






本文作者是来自 TiBoys 队的崔秋同学,他们的项目 TBSSQL 在 TiDB Hackathon 2018 中获得了一等奖。
TiDB Batch and Streaming SQL(简称 TBSSQL)扩展了 TiDB 的 SQL 引擎,支持用户以类似 StreamSQL 的语法将 Kafka、Pulsar 等外部数据源以流式表的方式接入 TiDB。通过简单的 SQL 语句,用户可以实现对流式数据的过滤,流式表与普通表的 Join(比如流式事实表与多个普通维度表),甚至通过 CREATE TABLE AS SELECT 语法将处理过的流式数据写入普通表中。此外,针对流式数据的时间属性,我们实现了基于时间窗口的聚合/排序算子,使得我们可以对流式数据进行时间维度的聚合/排序。
序
算起来这应该是第三次参加的 Hackathon 了,第一次参加的时候还是在小西天的豌豆荚,和东旭一起,做跨平台数据传输的工具,两天一夜;第二次和奇叔一起在 3W 咖啡,又是两天一夜;这次在自己家举办 Hackathon 比赛,下定决心一定要佛性一些,本着能抱大腿就不单干的心态,迅速决定拉唐长老(唐刘)下水。接下来就计划着折腾点啥,因为我们两个前端都不怎么样,所以只能硬核一些,于是拍了两个方案。
方案一:之前跟唐长老合作过很长一段时间,我们两个对于测试质量之类的事情也都非常关注,所以想着能不能在 Chaos 系统上做一些文章,把一些前沿的测试理论和经验方法结合到系统里面来,做一套通用的分布式系统测试框架,就像 Jepsen 那样,用这套系统去测试和验证主流的开源分布式项目。
方案二:越接近于业务实时性的数据处理越有价值,不管是 Kafka/KSQL,Flink/Spark Streaming 都是在向着实时流计算领域方向进行未来的探索。TiDB 虽然已经能够支持类 Real Time OLAP 的场景,但是对于更实时的流式数据处理方面还没有合适的解决方案,不过 TiDB 具有非常好的 Scale 能力,天然的能存储海量的数据库表数据,所以在 Streaming Event 和 Table 关联的场景下具有非常明显的优势。如果在 TiDB 上能够实现一个 Streaming SQL 的引擎,实现 Batch/Streaming 的计算融合,那将会是一件非常有意思的事情。
因为打 Hackathon 比赛主要是希望折腾一些新的东西,所以我们两个简单讨论完了之后还是倾向于方案二,当然做不做的出来另说。
当我们正准备做前期调研和设计的时候,Hackathon 主办方把唐长老拉去做现场导师,参赛规则规定导师不能下场比赛,囧,于是就这样被被动放了鸽子。好在后来遇到了同样被霸哥(韩飞)当导师而放鸽子的川总(杜川),川总对于 Streaming SQL 非常感兴趣,于是难兄难弟一拍即合,迅速决定抱团取暖。随后,Robot 又介绍了同样还没有组队的社区小伙伴 GZY(高志远),这样算是凑齐了三个人,但是一想到没有前端肯定搞不定,于是就拜托娘家人(Dashbase)的交际小王子 WPH(王鹏翰)出马,帮助去召唤一个靠谱的前端小伙伴,后来交际未果直接把自己卖进了队伍,这样终于凑齐了四后端,不,应该是三后端 + 一伪前端的组合。
因为马上要准备提交项目和团队名称,大家都一致觉得方案二非常有意思,所以就选定了更加儒雅的 TBSSQL(TiDB Batch and Streaming SQL)作为项目名称,TSBSQL 遗憾落选。在团队名称方面,打酱油老男孩 / Scboy / TiStream / 养生 Hackathon / 佛系 Hackathon 都因为不够符合气质被遗憾淘汰,最后代表更有青春气息的 TiBoys 入选(跟着我左手右手一个慢动作,逃……
前期准备
所谓 “三军未动, 粮草先行”,既然已经报名了,还是要稍作准备,虽然已经确定了大的方向,但是具体的落地方案还没有细化,而且人员的分工也不是太明确。又经过一轮简单的讨论之后,明确了大家的职责方向,我这边主要负责项目整体设计,进度管理以及和 TiDB 核心相关的代码,川总主要负责 TiDB 核心技术攻关,GZY 负责流数据源数据的采集部分,WPH 负责前端展现以及 Hackathon 当天的 Demo 演示,分工之后大家就开始分头调研动工。
作为这两年来基本没怎么写过代码的退役型选手来说,心里还是非常没底的,也不知道现在 TiDB 代码结构和细节变成什么样了,不求有功,但求别太拖后腿。
对于项目本身的典型应用场景,大家还是比较明确的,觉得这个方向是非常有意义的。
-
应用层系统:实时流事件和离线数据的关联查询,比如在线广告推荐系统,在线推荐系统,在线搜索,以及实时反欺诈系统等。
-
内部数据系统:
- 实时数据采样统计,比如内部监控系统;
- 时间窗口数据分析系统,比如实时的数据流数据分析(分析一段时间内异常的数据流量和系统指标),用于辅助做 AI Ops 相关的事情(比如根据数据流量做节点自动扩容/自动提供参数调优/异常流量和风险报告等等)。
