







 本文详细介绍了HDFS的读写过程。在写文件时,客户端先将数据缓存,达到block大小时请求NameNode分配block,然后直接与DataNode通信进行数据存储。读文件时,客户端首先获取block的locations,通过DFSInputStream选择最近的DataNode进行数据读取,如果出现异常则切换到其他可用节点。HDFS通过DataNode集群支持大量并发访问,适合顺序读取,不适合高并发随机读写。
本文详细介绍了HDFS的读写过程。在写文件时,客户端先将数据缓存,达到block大小时请求NameNode分配block,然后直接与DataNode通信进行数据存储。读文件时,客户端首先获取block的locations,通过DFSInputStream选择最近的DataNode进行数据读取,如果出现异常则切换到其他可用节点。HDFS通过DataNode集群支持大量并发访问,适合顺序读取,不适合高并发随机读写。
客户端:负责发起或提交读写请求, 写文件时,会拆分文件
namenode:HDFS的核心负责全局协调,做任何事都要向这里汇报,和把控所有的请求。
datanode:数量不定,负责数据的 存储。
数据存储: staging
HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时。请求NameNode分配一个block。 NameNode会把block所在的DataNode的地址告诉HDFS client。 HDFS client会直接和DataNode通信,把数据写到DataNode节点一个block文件里。拆分文件
数据存储:读文件操作
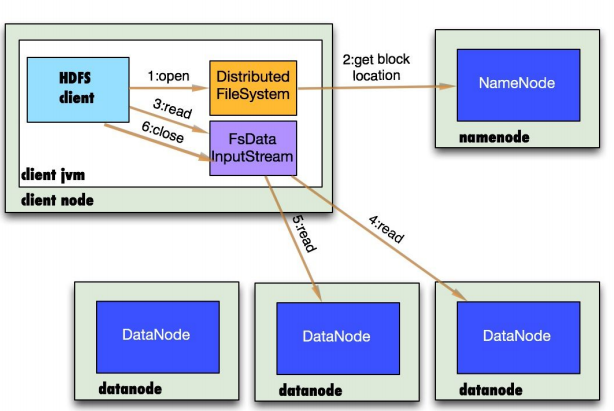
1.首先调用FileSystem对象的open方法,事实上是一个DistributedFileSystem的实例。
2.DistributedFileSystem通过rpc获得文件的第一批block的locations,同一个block依照反复数会返回多个locations,这些locations依照hadoop拓扑结构排序,距离client近的排在前面。
3.前两步会返回一个FSDataInputStream对象,该对象会被封装DFSInputStream对象,DFSInputStream能够方便的管理datanode和namenode数据流。client调用read方法。DFSInputStream最会找出离client近期的d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









