







在之前的文章U-Net详解、生成式模型简介之自编码器、变分自编码器和生成对抗网络、去噪扩散模型DDPM详解、扩散模型的性能、应用和影响中,我们从U-Net开始介绍了扩散模型。从这篇文章开始,我们将通过代码来实现一步步地实现扩散模型,深入理解其中内容。
这篇文章就先来实现U-Net,U-Net 是一种最初为医学图像设计的卷积神经网络,例如,可以将一张心脏的图像输入网络,模型可能输出一张突出显示癌变区域的图片。U-Net本身不属于生成式AI的内容,但是它给扩散模型奠定了基础。
文章目录
1 介绍
虽然在U-Net详解中已经有实现U-Net的代码例子了。这篇文章我们提出一个新思路:如果我们给图像添加噪声,再使用 U-Net 将图像与噪声分离,会发生什么?我们是否可以仅向模型输入噪声,然后生成可识别的图像?
这篇文章我们就通过构建 U-Net 网络,探索如何利用其对图像进行去噪和生成新图像的能力。学习内容包括:使用 FashionMNIST 数据集,搭建 U-Net 架构(包含下采样和上采样模块),训练模型以从图像中去除噪声,并尝试生成服装图像。
2 准备工作
引入依赖和工具
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torch.optim import Adam
# 可视化工具
import graphviz
from torchview import draw_graph
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
设置设备(GPU 或 CPU)
在 PyTorch 中,我们可以设置运算使用 GPU(如果可用),否则退回到 CPU:
!nvidia-smi # 查看nvidia GPU的状态信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.cuda.is_available()
3 数据集
为了练习生成图像,我们将使用 FashionMNIST 数据集。FashionMNIST 被设计为图像分类问题的 “Hello World” 数据集。其黑白图像的尺寸较小(28 x 28 像素),也使它成为图像生成的绝佳起点。
FashionMNIST 包含在 Torchvision中,这是一个与 PyTorch 相关的计算机视觉库。下面代码的作用是加载 FashionMNIST 训练集,如果本地没有数据,就自动下载到 ./data/ 目录,并对每张图像做预处理:使用 ToTensor() 将图像转换为 PyTorch 的张量格式,同时把像素值从 [0, 255] 缩放到 [0.0, 1.0],并调整图像维度为 [通道 x 高度 x 宽度],以便神经网络处理。
train_set = torchvision.datasets.FashionMNIST(
"./data/", download=True, transform=transforms.Compose([transforms.ToTensor()])
)
现在我们查看一下这个数据集里的图片大概是什么样的:
# Adjust for display; high w/h ratio recommended
plt.figure(figsize=(16, 1))
def show_images(dataset, num_samples=10):
for i, img in enumerate(dataset):
if i == num_samples:
return
plt.subplot(1, num_samples, i + 1)
plt.imshow(torch.squeeze(img[0]))
show_images(train_set)
输出如下:

我们为数据集设置一些导入常量。对于 U-Net 网络来说,通常会通过 Max Pooling 不断减半特征图的尺寸,然后通过 Transposed Convolution(转置卷积) 再扩大尺寸。为了在 U-Net 的编码和解码过程中保持图像尺寸的一致性,最好将图像尺寸设置为可以被 2 多次整除的数值。
IMG_SIZE = 16 # 由于步长和池化操作,必须是能被 2 多次整除的数字
IMG_CH = 1 # 黑白图像,没有颜色通道
BATCH_SIZE = 128 # 每个 batch 的大小
现在我们定义了目标图像尺寸,接下来创建一个函数来加载数据并将其转换为目标大小。我们会给图像添加的随机噪声是从标准正态分布中采样的,这意味着 68%(±1个标准差) 的噪声像素值在 -1 到 1 之间。我们也会将图像像素值从原来的 [0, 1] 进一步缩放到 [-1, 1]。
这里也是一个进行图像增强的好地方。目前我们先使用 RandomHorizontalFlip(随机水平翻转)。我们不会使用 RandomVerticalFlip,因为那样会生成“倒过来的”图像。
# 定义函数:封装刚刚的加载FashionMNIST数据集的函数
def load_fashionMNIST(data_transform, train=True):
# 使用 torchvision 内置的数据集加载器加载 FashionMNIST
return torchvision.datasets.FashionMNIST(
"./", # 数据下载/存储的目录
download=True, # 如果本地没有,就从网上下载
train=train, # 是否是训练集(True)还是测试集(False)
transform=data_transform, # 对图像应用的变换
)
# 定义函数:加载并转换 FashionMNIST 数据集(包括数据增强与预处理)
def load_transformed_fashionMNIST():