业界 Streaming 相关的系统很多,前期我这边快速地看了下能不能站在巨人的肩膀上做事情,有没有可借鉴或者可借用的开源项目。
-
Apache Beam
本质上 Apache Beam 还是一个批处理和流处理融合的 SDK Model,用户可以在应用层使用更简单通用的函数接口实现业务的处理,如果使用 Beam 的话,还需要实现自定义的 Runner,因为 TiDB 本身主要的架构设计非常偏重于数据库方向,内部并没有特别明确的通用型计算引擎,所以现阶段基本上没有太大的可行性。当然也可以选择用 Flink 作为 Runner 连接 TiDB 数据源,但是这就变成了 Flink&TiDB 的事情了,和 Beam 本身关系其实就不大了。
-
Apache Flink / Spark Streaming
Flink 是一个典型的流处理系统,批处理可以用流处理来模拟出来。
本身 Flink 也是支持 SQL 的,但是是一种嵌入式 SQL,也就是 SQL 和应用程序代码写在一起,这种做法的好处是可以直接和应用层进行整合,但是不好的地方在于,接口不是太清晰,有业务侵入性。阿里内部有一个增强版的 Flink 项目叫 Blink,在这个领域比较活跃。如果要实现批处理和流处理融合的话,需要内部定制和修改 Flink 的代码,把 TiDB 作为数据源对接起来,还有可能需要把一些环境信息提交给 TiDB 以便得到更好的查询结果,当然或许像 TiSpark 那样,直接 Flink 对接 TiKV 的数据源应该也是可以的。因为本身团队对于 Scala/Java 代码不是很熟悉,而且 Flink 的模式会有一定的侵入性,所以就没有在这方面进行更多的探索。同理,没有选择 Spark Streaming 也是类似的原因。当然有兴趣的小伙伴可以尝试下这个方向,也是非常有意思的。
-
Kafka SQL
因为 Kafka 本身只是一个 MQ,以后会向着流处理方向演进,但是目前并没有实现批处理和流处理统一的潜力,所以更多的我们只是借鉴 Kafka SQL 的语法。目前 Streaming SQL 还没有一个统一的标准 SQL,Kafka SQL 也只是一个 SQL 方言,支持的语法还比较简单,但是非常实用,而且是偏交互式的,没有业务侵入性。非常适合在 Hackathon 上做 Demo 演示,我们在项目实现中也是主要参考了 Kafka SQL 的定义,当然,Flink 和 Calcite 也有自己定义的 Streaming 语法,这里就不再讨论了。
调研准备工作讨论到这里基本上也就差不多了,于是我们开始各自备(hua)战(shui),出差的出差,加班的加班,接客户的接客户,学 Golang 的学 Golang,在这种紧(fang)张(fei)无(zi)比(wo)的节奏中,迎来了 Hackathon 比赛的到来。
Hackathon 流水账
具体的技术实现方面都是比较硬核的东西,细节也比较多,扔在最后面写,免的大家看到一半就点×了。
至于参加 Hackathon 的感受,因为不像龙哥那么文豪,也不像马老师那么俏皮,而且本来读书也不多,所以也只能喊一句“黑客马拉松真是太好玩了”!
Day 1
3:30 AM
由于飞机晚点,川总这个点儿才辗转到酒店。睡觉之前非常担心一觉睡过头,让这趟 Hackathon 之旅还没开始就结束了,没想到躺下以后满脑子都是技术细节,怎么都睡不着。漫漫长夜,无眠。
7:45 AM
川总早早来到 Hackathon 现场。由于来太早,其他选手都还没到,所以他提前刺探刺探敌情的计划也泡汤了,只好在赛场瞎晃悠一番熟悉熟悉环境,顺道跟大奖合了个影。

11:00 AM
简单的开幕式之后,Hackathon 正式开始。我们首先搞定的是 Streaming SQL 的语法定义以及 Parser 相关改动。这一部分在之前就经过比较详细的在线讨论了,所以现场只需要根据碰头后统一的想法一顿敲敲敲就搞定了。快速搞定这一块以后,我们就有了 SQL 语法层面的 Streaming 实现。当然此时 Streaming 也仅限于语法层面,Streaming 在 SQL 引擎层面对应的其实还是普通的TiDB Table。
接下来是 DDL 部分。这一块我们已经想好了要复用 TiDB Table 的 Meta 结构 TableInfo ,因此主要工作就是按照 DDL源码解析 依葫芦画瓢,难度也不大,以至于我们还有闲心纠结一下 SHOW TABLES 语法里到底要不要屏蔽掉 Streaming Table 的问题。
整体上来看上午的热身活动还是进行的比较顺利的,起码 Streaming DDL 这块没有成为太大的问题。这里面有个插曲就是我在 Hackathon 之前下载编译 TiDB,结果发现 TiDB 的 parser 已经用上时髦的 go module 了(也是好久好久没看 TiDB 代码),折腾好半天,不过好处就是 Hackathon 当天的时候改起来 parser 就比较轻车熟路了,所以赛前编译一个 TiDB 还是非常有必要的。
