







1、 corseek 是个神马东东?
答:中文分词(sphinx)一定听过吧!corseek就是基于sphinx研发,专攻中文搜索和信息处理领域,并且是一款开源的软件!(好吧,承认是照搬的
官网解读)
2、为啥使用corseek?
答:查询一个 “北京欢迎你” 获取的信息有 “北京” “欢迎” "北京欢迎你" 这样帮你分词并获取信息~其实功能不光如此,更多应用场景,遇到了再百度吧^_^
3、 开始喽
setup1.
先去官网下载相关软件(没软件,咋搭建- -)
下载地址:http://www.coreseek.cn/products-install/install_on_bsd_linux/
找到符合你的os对应的版本。
由于公司采用的是debian,我下载的是:
coreseek-4.1-beta版。
将三方软件下载到 /opt/tar 下
解压到/opt 下
# tar -zxvf coreseek-4.1-beta.tar.gz -C ../
至此,软件的下载就完成了^_^ 恭喜一下自己吧~
setup2.
开始学习安装corseek了!(确保自己在有大量空闲时间的情况下看哦!)
ps:配置之前,先检查一下必须的软件是否符合要求:
m4 >= 1.4.13
autoconf >= 2.65
automake >= 1.11
libtool >= 2.2.6b
debian 下 使用 dpkg -l 来查看软件版本
----------------------------------------------------------
开始喽!
1. 安装mmseg (分词软件,可以用来生成分词字典)
#
cd mmseg-3.2.14
#
./bootstrap
(出现warning可以忽略,如果出现error就百度吧~)
#./configure --prefix=/usr/local/mmseg3 (prefix=安装目录,根据需要自己设置)
#make && make install
2. 字典安装完,开始安装 coreseek
#cd csft-4.1
#sh buildconf.sh (执行shell脚本,warning可以忽略,出现error就百度吧~)
#
./configure --prefix=/usr/local/coreseek --without-unixodbc --with-mmseg --with-mmseg-includes=/usr/local/mmseg3/include/mmseg/ --with-mmseg-libs=/usr/local/mmseg3/lib/ --with-mysql (如果提示mysql问题,点我)
执行完 会看到 Thank you for choosing Sphinx!
#make && make install
激动人心的时刻到来了!
##测试mmseg分词,coreseek搜索(需要预先设置好字符集为zh_CN.UTF-8,确保正确显示中文)
#cd testpack
#cat var/test/test.xml #此时应该正确显示中文
#/usr/local/mmseg3/bin/mmseg -d /usr/local/mmseg3/etc var/test/test.xml (字典相关)
#/usr/local/coreseek/bin/indexer -c etc/csft.conf --all
(根据配置文件,创建索引 --all表示全部索引)
#/usr/local/coreseek/bin/search -c etc/csft.conf 网络搜索 (测试 -c 配置文件)
更多命令:
#/usr/local/coreseek/bin/searchd -c etc/csft.conf --console (启动搜索,带有console的)
#/usr/local/coreseek/bin/searchd -c etc/csft.conf(启动搜索进程,后台保持,可用ps aux | grep searchd查看)
#
/usr/local/coreseek/bin/searchd -c etc/csft.conf --stop(停止服务)
#
/usr/local/coreseek/bin/indexer -c 配置文件 索引名称(更新后台服务的索引,需要重启服务索引才会生效)
#
/usr/local/coreseek/bin/indexer -c 配置文件 索引名称(--all)(--rotate 此参数可以无需重启服务即可更新索引)
--------------------------------------- 至此 coreseek已经成功安装,恭喜一下自己吧~
setup3. linux的软件都是安装容易,配置麻烦~coreseek也不例外,现在来看如何配置一个中文分词服务
主要分为2大块:
1. 源定义 --》 提供数据的东东
2. 索引定义 --》 根据源生成索引的东东
---------------------------
插入一个小道消息:
生成sphinx中文分词词库:
1.
词典的构造 #
mmseg -u unigram.txt 生成一个 unigram.txt.uni文件
2. 将文件改名为 uni.lib 完成词典的构造。 (unigram.txt必须为utf8)
词典文件(
unigram.txt
)的格式:
....