# 定义图像预处理和增强的流程
data_transforms = [
transforms.Resize((IMG_SIZE, IMG_SIZE)), # 调整图像大小为目标尺寸
transforms.ToTensor(), # 转换为张量,像素值从 [0, 255] -> [0, 1]
transforms.RandomHorizontalFlip(), # 随机水平翻转图像
transforms.Lambda(lambda t: (t * 2) - 1) # 将像素值从 [0, 1] 缩放到 [-1, 1]
]
# 将上面的多个变换组合成一个整体流程
data_transform = transforms.Compose(data_transforms)
# 加载训练集并应用转换
train_set = load_fashionMNIST(data_transform, train=True)
# 加载测试集并应用转换
test_set = load_fashionMNIST(data_transform, train=False)
# 将训练集和测试集拼接起来作为一个完整数据集
return torch.utils.data.ConcatDataset([train_set, test_set])
# 加载转换后(包含训练+测试)的完整数据集
data = load_transformed_fashionMNIST()
# 创建数据加载器(DataLoader)用于训练时按批次读取数据
dataloader = DataLoader(
data, # 输入的数据集
batch_size=BATCH_SIZE, # 每批加载多少数据
shuffle=True, # 是否打乱数据
drop_last=True # 是否丢弃最后一个不足一个 batch 的数据
)
4 U-Net架构
首先,我们来定义 U-Net 架构中的不同组成部分,主要是 DownBlock 和 UpBlock。
4.1 下采样模块(Down Block)
DownBlock 是一个典型的CNN模块。如果你是 PyTorch 新手,并且之前用的是 Keras/TensorFlow,那你会发现下面的结构更像是函数式 API,而不是顺序模型。我们之后会用到残差连接和跳跃连接(skip connections)。顺序模型不支持这种灵活的连接方式,而函数式模型则可以。
在下面的 __init__ 方法中,我们会将各种神经网络操作赋值为类的变量:
Conv2d:对输入进行二维卷积。in_ch表示输入通道数,out_ch表示输出通道数,也就是使用了多少个卷积核。在 U-Net 架构中,通常越往下通道数越多。ReLU:卷积后的激活函数。BatchNorm2d:对神经元层应用 批量归一化(Batch Normalization)。ReLU 没有可学习参数,所以可以重复使用;但 BatchNorm 有可学习参数,复用会导致意料之外的结果。MaxPool2D:用于在向下传递过程中缩小特征图的尺寸。虽然也可以用卷积实现这个效果,但 U-Net 中常用的是最大池化。
在 forward 方法中,我们定义了这些操作应该如何按顺序应用于输入。目前为止,操作顺序如下:
Conv2d→BatchNorm2d→ReLU→Conv2d→BatchNorm2d→ReLU→MaxPool2d
class DownBlock(nn.Module):
def __init__(self, in_ch, out_ch):
kernel_size = 3 # 能捕捉小区域特征
stride = 1 # 不跳过任何像素,保持精度
padding = 1 # 保持输出尺寸不变(输入和输出高宽一致)
super().__init__()
layers = [
nn.Conv2d(in_ch, out_ch, kernel_size, stride, padding),
nn.BatchNorm2d(out_ch),
nn.ReLU(),
nn.Conv2d(out_ch, out_ch, kernel_size, stride, padding),
nn.BatchNorm2d(out_ch),
nn.ReLU(),
nn.MaxPool2d(2)
]
self.model = nn.Sequential(*layers) # *layers前面的*表示解包
def forward(self, x):
return self.model(x)
4.2 上采样模块(The Up Block)
虽然 DownBlock 模块会减小特征图的尺寸,UpBlock 模块则会把尺寸放大回来。这是通过 ConvTranspose2d 实现的。
我们可以用几乎和 DownBlock 一样的结构,只是把普通的卷积 Conv2d 换成了转置卷积 ConvTranspose2d。其中 stride=2 和适当的 padding 可以让特征图尺寸扩大一倍。
4.2.1 实验示例
我们用一张全是 1 的小图像来演示 ConvTranspose2d 是如何影响尺寸的。下面代码输出的张量形状是 [1, 1, 3, 3](batch=1, channel=1, 高=3, 宽=3)。
ch, h, w = 1, 3, 3
x = torch.ones(1, ch, h, w)
输出:
tensor([[[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]]])
我们可以使用单位卷积核(Identity kernel)来观察 conv_transpose2d 是如何改变输入图像的。这个单位卷积核中只有一个值为 1。当使用它进行卷积操作时,输出将与输入相同。
试着修改下面的 stride、padding以及 output_padding。结果是否符合你的预期?
