
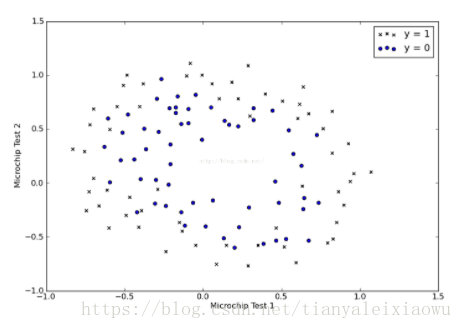
这是一个稍微复杂点的数据分布图,可以看到蓝色的点大概像一个椭圆,被黑色的*包围在里面。这种可以描述为是一个线性的,但很明显不是一次方线性的。
数据集是data2.csv
虽然明显不是一次线性方程,但我们还是先来试试。
导入数据,选择交叉验证,结果不出所料
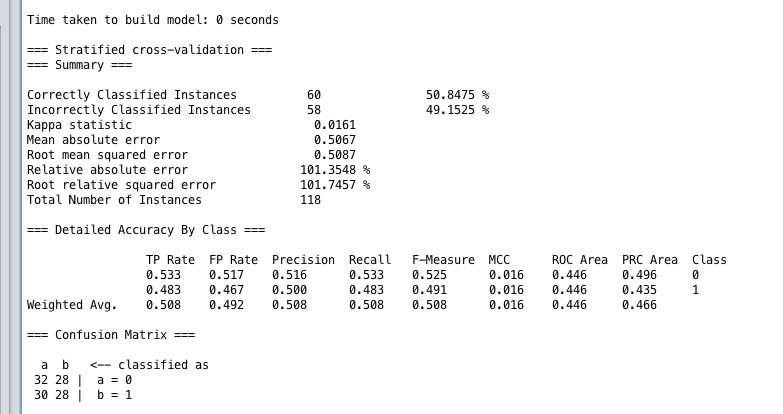
只有50%的正确率,和瞎猜没啥区别。
我们在模型上右键Visualize classifier errors,看看错误分布。
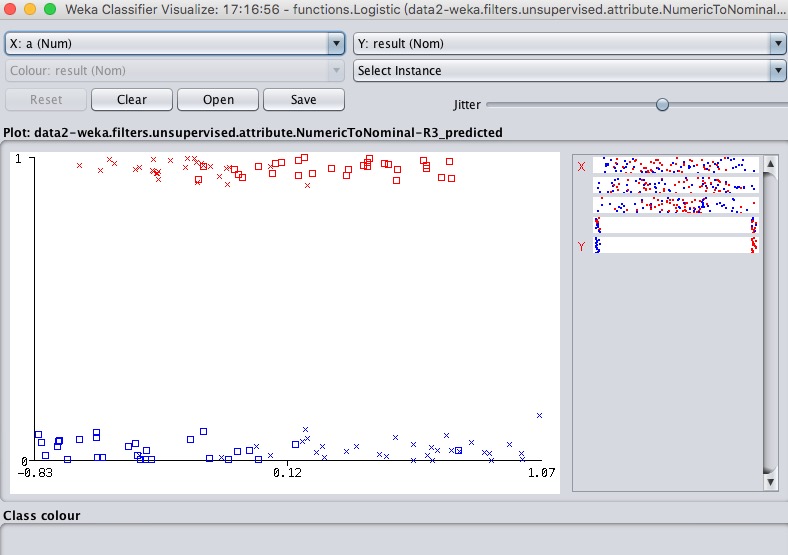
可以看到无论是0的还是1的基本都是对半错,蓝色的是左边部分全错,右边大部分对。红色的是左边大部分对,右边全错。
x代表对的,方块是错的。
这基本符合我们的猜想,因为训练集的分布是个圆,你在上面画一个线,自然是一半对一半错。
