







Centos7上部署RabbitMQ集群
简介:
RabbitMQ的Cluster集群模式一般分为两种,普通模式和镜像模式。消息队列通过rabbitmq HA镜像队列进行消息队列实体复制。
普通模式下,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。
镜像模式下,将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现RabbitMQ的HA高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。
部署说明:
这里是默认三台机器上已经部署了RabbitMQ单机,本文章只说明如何部署集群,单机部署请参考Centos7上RabbitMQ单机部署
部署方案:
1.部署规划
准备3台机器,我这里分别为:172.16.6.40,172.16.6.41,172.16.6.42,设置主机名分别为mem-40,mem-41,mem-42
2.配置hosts文件内容(三台机器上都需要配置,内容一样就可以,前面是IP,后面是各个主机的主机名)
vi /etc/hosts
172.16.6.40 mem-40
172.16.6.41 mem-41
172.16.6.42 mem-423.集群部署步骤
1.分别登录到三台机器,启动rabbitmq服务
rabbitmq-server -detached先启动一台,启动后会在用户的根目录下生成一个.erlang.cookie文件,然后把这个文件复制到其它机器的同样目录下,必须保证3台机器的cookie是一样的,然后再重启另外两台。
2.查看集群状态
[rabbitmq@mem-40 ~]$ rabbitmqctl cluster_status Cluster status of node 'rabbit@mem-40' ... [{nodes,[{disc,['rabbit@mem-40']}]}, {running_nodes,['rabbit@mem-40']}, 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 {cluster_name,<<"rabbit@mem-40">>}, {partitions,[]}, {alarms,[{'rabbit@mem-40',[]}]}] [rabbitmq@mem-40 ~]$从上面的结果{cluster_name,<<"rabbit@mem-40">>},可以看出来,集群的名称叫rabbit@mem-40
3.在mem-42主机上做如下操作,将该节点添加到集群(集群名称为上面查询到的名称:rabbit@mem-40)
#添加集群前需要先把本机的rabbitmq应用停掉(⚠️是只停应用) [rabbitmq@mem-42 ~]$ rabbitmqctl stop_app Stopping node 'rabbit@mem-42' ... #添加集群节点 [rabbitmq@mem-42 ~]$ rabbitmqctl join_cluster rabbit@mem-40 #再启动应用 [rabbitmq@mem-42 ~]$ rabbitmqctl start_app #查看集群状态 [rabbitmq@mem-42 ~]$ rabbitmqctl cluster_status Cluster status of node 'rabbit@mem-42' ... [{nodes,[{disc,['rabbit@mem-40','rabbit@mem-42']}]}, {running_nodes,['rabbit@mem-40','rabbit@mem-42']}, {cluster_name,<<"rabbit@mem-40">>}, {partitions,[]}, {alarms,[{'rabbit@mem-40',[]},{'rabbit@mem-42',[]}]}] [rabbitmq@mem-42 ~]$说明:
- 我们这里是把mem-42和mem-41这两个节点加到mem-40的集群中,需要先把mem-42和mem-41的应用节点停掉,才能添加集群,否则添加会失败
- rabbitmqctl stop是停止应用和集群节点,而rabbitmqctl stop_app是只停应用,不停集群节点,所以千万记住停应用节点是通过命令rabbitmqctl stop_app,而不是rabbitmqctl stop
4.在 mem-41上重复做步骤3的操作,将mem-41添加到集群(这里就不再赘述了)
添加完后就可以在任意节点上查看集群状态,如下,可以看到mem-40、mem-41、mem-42三台服务器都假如到同一个集群了:
[rabbitmq@mem-40 ~]$ rabbitmqctl cluster_status Cluster status of node 'rabbit@mem-40' ... [{nodes,[{disc,['rabbit@mem-40','rabbit@mem-41','rabbit@mem-42']}]}, {running_nodes,['rabbit@mem-42','rabbit@mem-40']}, {cluster_name,<<"rabbit@mem-40">>}, {partitions,[]}, {alarms,[{'rabbit@mem-42',[]},{'rabbit@mem-40',[]}]}] [rabbitmq@mem-40 ~]$至此,RabbitMQ集群的部署就完成了。后面我们还可以做一些方便集群管理相关的操作,比如导入管理界面、设置镜像队列策略、配置HA等。
4.导入管理界面
1.分别在三台机器上导入管理界面(也可以只在一台上做,这样就只有这一台可以通过web页面访问,但是可以看到其它服务器上的数据)
rabbitmq-plugins enable rabbitmq_managementrabbitMQ应用的端口默认是5672,导入管理界面后系统会启动15672端口作为web管理端口,这时候可以打开http://ip:15672来打开我们的管理界面,如下:
2.添加用户和密码,并设置权限(在任何一台上做就可以了,其它机器上会自动同步)
rabbitmqctl add_user admin 123456 #用户名admin,密码123456 rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*" #添加权限(使admin用户对虚拟主机“/” 具有所有权限) rabbitmqctl set_user_tags admin administrator #修改用户角色(加入administrator用户组)这样就可以通过admin用户登录管理界面,进行管理操作了。
5.设置镜像队列策略(在任意节点机器上执行)
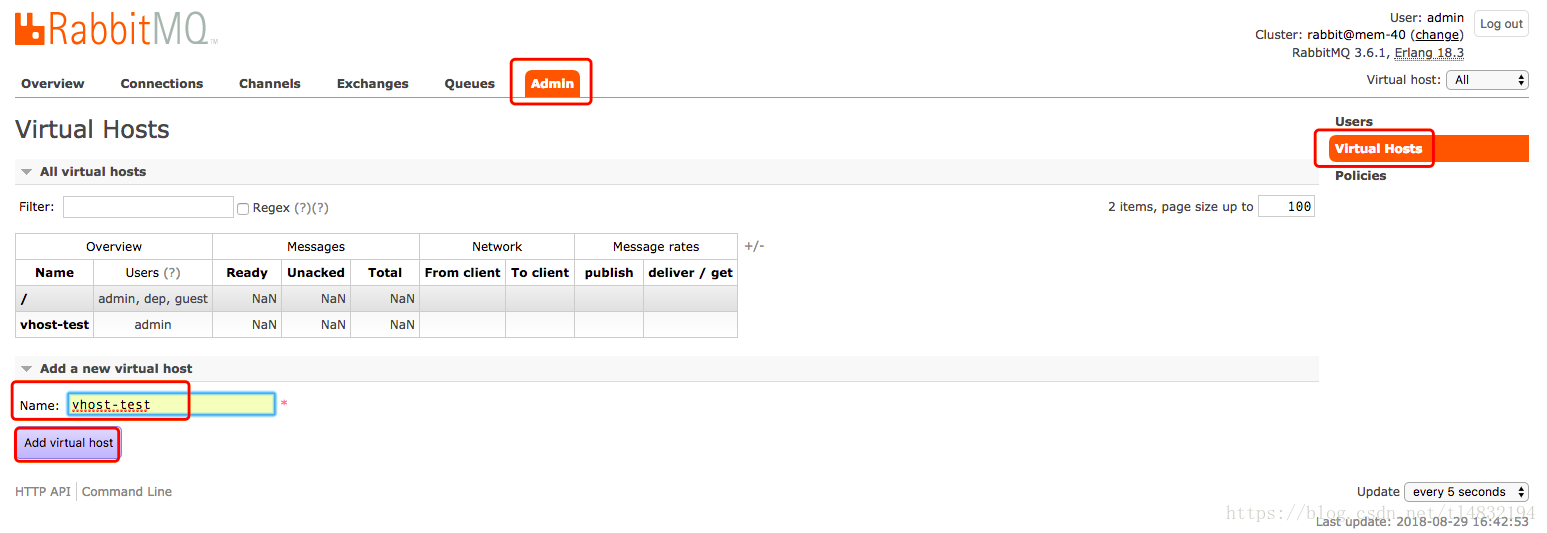
首先,在web界面,登陆后,点击“Admin--Virtual Hosts(页面右侧)”,在打开的页面上的下方的“Add a new virtual host”处增加一个虚拟主机,同时给用户“admin”和“guest”均加上权限(在页面直接设置、点点点即可);
然后,在linux中执行如下命令
rabbitmqctl set_policy -p vhost-test ha-all "^" '{"ha-mode":"all"}'"vhost-test" 为vhost名称, "^"匹配所有的队列, ha-all 策略名称为ha-all, '{"ha-mode":"all"}' 策略模式为 all 即复制到所有节点,包含新增节点。则此时镜像队列设置成功。
说明:这里的虚拟主机vhost-test是代码中需要用到的虚拟主机,虚拟主机的作用是做一个消息的隔离,本质上可认为是一个rabbitmq-server,是否增加虚拟主机,增加几个,这是由开发中的业务决定,即有哪几类服务,哪些服务用哪一个虚拟主机,这是一个规划)
这里补充一下设置镜像队列策略的说明,有兴趣的可以研究一下。
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority] -p Vhost: 可选参数,针对指定vhost下的queue进行设置 Name: policy的名称 Pattern: queue的匹配模式(正则表达式) Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes all:表示在集群中所有的节点上进行镜像 exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定 nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定 ha-params:ha-mode模式需要用到的参数 ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual priority:可选参数,policy的优先级
6.配置HA(可以用阿里的SLB去做负载均衡,这样就不用搭建HA了)
1.安装HA
任意选择一台机器安装HA,我这里选择mem-40这台机器
yum install haproxy修改配置文件(下面是我的全量配置文件,去掉了注释部分)
vi /etc/haproxy/haproxy.cfg
global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode tcp log global option tcplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 # 3次连接失败就认为服务不可用,也可以通过后面设置 timeout http-request 10s timeout queue 1m timeout connect 10s # 连接超时时间 timeout client 1m # 客户端连接超时时间 timeout server 1m # 服务器端连接超时时间 timeout http-keep-alive 10s timeout check 10s maxconn 3000 # 最大连接数 #管理页面的代理 listen rabbitmq_admin bind 0.0.0.0:8004 server node1 172.16.6.40:15672 server node2 172.16.6.41:15672 server node3 172.16.6.42:15672 #后台进程的代理 listen rabbitmq_cluster bind 0.0.0.0:5670 mode tcp balance roundrobin #负载均衡算法(#banlance roundrobin 轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数) server rabbit1 172.16.6.40:5672 check inter 5000 rise 2 fall 2 #check inter 5000 是检测心跳频率5s,rise 2是2次正确认为服务器可用,fall 2是2次失败认为服务器不可用 server rabbit2 172.16.6.41:5672 check inter 5000 rise 2 fall 2 server rabbit3 172.16.6.42:5672 check inter 5000 rise 2 fall 2 listen private_monitoring :8100 mode http option httplog stats enable stats uri /rabbitmqstats stats refresh 5s重启服务
systemctl restart haproxy这样后台可以用172.16.6.40:5670,web管理页面可以通过172.16.6.40:8004进行代理














 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