kernel = torch.tensor([[1.]]) # Identity kernel
kernel = kernel.view(1, 1, 1, 1).repeat(1, ch, 1, 1) # Make into a batch
output = F.conv_transpose2d(x, kernel, stride=1, padding=0, output_padding=0)[0]
output
输出:
tensor([[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]])
卷积核的大小(kernel_size)同样会影响输出特征图的尺寸。试着修改下面的 kernel_size,注意当卷积核变大时,输出图像也会随之变大了吗?
这与普通卷积相反,在普通卷积中,卷积核越大,输出特征图的尺寸通常会变小。
kernel_size = 3
kernel = torch.ones(1, 1, kernel_size, kernel_size)
output = F.conv_transpose2d(x, kernel, stride=1, padding=0, output_padding=0)[0]
output
输出:
tensor([[[1., 2., 3., 2., 1.],
[2., 4., 6., 4., 2.],
[3., 6., 9., 6., 3.],
[2., 4., 6., 4., 2.],
[1., 2., 3., 2., 1.]]])
另一个有趣的区别是:我们会将输入的通道数乘以 2。这样做是为了适配跳跃连接(skip connections)。我们会将某个 UpBlock 对应的 DownBlock 的输出,与当前 UpBlock 的输入进行拼接。
如果输入特征图的尺寸是 x,那么输出尺寸的计算公式如下:
n e w _ x = ( x − 1 ) ∗ s t r i d e + k e r n e l _ s i z e − 2 ∗ p a d d i n g + o u t _ p a d d i n g new\_x = (x - 1) * stride + kernel\_size - 2 * padding + out\_padding new_x=(x−1)∗stride+kernel_size−2∗padding+out_padding
如果 stride = 2 且 out_padding = 1,为了使输出尺寸变为输入的两倍,则:
k
e
r
n
e
l
_
s
i
z
e
=
2
∗
p
a
d
d
i
n
g
+
1
kernel\_size = 2 * padding + 1
kernel_size=2∗padding+1
这个模块的操作与之前几乎相同,但有两个主要区别:
ConvTranspose2d—— 使用转置卷积代替普通卷积MaxPool2d—— 尺寸是“放大”而不是“缩小”
4.2.2 上采样代码
现在我们来实现上采样部分的代码:
# 定义 UpBlock 类,用于 U-Net 中的上采样模块,继承自 nn.Module
class UpBlock(nn.Module):
def __init__(self, in_ch, out_ch):
# 定义常规卷积参数
kernel_size = 3 # 卷积核大小为 3x3
stride = 1 # 步幅为 1,表示不跳格
padding = 1 # padding 为 1,这样输入输出尺寸不会变化(保持对齐)
# 定义转置卷积(上采样)参数
strideT = 2 # 转置卷积的步幅为 2,用于将特征图放大 2 倍
out_paddingT = 1 # 输出填充为 1,用于微调输出尺寸(确保尺寸对齐)
# 初始化父类
super().__init__()