15:30 PM
随着热身的结束,马上迎来了稳定的敲敲敲阶段。川总简单弄了一个 Mock 的 StreamReader 然后丢给了我,因为我之前写 TiDB 的时候,时代比较遥远,那时候都还在用周 sir 的 Datum,现在一看,为了提高内存效率和性能,已经换成了高大上的 Chunk,于是一个很常见的问题:如何用最正确的做法把一个传过来的 Json 数据格式化成 Table Row 数据放到 Chunk 里面,让彻底我懵逼了。
这里面倒不是技术的问题,主要是类型太多,如果枚举所有类型,搞起来很麻烦,按道理应该有更轻快的办法,但是翻了源代码还是没找到解决方案。这个时候果断去求助现场导师,也顺便去赛场溜(ci)达(tan)一(di)圈(qing)。随便扫了一眼,惊呆了,龙哥他们竟然已经开始写 PPT 了,之前知道龙哥他们强,但是没想到强到这个地步,还让不让大家一块欢快地玩耍了。同时,也了解到了不少非常有意思的项目,比如用机器学习方法去自动调节 TiDB 的调度参数,用 Lua 给 TiKV 添加 UDF 之类的,在 TiDB 上面实现异构数据库的关联查询(简直就是 F1 的大一统,而且听小道消息,他们都已经把 Join 推到 PG 上面去了,然而我们还没开始进入到核心开发流程),在 TiKV 上面实现时序数据库和 Memcached 协议等等,甚至东旭都按捺不住自己 Hackathon 起来了(嘻嘻,可以学学我啊 ;D )。
本来还想去聊聊各个项目的具体实现方案,但是一想到自己挖了一堆坑还没填,只能默默回去膜拜 TiNiuB 项目。看起来不能太佛系了,于是乎我赶紧召开了一次内部团队 sync 的 catch up,明确下分工,川总开始死磕 TBSSQL 的核心逻辑 Streaming Aggregation 的实现,我这边继续搞不带 Aggregation 的 Streaming SQL 的其他实现,GZY 已经部署起来了 Pulsar,开始准备 Mock 数据,WPH 辅助 GZY 同时也快速理解我们的 Demo 场景,着手设计实现前端展现。
18:00 PM
我这边和面带慈父般欣慰笑容的老师(张建)进行了一些技术方案实现上的交流后,了解到目前社区小伙伴已经在搞 CREATE TABLE AS SELECT 的重要信息(后续证明此信息值大概一千块 RMB)。
此时,在解决了之前的问题之后,TBSSQL 终于能跑通简单的 SELECT 语句了。我们心里稍微有点底了,于是一鼓作气,顺路也实现了带 Where 条件的 Stream Table 的 SELECT,以及 Stream Table 和 TiDB Table 的多表 Join,到这里,此时,按照分工,我这边的主体工作除了 Streaming Position 的持久化支持以外,已经写的差不多了,剩下就是去实现一些 Nice to have 的 DDL 的语法支持。川总这里首先要搞的是基于时间窗口的 Streaming Aggregation。按照我们的如意算盘,这里基本上可以复用 TiDB 现有的 Hash Aggregation 的计算逻辑,只需要加上窗口的处理就完事儿了。
不过实际下手的时候仔细一研究代码,发现 Aggregation 这一块代码在川总疏于研究这一段时间已经被重构了一把,加上了一个并发执行的分支,看起来还挺复杂。于是一不做二不休,川总把 Hash Aggregation 的代码拷了一份,删除了并发执行的逻辑,在比较简单的非并发分支加上窗口相关实现。不过这种方法意味着带时间窗口的 Aggregation 得单独出 Plan,Planner 上又得改一大圈。这一块弄完以后,还没来得及调试,就到吃晚饭的点儿了。
21:00 PM
吃完晚饭,因为下午死磕的比较厉害,我和张建、川总出门去园区溜达了一圈。期间张建问我们搞得咋样了,我望了一眼川总,语重心长地说主要成败已经不在我了(后续证明这句语重心长至少也得值一千块 RMB),川总果断信心满满地说问题不大,一切尽在掌握之中。
没想到这个 Flag 刚立起来还是温的,就立马被打脸了。问题出在吃饭前搞的聚合那块(具体细节可以看下后面的坑系列),为了支持时间窗口,我们必须确保 Streaming 上的窗口列能透传到聚合算子当中,为此我们屏蔽了优化器中窗口聚合上的列裁剪规则。可是实际运行当中,我们的修改并没有生效???而此时,川总昨天一整晚没睡觉的副作用开始显现出来了,思路已经有点不太清醒了。于是我们把张建拖过来一起 debug。然后我这边也把用 TiDB Global Variable 控制 Streaming Position 的功能实现了,并且和 GZY 这边也实现了 Mock 数据。
之后,我也顺路休息休息,毕竟川总这边搞不定,我们这边搞的再好也没啥用。除了观摩川总和张建手把手,不,肩并肩结对小黑屋编程之外,我也顺便申请了部署 Kafka 联调的机器。
