







1. 简介
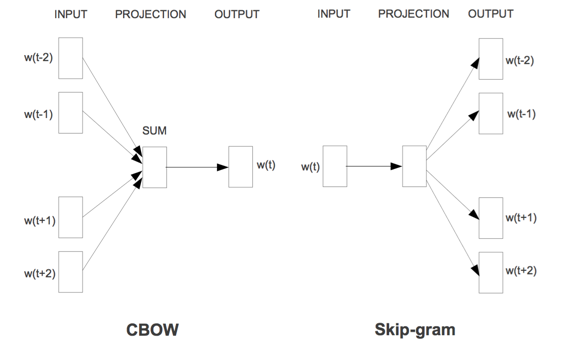
word2vec是一个3层(输入层、投影层和输出层)结构的浅层语言模型,分为CBOW和skip-gram两种模型结构。CBOW是输入上下文来预测当前词语,而skip-gram是输入当前词语来预测上下文。其模型结构如下图所示
而基于这两种模型结构,word2vec作者又提出了两种改进方法,用来提升模型训练速度,因此,word2vec可细分为四种模型:
1). 基于Hierarchical Softmax的CBOW模型
2). 基于Hierarchical Softmax的skip-Gram模型
3). 基于Negative Sampling的CBOW模型
4). 基于Negative Sampling的skip-Gram模型
2. 训练过程
下面以基于Hierarchical Softmax的CBOW模型来简要说明word2vec模型的训练过程:
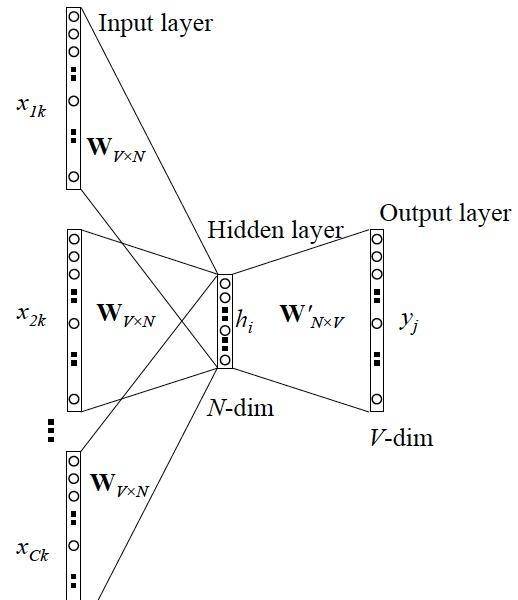
1)假设词表大小为V,上下文单词个数为C,则输入是一个C*V的one-hot向量组成的矩阵;
2)然后乘以输入层到投影层的权重矩阵W(V*N矩阵,N为自定义维度,也就是最终训练出来的词向量的维度),得到一个C*N的矩阵;
3)然后在投影层求和平均,得到一个1*N的向量表示,然后乘以输出权重矩阵W’(N*V矩阵),得到一个1*V的向量表示,如果是采用简单的softmax输出层,则直接是得到V个词语的概率分布,即可得到我们的输出,也即当前词语。
然而当词表大小V很大时,直接计算softmax计算量会很大,因此word2vec对输出层进行优化,采用层次softmax和负采样两种方式来减少计算量。
层次softmax核心是一颗Huffman树,Huffman树的特点是,出现频次较高的词语采用较短的编码,反之,采用较长编码。该Huffman树的叶子节点代表词表中每个单词,根节点是输出层的输入也即一个1*V的向量表示,然后通过Huffman树层层二分类来得到每个单词的概率。概率最大的单词为预测出的中间词(target word)与true label的onehot做比较,误差越小越好(根据误差更新权重矩阵)
训练过程中一般采用交叉熵作为损失函数(loss function),采用梯度下降算法更新权重矩阵W和W’。
训练完毕后,输入层每个单词的one-hot向量与权重矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)就是我们所需要的词向量矩阵。
3. word2vec的tensorflow实现
tensorflow提供了word2vec的NCE损失函数的实现,因此基于该损失函数可以很方便实现基于Negative Sampling的word2vec模型。
下面代码是skip-gram(输入当前词语来预测上下文)的实现
疑问???:该实现是将当前词和词窗内每个词语作为一组输入输出(共W组,W为词窗大小),是否可以将词窗内所有词语做个加权平均然后跟当前词作为一组输入输出(共1组)???
def iter_batch(self, sentences, batch_size, shuffle=True):
if shuffle:
random.shuffle(sentences)
batch_inputs, batch_labels = [], []
for k, sentence in enumerate(sentences):
for i in range(len(sentence)):
start = max(0, i - self.window)
end = min(len(sentence), i + self.window + 1)
for idx in range(start, end):
if idx == i:
continue
else:
input_id = self.word2id.get(sentence[i])
label_id = self.word2id.get(sentence[idx])
if not (input_id and label_id):
continue
batch_inputs.append(input_id)
batch_labels.append(label_id)
if len(batch_inputs) >= batch_size:
yield batch_inputs, batch_labels
利用tensorflow提供的tf.nn.nce_loss函数,实现word2vec模型,其整体模型结构如下,完整示例代码可参考Github源码
class TFWord2Vec(object):
def __init__(self,
vocab_size,
embedding_size,
num_sampled,
lr):
self.train_inputs = tf.placeholder(tf.int32, shape=[None], name='train_inputs')
self.train_labels = tf.placeholder(tf.int32, shape=[None, 1], name='train_labels')
self.embedding_dict = tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0)
)
with tf.name_scope('loss'):
self.nce_weight = tf.Variable(tf.truncated_normal([vocab_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
self.nce_biases = tf.Variable(tf.zeros([vocab_size]))
# 将输入序列向量化
embed = tf.nn.embedding_lookup(self.embedding_dict, self.train_inputs) # batch_size
# 得到NCE损失
self.loss = tf.reduce_mean(
tf.nn.nce_loss(
weights=self.nce_weight,
biases=self.nce_biases,
labels=self.train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocab_size
)
)
tf.summary.scalar('loss', self.loss) # 让tensorflow记录参数
self.global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(lr)
grads_and_vars = optimizer.compute_gradients(self.loss)
self.train_op = optimizer.apply_gradients(grads_and_vars, global_step=self.global_step)
4. word2vec与bert
word2vec中的CBOW模型,它的核心思想是:在做语言模型任务的时候,我把要预测的单词抠掉,然后根据它的上文Context-Before和下文Context-after去预测该单词。
在Bert模型预训练过程中Mask LM思想跟CBOW模型思想类型,作者在论文中说是受到完形填空的启发,同时肯定也是考虑到CBOW模型思想了的。与CBOW模型不同的是,Bert在MaskLM阶段是随机遮掩/替换句子中15%的词语,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