# 注意:因为会与 skip connection 拼接,所以输入通道数翻倍(2 * in_ch)
layers = [
# 转置卷积:放大特征图尺寸,通道数从 2*in_ch 缩小为 out_ch
nn.ConvTranspose2d(2 * in_ch, out_ch, kernel_size, strideT, padding, out_paddingT),
# 批量归一化:加快训练、稳定收敛
nn.BatchNorm2d(out_ch),
# 激活函数 ReLU
nn.ReLU(),
# 普通卷积:提取特征
nn.Conv2d(out_ch, out_ch, kernel_size, stride, padding),
nn.BatchNorm2d(out_ch),
nn.ReLU()
]
# 将层组织成一个顺序模型
self.model = nn.Sequential(*layers)
# 前向传播函数,x 是主路数据,skip 是跳跃连接的数据
def forward(self, x, skip):
# 将上采样后的特征图x与来自 encoder 的 skip 特征图在通道维度上拼接
x = torch.cat((x, skip), 1)
# 送入上面定义好的模型中进行处理
x = self.model(x)
return x
4.3 完整的U-Net
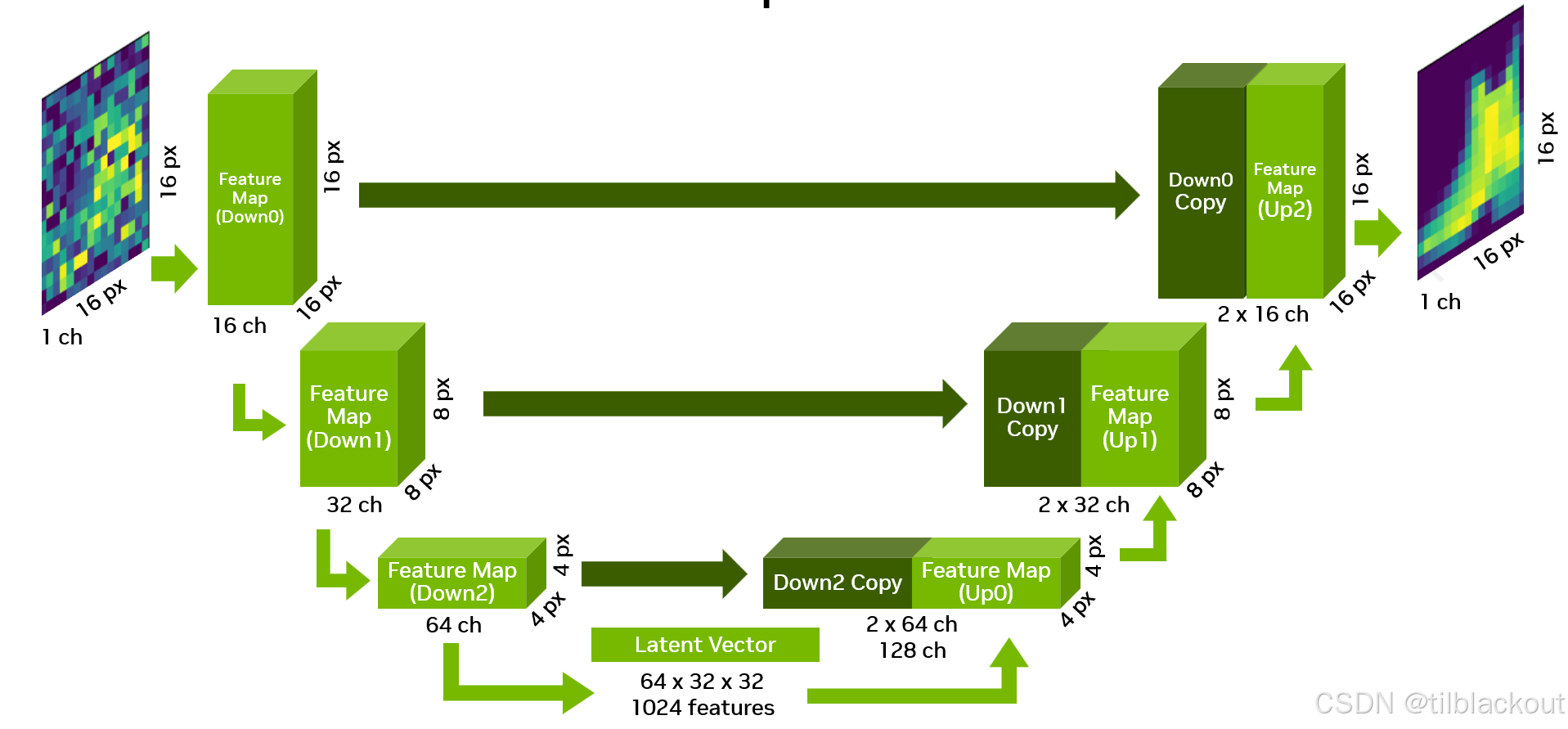
现在我们就可以把上采样和下采样的代码组合起来了,在 __init__ 函数中,我们可以用 down_chs 来定义 U-Net 各个阶段的通道数量。当前的默认设置是 (16, 32, 64),这意味着数据在模型中流动时的尺寸变化如下:
- 输入:1 × 16 × 16
- down0:16 × 16 × 16
- down1:32 × 8 × 8
- down2:64 × 4 × 4
- dense_emb:1024
- up0:64 × 4 × 4
- up1:64 × 8 × 8
- down2:64 × 4 × 4
- up2:32 × 16 × 16
- down1:32 × 8 × 8
- 输出:1 × 16 × 16
在 forward 方法中,我们最终会加入所有的跳跃连接(skip connections)。在 U-Net 每下采样一步时,我们都会保留每个 DownBlock 的输出。
然后,在向上采样经过各个 UpBlock 时,我们会将当前 UpBlock 的输入与对应的 DownBlock 的输出进行拼接(concatenate)。
# 定义 U-Net 网络结构
class UNet(nn.Module):
def __init__(self):
super().__init__()
# 输入图像通道数(例如:灰度图是1)
img_ch = IMG_CH
# 下采样阶段的通道数(encoder)
down_chs = (16, 32, 64)
# 上采样阶段的通道数是下采样的反转(decoder)
up_chs = down_chs[::-1]
# 特征图在 bottleneck(最深处)的尺寸 = 输入尺寸除以4
latent_image_size = IMG_SIZE // 4 # 相当于经过两次 maxpool 后的尺寸
# --- 编码部分 ---
# 第一层:初始卷积,不缩小尺寸
self.down0 = nn.Sequential(
nn.Conv2d(img_ch, down_chs[0], 3, padding=1), # 卷积层
nn.BatchNorm2d(down_chs[0]), # 批量归一化
nn.ReLU() # 激活函数
)
# 下采样模块 1(带 max pooling)
self.down1 = DownBlock(down_chs[0], down_chs[1])