23:00 PM
我们这边最核心的功能还没突破,亮眼的 CREATE TABLE AS SELECT Streaming 也还没影,其实中期进度还是偏慢了(或者说之前我设计实现的功能的工作量太大了,看起来今天晚上只能死磕了,囧)。我调试 Kafka 死活调不通,端口可以 Telnet 登陆,但是写入和获取数据的时候一直报超时错误,而且我这边已经开始困上来了,有点扛不动了,后来在 Kafka 老司机 WPH 一起看了下配置参数,才发现 Advertise URL 设置成了本地地址,换成对外的 IP 就好了,当然为了简单方便,我们设置了单 Partition 的 Topic,这样 collector 的 Kafka 部分就搞的差不多了,剩下就是实现一个 http 的 restful api 来提供给 TiDB 的 StreamReader 读取,整个连通工作就差不多了。
Day 2
00:00 AM
这时候川总那边也传来了好消息,终于从 Streaming Aggregation 这个大坑里面爬出来了,后面也比较顺利地搞定了时间窗口上的聚合这块。此时时间已经到了 Hackathon 的第二天,不少其他项目的小伙伴已经收摊回家了。不过我们抱着能多做一个 Feature 是一个的心态,决定挑灯夜战。首先,川总把 Sort Executor 改了一把以支持时间窗口,可能刚刚的踩坑经历为我们攒了人品,Sort 上的改动竟然一次 AC 了。借着这股劲儿,我们又回头优化了一把 SHOW CREATE STREAM 的输出。
这里有个插曲就是为了近距离再回味和感受下之前的开发流程,我们特意在 TiDB 的 repo 里面开了一个 tiboys/hackathon 的分支,然后提交的时候用了标准的 Pull Request 的方式,点赞了才能 merge(后来想想打 Hackathon 不是太可取,没什么用,还挺耽误时间,不知道当时怎么想的),所以在 master 分支和 tiboys/hackathon 分支看的时候都没有任何提交记录。嘻嘻,估计龙哥也没仔细看我们的 repo,所以其实在龙哥的激励下,我们的效率还是可以的 ? 。
2:30 AM
GZY 和 WPH 把今天安排的工作完成的差不多了,而且第二天还靠他们主要准备 Demo Show,就去睡觉了,川总也已经困得不行了,准备打烊睡觉。我和川总合计了一下,还差一个最重要的 Feature,抱着就试一把,不行就手工的心态,我们把社区的小伙伴王聪(bb7133)提的支持 CREATE TABLE AS SELECT 语法的 PR 合到了我们的分支,冲突竟然不是太多,然后稍微改了一下来支持 Streaming,结果一运行奇迹般地发现竟然能够运行,RP 全面爆发了,于是我们就近乎免费地增加了一个 Feature。改完这个地方,川总实在坚持不住了,就回去睡了。我这边的 http restful api 也搞的差不多了,准备联调一把,StreamReader 通过 http client 从 collector 读数据,collector 通过 kafka consumer 从 kafka broker 获取数据,结果获取的 Json 数据序列化成 TiDB 自定义的 Time 类型老是出问题,于是我又花了一些时间给 Time 增加了 Marshall 和 Unmarshal 的格式化支持,到这里基本上可以 work 了,看了看时间,凌晨四点半,我也准备去睡了。期间好几次看到霸哥(韩飞)凌晨还在一直帮小(tian)伙(zi)伴(ji)查(wa)问(de)题(keng),其实霸哥认真的时候还是非常靠谱的。
7:30 AM
这个时候人陆陆续续地来了,我这边也进入了打酱油的角色,年纪大了确实刚不动了,吃了早餐之后,开始准备思考接下来的分工。因为大家都是临时组队,到了 Hackathon 才碰面,基本上没有太多磨合,而且普遍第二天状态都不大好。虽然大家都很努力,但是在我之前设计的宏大项目面前,还是感觉人力不太够,所以早上 10 点我们开了第二次 sync 的 catch up,讨论接下来的安排。我去负责更新代码和 GitHub 的 Readme,川总最后再简单对代码扫尾,顺便和 GZY 去录屏(罗伯特小姐姐介绍的不翻车经验),WPH 准备画图和 PPT,因为时间有限,前端展现部分打算从卖家秀直接转到买家秀。11 点敲定代码完全封板,然后安心准备 PPT 和下午的 Demo。
14:00 PM
因为抽签抽的比较靠后,主要事情在 WPH 这边,我和川总基本上也没什么大事了,顺手搞了几幅图,然后跟马老师还有其他项目的小伙伴们开始八卦聊天。因为正好周末,家里妹子买东西顺便过来慰问了下。下午主要听了各个 Team 的介绍,欣赏到了极尽浮夸的 LOGO 动画,Get 到了有困难找 Big Brother 的新技能,学习和了解了很有意思的 Idea,真心觉得这届 Hackathon 做的非常值得回忆。
