









弹性数据集RDDs
RDD是Spark最基本的数据抽象,具有以下特性:
一个RDD有一个或多个分区(partitions)组成,每个partition会被一个计算任务所处理。用户可以在创建RDD时指定其分区个数,没指定则默认采用程序所分配到的cpu核心数
宽窄依赖:RDD和它的父RDDs之间的依赖关系分为两种不同的类型:
- narrow dependency:父RDDs的一个分区最多被子RDDs一个分区所依赖
- wide dependency:父RDDs的一个分区可以被子RDDs的多个子分区所依赖

区分这两种依赖是很有用的:
- 窄依赖允许一个集群节点以流水线的方式对父分区数据进行计算,例如先执行map操作,然后执行filter操作。而宽依赖需要计算好所有父分区的数据,然后再在节点之间进行shuffle,这与MapReduce类似。
- 窄依赖能更有效地进行数据恢复,因为只需重新对丢失分区的父分区进行计算,且不同节点之间可以并行计算;而对于宽依赖而言,如果数据丢失,则需要对所有父分区数据进行计算并再次shuffle。
生成DAG
Spark根据依赖关系的不同将DAG划分为不同的stage:
- 对于窄依赖,由于分区的依赖关系是确定的,其转换操作可以在同一个线程执行,所以可以划分到同一个执行阶段
- 对于宽依赖,由于shuffle存在,只能在父RDDs被shuffle处理完成后,才能开始接下来的计算,因此遇到宽依赖就需要重新划分阶段
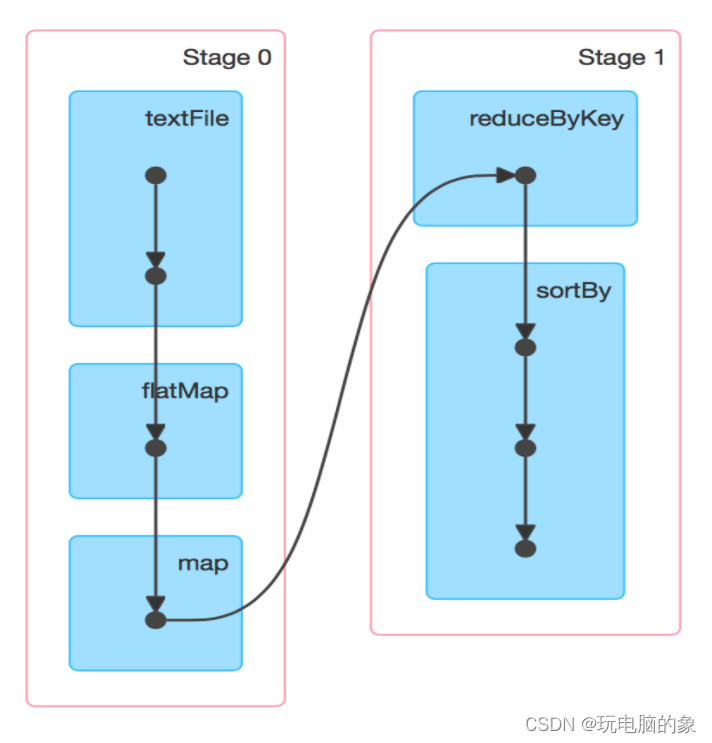
ps:Spark中产生宽窄依赖的依据是shuffle,当发生shuffle时,会产生宽依赖,基本上shuffle算子都会产生宽依赖,但是join除外,在执行join算子之前如果先执行groupByKey,执行groupByKey之后,会把相同的key分到同一个分区,再执行join算子,join算子是把key相同的进行join(只是对于k v形式的数据可以使用),不一定会产生shuffle ,有可能发生shuffle,也有可能不发生
常用的产生shuffle的算子:
distinct
聚合
reduceByKey
groupBy
groupByKey
aggregateByKey
combineByKey
排序
sortByKey
sortBy
重分区
coalesce
repartition
集合或者表操作
intersection
join
leftOuterJoin...................














 3223
3223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