# 下采样模块 2
self.down2 = DownBlock(down_chs[1], down_chs[2])
# 将特征图拉平成向量(Flatten)
self.to_vec = nn.Sequential(
nn.Flatten(), # 拉平为一维
nn.ReLU()
)
# --- Bottleneck 中的全连接嵌入(embedding)模块 ---
self.dense_emb = nn.Sequential(
nn.Linear(down_chs[2] * latent_image_size**2, down_chs[1]), # 降维
nn.ReLU(),
nn.Linear(down_chs[1], down_chs[1]), # 中间层
nn.ReLU(),
nn.Linear(down_chs[1], down_chs[2] * latent_image_size**2), # 升维
nn.ReLU()
)
# --- 解码部分 ---
# up0:反转 flatten,将向量 reshape 成卷积特征图
self.up0 = nn.Sequential(
nn.Unflatten(1, (up_chs[0], latent_image_size, latent_image_size)),
nn.Conv2d(up_chs[0], up_chs[0], 3, padding=1),
nn.BatchNorm2d(up_chs[0]),
nn.ReLU(),
)
# up1:上采样模块,并与 down2 的输出进行 skip connection 拼接
self.up1 = UpBlock(up_chs[0], up_chs[1])
# up2:上采样,并与 down1 的输出拼接
self.up2 = UpBlock(up_chs[1], up_chs[2])
# 输出层:恢复到输入通道数量(如:灰度图为1)
self.out = nn.Sequential(
nn.Conv2d(up_chs[-1], up_chs[-1], 3, 1, 1),
nn.BatchNorm2d(up_chs[-1]),
nn.ReLU(),
nn.Conv2d(up_chs[-1], img_ch, 3, 1, 1), # 输出为原始通道
)
# 定义前向传播过程
def forward(self, x):
# 编码阶段
down0 = self.down0(x) # 初始卷积
down1 = self.down1(down0) # 下采样1
down2 = self.down2(down1) # 下采样2
latent_vec = self.to_vec(down2) # 拉平成向量
# 解码阶段
up0 = self.up0(latent_vec) # 向量 → 特征图
up1 = self.up1(up0, down2) # 上采样并拼接 skip1
up2 = self.up2(up1, down1) # 上采样并拼接 skip0
# 输出结果
return self.out(up2)
现在我们创建一个U-Net对象,然后看一下里面有几个参数:
model = UNet()
print("Num params: ", sum(p.numel() for p in model.parameters()))
输出:
Num params: 234977
我们可以使用torchview来验证模型的结构。如果我们定义了三个 down_chs,那么应该会有两个 DownBlock,每一个负责一次下采样。同理,也应该有两个 UpBlock 负责上采样。
我们还需要检查是否有一条跳跃连接。U-Net 的“底部”不需要跳跃连接,所以跳跃连接的数量应该是 UpBlock 的数量减一。最后,要确认一下:输出的尺寸是否和输入的尺寸一致?