从最后的现场展示情况来看,因为 TBSSQL 内容比较多,真的展示下来,感觉 6 分钟时间还是太赶,好在 WPH Demo 的还是非常顺利的,把我们做的事情都展示出来了。因为砍掉了一些前端展现的部分(这块我们也确实不怎么擅长),其实对于 Hackathon 项目是非常吃亏的,不过有一点比较欣慰,就像某光头大佬说的,评委们都是懂技术的。因为实现完整性方面能做的也都搞差不多了,打的虽然很累但是也很开心,对于结果也就不怎么纠结了。

因为川总晚上的飞机,小伙伴们简单沟通了几句,一致同意去园区找个地吃个晚饭,于是大家拉上霸哥去了“头一号”,也是第一次吃了大油条,中间小伙伴们各种黑谁谁谁写的 bug 巴拉巴拉的,后来看手机群里有人 @ 我说拿奖了。
其实很多项目各方面综合实力都不错,可以说是各有特色,很难说的上哪个项目有绝对的优势。我们之前有讨论过,TBSSQL 有获奖的赢面,毕竟从完整性,实用性和生态方面都是有潜质的,但是能获得大家最高的认可还是小意外的,特别感谢各位技术大佬们,也特别感谢帮助我们领奖的满分罗伯特小姐姐。

最后大家补了一张合照,算是为这次 Hackathon 画下一个句号。

至此,基本上 Hackathon 的流水账就记录完了,整个项目地址在 https://github.com/qiuyesuifeng/tidb 欢迎大家关注和讨论。
选读:技术实现
TLDR: 文章很长,挑感兴趣的部分看看就可以了。
在前期分析和准备之后,基本上就只有在 TiDB 上做 SQL Streaming 引擎一条路可选了,细化了下要实现的功能以及简单的系统架构,感觉工作量还是非常大的。
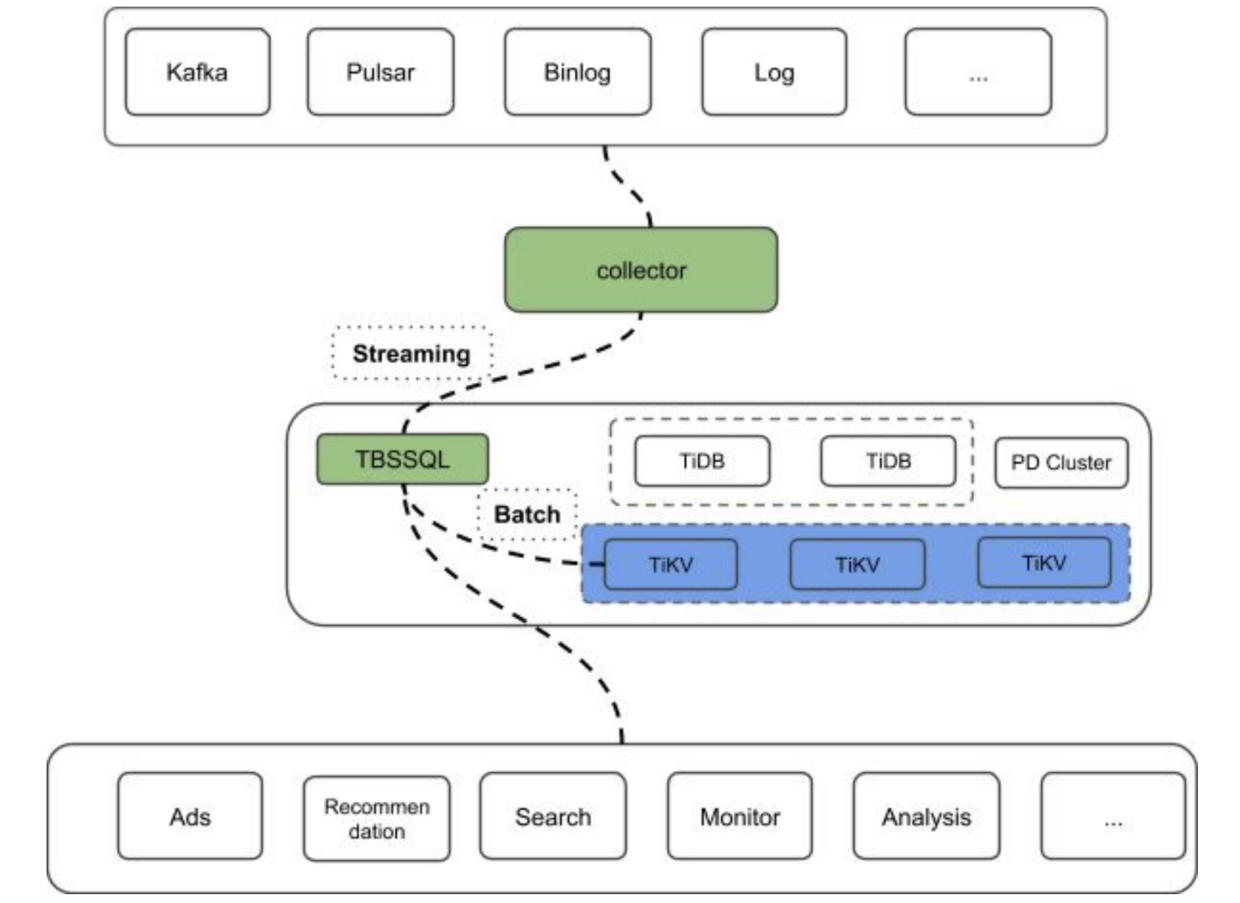
下面简单介绍下系统架构和各个模块的功能:
在数据源采集部分(collector),我们计划选取几种典型的数据源作为适配支持。
-
Kafka
最流行的开源 MQ 系统,很多 Streaming 系统对接的都是 Kafka。
-
Pulsar
流行的开源 MQ 系统,目前比较火爆,有赶超 Kafka 的势头。
-
Binlog
支持 MySQL/TiDB Binlog 处理,相当于是 MySQL Trigger 功能的升级加强版了。我们对之前的 MySQL -> TiDB 的数据同步工具 Syncer 也比较熟悉,所以这块工作量应该也不大。
-
Log
常见的 Log 日志,这个就没什么好解释的了。
为了方便 Demo 和协作,collector 除了适配不同的数据源,还会提供一个 restful api 的接口,这样 TBSSQL 就可以通过 pull 的方式一直获取 streaming 的数据。因为 collector 主要是具体的工程实现,所以就不在这里细节展开了,感兴趣的话,可以参考下 相关代码。
要在 TiDB 中实现 Streaming 的功能即 TBSSQL,就需要在 TiDB 内部深入定制和修改 TiDB 的核心代码。
Streaming 有两个比较本质的特征:
-
Streaming 具有流式特性,也就是说,其数据可以是一直增长,无穷无尽的。而在 Batch 系统(暂时把 MySQL/TIDB 这种数据在一定时间内相对稳定的系统简称 Batch 系统,下面都会沿用这种说法)当中,每个 SQL 的输入数据集是固定,静态的。
-
Streaming 具有时序特性。每一条数据都有其内在的时间属性(比如说事件发生时间等),数据之间有先后顺序关系。而在 Batch 系统当中,一个表中的数据在时间维度上是无序的。
因此,要在 TiDB SQL 引擎上支持 Streaming SQL,所涉及到的算子都需要根据 Streaming 的这两个特点做修改。以聚合函数(Aggregation)为例,按照 SQL 语义,聚合算子的实现应该分成两步:首先是 Grouping, 即对输入按照聚合列进行分组;然后是 Execute, 即在各个分组上应用聚合函数进行计算,如下图所示。
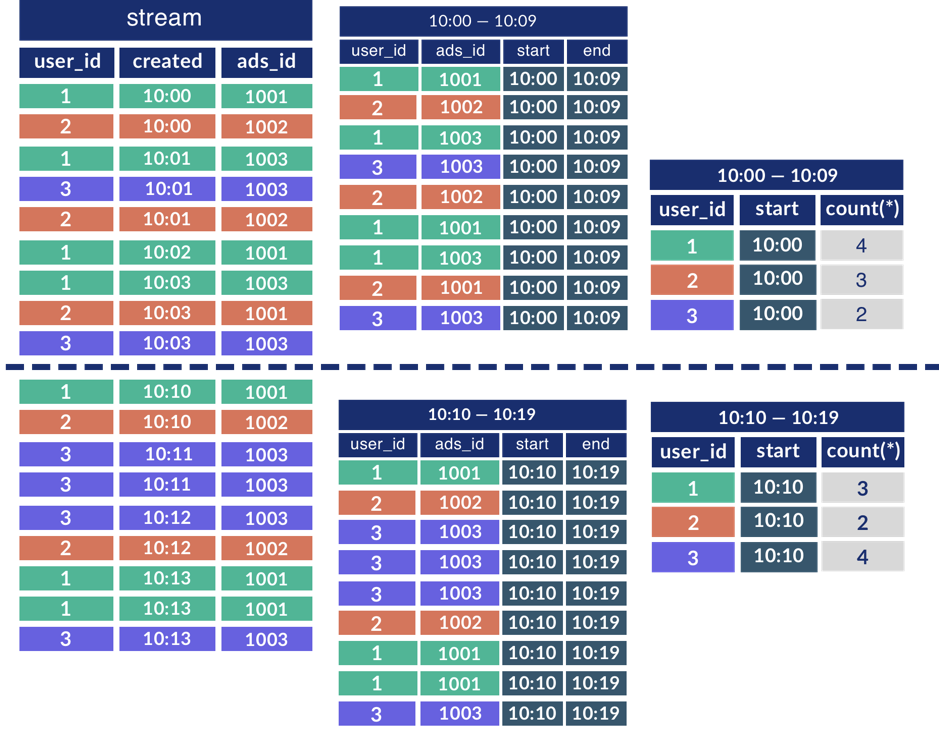
对于 Streaming,因为其输入可以是无尽的,Grouping 这个阶段永远不可能结束,所以按照老套路,聚合计算就没法做了。这时,就要根据 Streaming 的时序特性对 Streaming 数据进行分组。每一个分组被称为一个 Time Window(时间窗口)。就拿最简单的 Tumbling Window 来说,可以按照固定的时间间隔把 Streaming 输入切分成一个个相互无交集的窗口,然后在每一个窗口上就可以按照之前的方式进行聚合了。
聚合算子只是一个比较简单的例子,因为其只涉及一路输入。如果要修改多路输入的算子(比如说 Join 多个 Streaming),改动更复杂。此外,时间窗口的类型也是多种多样,刚刚例子中的 Tumbling Window 只是基础款,还有复杂一点的 Hopping Window 以及更复杂的 Sliding Window。在 Hackathon 的有限时间内,我们既要考虑实现难度,又要突出 Batch / Streaming 融合处理的特点,因此在技术上我们做出如下抉择:
-
时间窗口只做最基本的 Tumbling Window。
-
实现基于时间窗口的 Aggregation 和 Sort 作为经典流式算子的代表。
-
实现单 Streaming Join 多 Batch Table 作为 Batch / Streaming 融合的示例, 多个 Streaming Join 太复杂,因为时间有限就先不做了。
-
支持 Streaming 处理结果写入 Batch Table(TiDB Table)这种常见但是非常实用的功能。也就是说要支持
CREATE TABLE AS SELECT xxx FROM streaming的类似语法。
此外,既然是要支持 Streaming SQL,选择合适的 SQL 语法也是必要的,需要在 Parser 和 DDL 部分做相应的修改。单整理下,我们的 Feature List 如下图所示:

下面具体聊聊我们实现方案中的一些关键选择。
-
Streaming SQL 语法
Streaming SQL 语法的核心是时间窗口的定义,Time Window 和一般 SQL 中的 Window Function 其实语义上是有区别的。在 Streaming SQL 中,Time Window 主要作用是为后续的 SQL 算子限定输入的范围,而在一般的 SQL 中,Window Funtion 本身就是一个 SQL 算子,里面的 Window 其实起到一个 Partition 的作用。
在纯 Streaming 系统当中,这种语义的差别影响不大,反而还会因为语法的一致性降低用户的学习成本,但是在 TBSSQL 这种 Batch / Streaming 混合场景下,同一套语法支持两种语义,会对用户的使用造成一定困扰,特别是在 TiDB 已经被众多用户应用到生产环境这种背景下,这种语义上的差别一定要体现在语法的差异上。
-
Sreaming DDL
DDL 这一块实现难度不大,只要照着 DDL源码解析 依葫芦画瓢就行。这里值得一提的是在 Meta 层,我们直接(偷懒)复用了 TableInfo 结构(加了判断是否为 Streaming 的 Flag 和一些表示 Streaming 属性的字段)来表示 Streaming Table。这个选择主要是从实现难度上考虑的,毕竟复用现有的结构是最快最安全的。但是从设计思想上看,这个决定其实也暗示了在 TBSSQL 当中,Streaming 是 Table 的一种特殊形式,而不是一个独立的概念。理解这一点很重要,因为这是一些其他设计的依据。比如按照以上设定,那么从语义上讲,在同一个 DB 下 Streaming 和普通 Table 就不能重名,反之的话这种重名就是可以接受的。
-
StreamReader
这一块主要有两个部分,一个是适配不同的数据源(collector),另一个是将 Streaming 数据源引入 TiDB 计算引擎(StreamReader)。collector 这部分上面已经介绍过了,这里就不再过多介绍了。StreamReader 这一块,主要要修改由 LogicalPlan 生成 PhysicalPlan(具体代码),以及由 PhysicalPlan 生成 Executor Operator Tree 的过程(具体代码)。StreamReader 的 Open 方法中,会利用 Meta 中的各种元信息来初始化与 collector 之间的连接,然后在 Next 方法中通过 Pull 的方式不断拉取数据。
-
对时间窗口的处理
前面我们提到,时间窗口是 Streaming 系统中的核心概念。那么这里就有一个重要的问题,Time Window 中的 Time 如何界定?如何判断什么时候应该切换 Window?最容易想到,也是最简单粗暴的方式,就是按照系统的当前时间来进行切割。这种方式问题很大,因为:
- 数据从生成到被 TBSSQL 系统接收到,肯定会有一定的延迟,而且这个延迟时间是没有办法精确预估的。因此在用户实际场景中,除非是要测量收发延迟,这个系统时间对用户没有太大意义。
- 考虑到算子并发执行的可能性(虽然还没有实现),不同机器的系统时间可能会有些许偏差,这个偏差对于 Window 操作来说可能导致致命的误差,也会导致结果的不精确(因为 Streaming 源的数据 Shuffle 到不同的处理节点上,系统时间的误差可能不太一样,可能会导致 Window 划分的不一样)。