根据以往经验,我们碰到曲线就上多项式,直接加次方。经过试验,上6次方后,效果就比较美好了。

怎么加次方,可以参考之前的文章,我直接给它加到6次方,数据为data2-all.arff。
再次验证结果为:
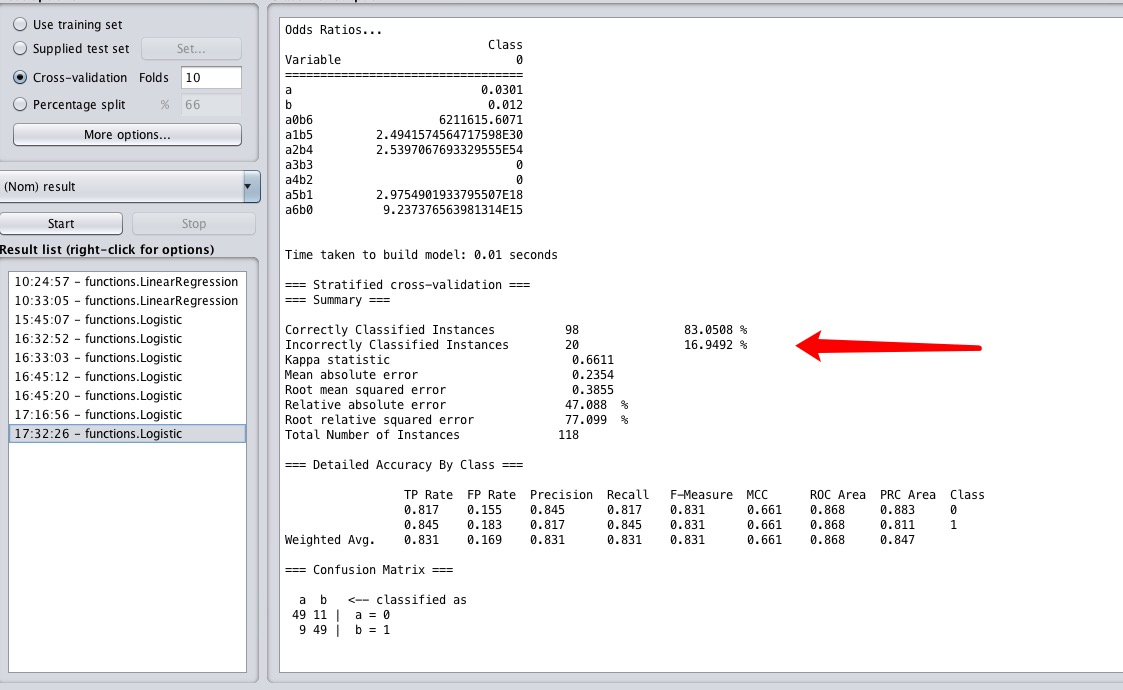
通过观察原图,我们也可以用手尝试画个圆,看看圈的数据的情况。基本上也就是错十几个点的样子。
可以看到正确率为83%,比线性提升极大,已经基本拟合了我们看到的情况。
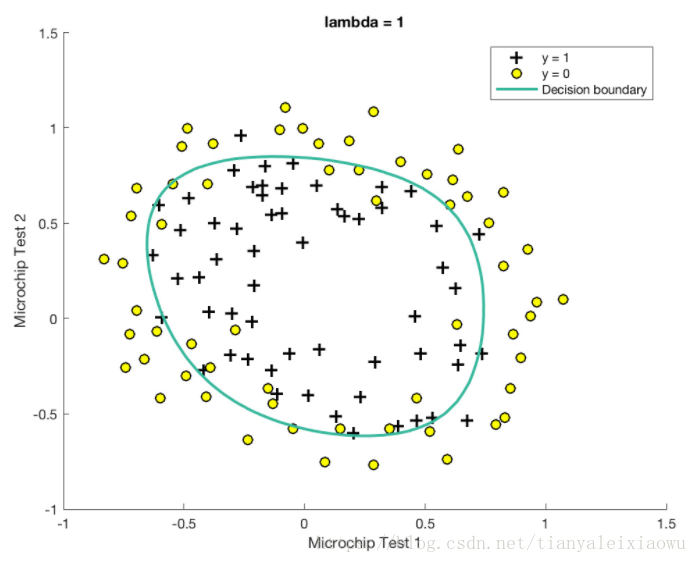
可以先来看看别人对于同一批数据做的模型,http://www.hankcs.com/ml/programming-exercise-2-logistic-regression-cs229.html
在这个网址有人给出了算法,和得到的各种结果的示例,如较好的拟合

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