graphviz.set_jupyter_format('png')
model_graph = draw_graph(
model,
input_size=(BATCH_SIZE, IMG_CH, IMG_SIZE, IMG_SIZE),
device='meta',
expand_nested=True
)
model_graph.resize_graph(scale=1.5)
model_graph.visual_graph
由于图片过长,就不贴到博客中了,可以点击这里查看
在 PyTorch 2.0 中,我们可以对模型进行编译,以加快训练速度。编译的过程会将一系列操作发送到 GPU,就像装配线一样,把这些操作应用到输入上。你可以在官方文档中查看更多信息。
model = torch.compile(UNet().to(device))
5 训练
5.1 训练准备
我们尝试给图像添加噪声,然后看看我们的 U-Net 模型是否可以将其还原为干净的图像。我们用一个参数 beta 来控制图像中有多少是噪声,多少是原图;另一个参数 alpha(alpha = 1 - beta) 则是原图所占比例。
# 向图像中添加噪声
def add_noise(imgs):
dev = imgs.device # 获取图像所在的设备(CPU 或 GPU)
percent = .5 # 噪声比例(从 0 到 1 都可以尝试)
beta = torch.tensor(percent, device=dev) # 噪声比例张量
alpha = torch.tensor(1 - percent, device=dev) # 原图比例张量
noise = torch.randn_like(imgs) # 生成与图像大小相同的随机噪声
return alpha * imgs + beta * noise # 将原图和噪声按比例混合
定义损失函数:原图和预测图之间的均方误差(MSE)
# 计算模型在输入噪声图像上的还原误差
def get_loss(model, imgs):
imgs_noisy = add_noise(imgs) # 先给图像加噪声
imgs_pred = model(imgs_noisy) # 输入噪声图像到模型中,得到预测图像
return F.mse_loss(imgs, imgs_pred) # 与原图做均方误差
可视化图像:将张量转回图像格式显示
# 显示张量图像(从 [-1, 1] 还原回 [0, 1],并转为 PIL 图像)
def show_tensor_image(image):
reverse_transforms = transforms.Compose([
transforms.Lambda(lambda t: (t + 1) / 2), # 把像素值从 [-1,1] 转回 [0,1]
transforms.Lambda(lambda t: torch.minimum(torch.tensor([1]), t)), # 限制最大值为 1
transforms.Lambda(lambda t: torch.maximum(torch.tensor([0]), t)), # 限制最小值为 0
transforms.ToPILImage(), # 转换为可显示的 PIL 图像
])
plt.imshow(reverse_transforms(image[0].detach().cpu())) # 取第一个图像并在 CPU 上显示
用子图展示模型训练效果的比较
为了在训练中观察模型效果,我们将对比:原图、加噪图、还原图。
# 禁用梯度计算,用于可视化模型表现
@torch.no_grad()
def plot_sample(imgs):
# 取 batch 中的第一个图像
imgs = imgs[[0], :, :, :]
imgs_noisy = add_noise(imgs[[0], :, :, :]) # 添加噪声
imgs_pred = model(imgs_noisy) # 输入噪声图,预测原图