因此,比较合理的方式是以 Streaming 中的某一 Timestamp 类型的列来切分窗口,这个值由用户在应用层来指定。当然 Streaming 的 Schema 中可能有多个 Timestamp 列,这里可以要求用户指定一个作为 Window 列。在实现 Demo 的时候,为了省事,我们直接限定了用户 Schema 中只能有一个时间列,并且以该列作为 Window 列(具体代码)。当然这里带来一个问题,就是 Streaming 的 Schema 中必须有 Timestamp 列,不然这里就没法玩了。为此,我们在创建 Streaming 的 DDL 中加了 检查逻辑,强制 Streaming 的 Schema 必须有 Timestamp 列(其实我们也没想明白当初 Hackathon 为啥要写的这么细,这些细节为后来通宵埋下了浓重的伏笔,只能理解为程序猿的本能,希望这些代码大家看的时候吐槽少一些)。
-
Streaming DML
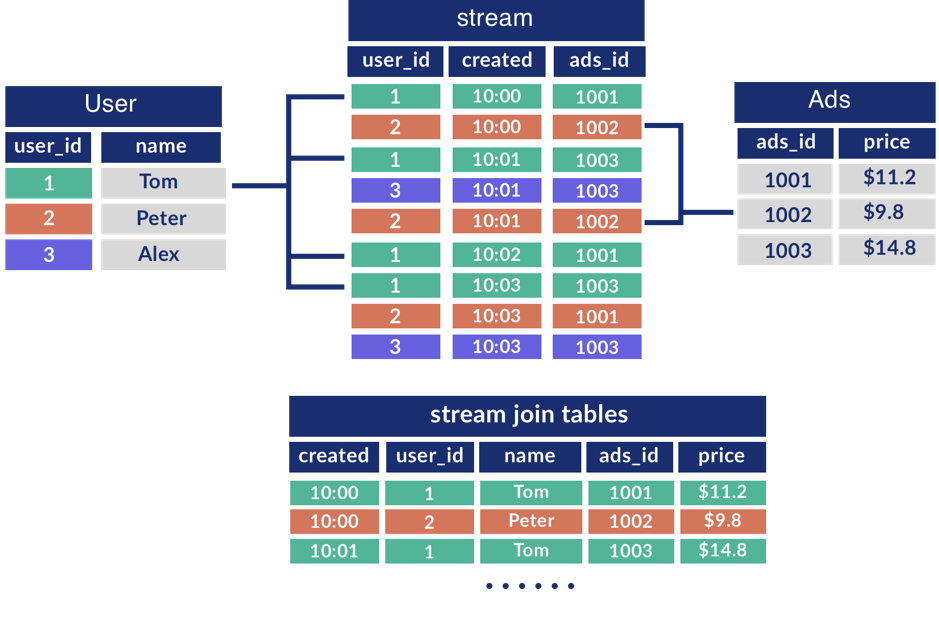
这里简单 DML 指的就是不依赖时间窗口的 DML,比如说只带 Selection 和 Projection 的SELECT 语句,或者单个 Streaming Join 多个 Table。因为不依赖时间窗口,支持这类 DML 实际上不需要对计算层做任何改动,只要接入 Streaming 数据源就可以了。
对于 Streaming Join Table(如上图表示的是 Stream Join User&Ads 表的示意图) 可以多说一点,如果不带 Time Window,其实这里需要修改一下Planner。因为 Streaming 的流式特性,这里可能没法获取其完整输入集,因此就没法对 Streaming 的整个输入进行排序,所以 Merge Join 算法这里就没法使用了。同理,也无法基于 Streaming 的整个输入建 Hash 表,因此在 Hash Join 算法当中也只能某个普通表 Build Hash Table。不过,在我们的 Demo 阶段,输入其实也是还是有限的,所以这里其实没有做,倒也影响不大。
-
基于时间窗口的 Aggregation 和 Sort
在 TBSSQL 当中,我们实现了基于固定时间窗的 Hash Aggregation Operator 和 Sort Operator。这里比较正规的打法其实应该是实现一个独立的 TimeWindow,各种基于时间窗口的 Operator 可以切换时间窗的逻辑,然后比如 Aggregation 和 Sort 这类算子只关心自己的计算逻辑。 但是这样一来要对 Planner 做比较大的改动,想想看难度太大了,所以我们再一次采取了直(tou)接(lan)的方法,将时间窗口直接实现分别实现在 Aggregation 和 Sort 内部,这样 Planner 这块不用做伤筋动骨的改动,只要在各个分支逻辑上修修补补就可以了。
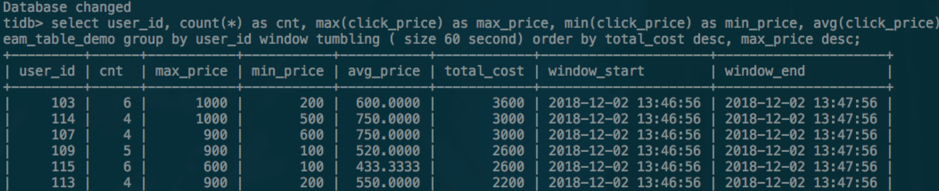
对于 Aggregation,我们还做了一些额外的修改。Aggregation 的输出 Schema 语义上来说只包括聚合列和聚合算子的输出列。但是在引入时间窗口的情况下,为了区分不同的窗口的聚合输出,我们为聚合结果显式加上了两个 Timestamp 列
window_start和window_end, 来表示窗口的开始时间和结束时间。为了这次这个小特性,我们踩到一个大坑,费了不少劲,这个后面再仔细聊聊。 -
支持 Streaming 处理结果写入 Batch Table
因为 TiDB 本身目前还暂时不支持 CREATE TABLE AS SELECT … 语法,而从头开始搞的话工作量又太大,因此我们一度打算放弃这个 Feature。后面经过老司机提醒,我们发现社区的小伙伴王聪(bb7133)已经提了一个 PR 在做这个事情了。本着试一把的想法我们把这个 PR 合到我们的分支上一跑,结果竟然没多少冲突,还真能 Work……稍微有点问题的是如果 SELECT 子句中有带时间窗口的聚合,输出的结果不太对。仔细研究了一下发现,CREATE TABLE AS SELECT 语句中做 LogicalPlan 的路径和直接执行 SELECT 时做 LogicalPlan 的入口不太一致,以至于对于前者,我们做 LogicalPlan 的时候遗漏了一些 Streaming 相关信息。这里稍作修改以后,也能够正常运行了。
遇到的困难和坑
本着前人采坑,后人尽量少踩的心态聊聊遇到的一些问题,主要的技术方案上面已经介绍的比较多了。限于篇幅,只描述遇到的最大的坑——消失的窗口列的故事。在做基于时间窗口的 Aggregation 的时候,我们要按照用户指定的窗口列来切窗口。但是根据 列裁剪 规则,如果这个窗口列没有被用作聚合列或者在聚合函数中被使用,那么这一列基本上会被优化器裁掉。这里的修改很简单(我们以为),只需要在聚合的列裁剪逻辑中,如果发现聚合带时间窗口,那么直接不做裁剪就完事儿了(代码)。三下五除二修改完代码,编译完后一运行,结果……瞬间 Panic 了……Debug 一看,发现刚刚的修改没有生效,Streaming 的窗口列还是被裁剪掉了,随后我们又把 Planner 的主要流程看了一遍,还是没有在其他地方发现有类似的裁剪逻辑。