河 187
x:187
造假者 1
x:1
台北队 1
x:1
湖边 1
......
A:每条记录分两行
B:第一行为词项,其格式为:[词条]\t[词频率] 对于单个字后面跟这个字作单字成词的频率,这个频率需要在大量的预先切分好的语料库中进行统计,用户增加或删除词时,一般不需要修改这个数值;对于非单字词,词频率处必须为1。( 简单来说就是 非单个字必须为1 单个字需要根据整体的出现频率来设定该值)
C:第二行为占位项,是由于 LibMMSeg库的代码是从Coreseek其他的分词算法库(N-gram模型)中改造而来的,在原来的应用中,第二行为该词在各种词性下的分布频率。LibMMSeg的用户只需要简单的在第二行处填"x:1"即可。( 简单来说就是 第二行的数字就是上面的词频率)
词库生成后,无需重启searchd服务
---------------------------------------
继续看配置文件吧^_^
# 源
source pai
{
type = mysql
sql_host = 172.16.11.27
sql_user = root
sql_pass =
sql_db = gaokaopai
sql_port = 3306 # optional, default is 3306
sql_sock = /tmp/mysql.sock
sql_query_pre = SET NAMES utf8
#创建主索引前更改标识位置
sql_query_pre = replace into sph_counter \
select 1, (max(id)) from volenteer
# 查询的东东, 别名是用来进行sql_attr_*的
sql_query = SELECT id, id as sid, ask, category, ctime, answer from volenteer where \
id <= (select max_doc_id from \
sph_counter where counter_id=1) order by @$id desc
# 这个部分不会被索引,但是可以通过这个属性对结果进行排序
sql_attr_uint = sid
sql_attr_uint = ctime
# 查询到的id 用来查询需要的东西
sql_query_info = SELECT ask,id FROM volenteer WHERE id=$id
}
# 主索引
index pai
{
source = pai #源名称
path = /var/sphinx/index/pai #索引存放的位置
docinfo = extern
charset_type = zh_cn.utf-8
mlock = 0
morphology = none
min_word_len = 1 # 最小词匹配
html_strip = 0
charset_dictpath = /usr/local/mmseg3/etc/ #字典路径
ngram_len = 0
}
#全局index定义
indexer
{
mem_limit = 32M
}
#searchd服务定义
searchd
{
port = 9312
log = /var/sphinx/log/pai/searchd.log
query_log = /var/sphinx/log/pai/query.log
read_timeout = 5
max_children = 30
pid_file = /var/sphinx/log/pai/searchd.pid
max_matches = 1000
seamless_rotate = 1
preopen_indexes = 0
unlink_old = 1
compat_sphinxql_magics = 0
}
配置文件的每个具体的含义百度看下吧。。其实 sphinx的配置方法有好几个类别,这里才用最简单的,没包括什么增量索引啥的。
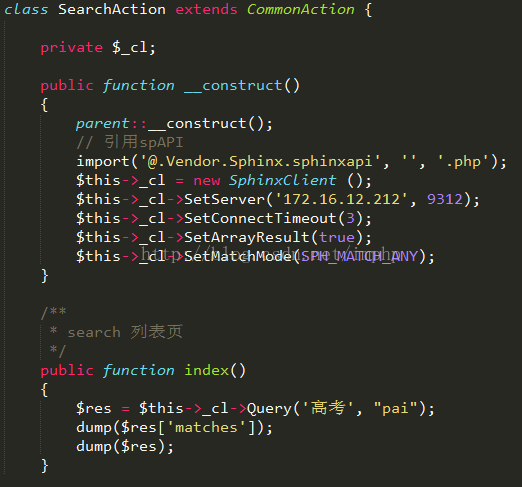
setup4.
thinkphp使用sphinxapi查询
这里以高考派的项目目录结构为例:
pai\App\Lib\Vendor\Sphinx
---- \
libsphinxclient
----
sphinxapi.php
好了、至此 一个最简单的sphinx服务 以及 api调用 就出来了~ 更多细节等待达人补充吧^_^















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