nrows = 1
ncols = 3
samples = {
"Original": imgs,
"Noise Added": imgs_noisy,
"Predicted Original": imgs_pred
}
# 创建子图,分别显示三张图像
for i, (title, img) in enumerate(samples.items()):
ax = plt.subplot(nrows, ncols, i+1)
ax.set_title(title)
show_tensor_image(img)
plt.show()
5.2 模型训练
现在我们开始训练模型,并每隔一段时间可视化对比图。
# 设置优化器
optimizer = Adam(model.parameters(), lr=0.0001)
epochs = 2
# 设置模型为训练模式
model.train()
# 开始训练循环
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
optimizer.zero_grad() # 清空上一次的梯度
images = batch[0].to(device) # 获取当前 batch 的图像,并转到 GPU
loss = get_loss(model, images) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新权重
# 每训练 100 步,打印一次损失并可视化
if epoch % 1 == 0 and step % 100 == 0:
print(f"Epoch {epoch} | Step {step:03d} Loss: {loss.item()} ")
plot_sample(images)
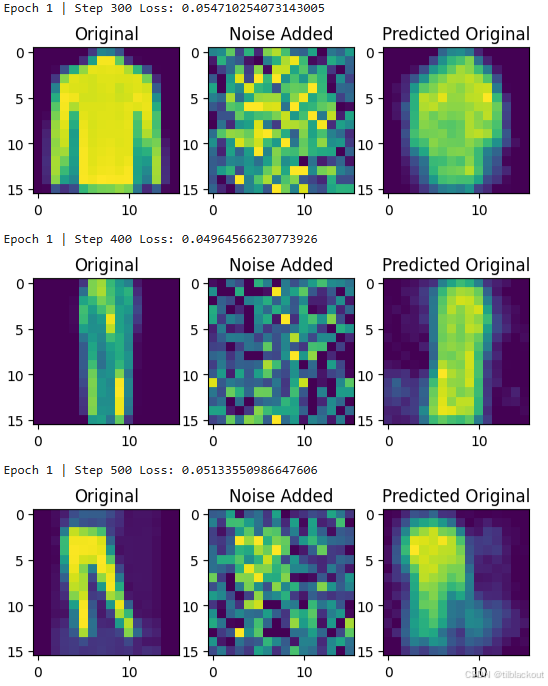
下面是训练过程中的后三次可视化输出,可以看出虽然预测图中还有一点点噪声,但它已经能很好地还原出原始的服装图像了。
那如果我们给模型纯噪声,即没有任何原图信息的噪声,它的效果如何呢?
# 设置模型为评估模式
model.eval()
# 输入完全随机的噪声,看模型生成出的图像
for _ in range(10):
noise = torch.randn((1, IMG_CH, IMG_SIZE, IMG_SIZE), device=device) # 生成一张随机噪声图
result = model(noise) # 输入模型得到“生成图”
nrows = 1
ncols = 2
samples = {
"Noise": noise,
"Generated Image": result
}
# 显示噪声和模型输出
for i, (title, img) in enumerate(samples.items()):
ax = plt.subplot(nrows, ncols, i+1)
ax.set_title(title)
show_tensor_image(img)
plt.show()
输出如下:
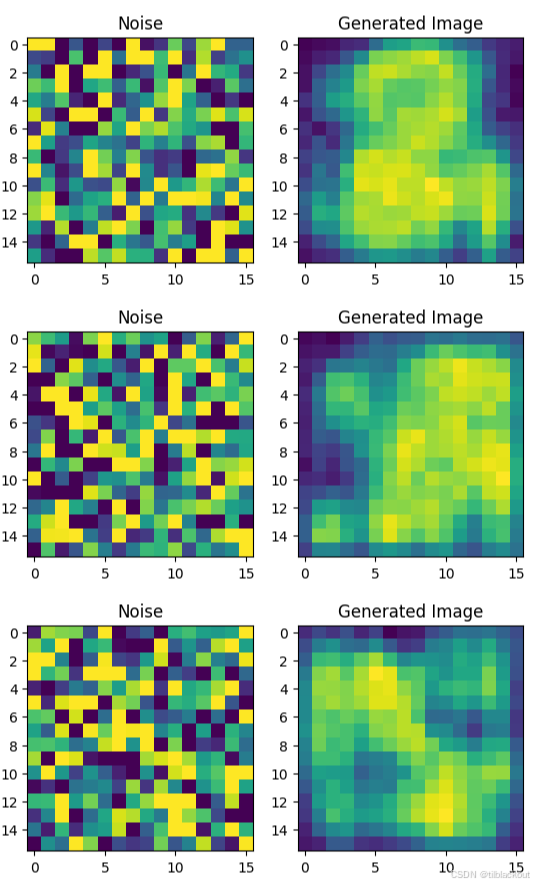
尽管模型的输入是完全无意义的纯噪声,但 U-Net 仍然能够生成具有模糊结构和风格感的图像。这说明它已经“学会了”数据的特征分布,有基本的生成能力,只是当前训练还不够充分,图像清晰度和辨识度仍有提升空间。
6 总结
本篇博客以 U-Net 为基础,探索了其在图像去噪和生成方面的能力。通过向图像添加噪声训练模型,并进一步尝试从纯噪声中生成衣物图像,展示了 U-Net 在图像恢复与生成任务中的潜力。
但生成的图像看起来更像是墨水图,而不是衣服。在下一篇文章中,我们将改进这个方法,以生成更容易识别的图像。


















 7544
7544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}