这时我们意识到事情没有这么简单了,赶忙从导师团搬来老司机(还是上面那位)。我们一起用简单粗暴的二分大法和 Print 大法,在生成 LogicalPlan,PhysicalPlan 和 Executor 前后将各个算子的 Schema 打印出来。结果发现,在 PhysicalPlan 完成后,窗口列还是存在的,也就是说我们的修改是生效了的,但是在生成 Executor 以后,这一列却神秘消失了。所以一开始我们定位的思路就错了,问题出在生成 Executor 的过程,但是我们一直在 Planner 中定位,当然找不到问题。
明确了方向以后,我们很快就发现了元凶。在 Build HashAggregation 的时候,有一个不起眼的函数调用 buildProjBelowAgg,这个函数悄悄地在 Aggregation 算子下面加塞了一个 Projection 算子,顺道又做了一把列裁剪,最为头疼的是,因为这个 Projection 算子是在生成 Executor 阶段才塞进去的,而 EXPLAIN 语句是走不到这里来的,所以这个 Projection 算子在做 Explain 的时候是看不见的,想当于是一个隐形的算子,所以我们就这样华丽丽地被坑了,于是就有了罗伯特小姐姐听到的那句 “xxx,出来挨打” 的桥段。
今后的计划
从立项之初,我们就期望 TBSSQL 能够作为一个正式的 Feature 投入生产环境。为此,在设计和实现过程中,如果能用比较优雅的解决方案,我们都尽量不 Hack。但是由于时间紧迫和能力有限,目前 TBSSQL 还是处于 Demo 的阶段,离实现这个目标还有很长的路要走。
1. Streaming 数据源
在对接 Streaming 数据源这块,目前 TBSSQL 有两个问题。首先,TBSSQL 默认输入数据是按照窗口时间戳严格有序的。这一点在生产环境中并不一定成立(比如因为网络原因,某一段数据出现了乱序)。为此,我们需要引入类似 Google MillWheel 系统中 Low Watermark 的机制来保证数据的有序性。其次,为了保证有序,目前 StreamReader 只能单线程运行。在实际生产环境当中,这里很可能因为数据消费速度赶不上上游数据生产速度,导致上游数据源的堆积,这又会反过来导致产生计算结果的时间和数据生产时间之间的延迟越来越大。为了解决这个问题,我们需要将 StreamReader 并行化,而这又要求基于时间窗口的计算算子能够对多路数据进行归并排序。另外,目前采用 TiDB Global Variable 来模拟 Streaming 的位置信息,其实更好地方案是设计用一个 TiDB Table 来记录每个不同 StreamReader 读取到的数据位置,这种做法更标准。
2. Planner
在 Planner 这块,从前面的方案介绍可以看出,Streaming 的流式特性和时序特性决定了 Streaming SQL 的优化方式和一般 SQL 有所不同。目前 TBSSQL 的实现方式是在现有 Planner 的执行路径上加上一系列针对 Streaming SQL 的特殊分支。这种做法很不优雅,既难以理解,也难以扩展。目前,TiDB 正在基于 Cascade 重构 Planner 架构,我们希望今后 Streaming SQL 的相关优化也基于新的 Planner 框架来完成。
3. 时间窗口
目前,TBSSQL 只实现了最简单的固定窗口。在固定窗口上,Aggregation、Sort 等算子很大程度能复用现有逻辑。但是在滑动窗口上,Aggregation、Sort 的计算方式和在 Batch Table 上的计算方式会完全不一样。今后,我们希望 TBSSQL 能够支持完善对各种时间窗口类型的支持。
4. 多 Streaming 处理
目前 TBSSQL 只能处理单路 Streaming 输入,比如单个 Streaming 的聚合,排序,以及单个Streaming 和多个 Table 之间的 Join。多个 Streaming 之间的 Join 因为涉及多个 Streaming 窗口的对齐,目前 TBSSQL 暂不支持,所以 TBSSQL 目前并不是一个完整的 Streaming SQL 引擎。我们计划今后对这一块加以完善。
TBSSQL 是一个复杂的工程,要实现 Batch/Streaming 的融合,除了以上提到这四点,TBSSQL 还有很有很多工作要做,这里就不一一详述了。或许,下次 Hackathon 可以再继续搞一把 TBSSQL 2.0 玩玩:) 有点遗憾的是作为选手出场,没有和所有优秀的参赛的小伙伴们畅谈交流,希望有机会可以补上。属于大家的青春不散场,TiDB Hackathon 2019,不见不散~~
















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









