









这条Hard的题目https://leetcode.com/problems/merge-k-sorted-lists/可以借鉴easy的这个题https://leetcode.com/problems/merge-two-sorted-lists/的思维方式(代码),参考这一篇:https://blog.csdn.net/To_be_to_thought/article/details/85057542
后者的非递归代码如下:
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if(l1==null)
return l2;
if(l2==null)
return l1;
ListNode head=null;
if(l1.val<l2.val)
{
head=l1;
l1=l1.next;
}
else
{
head=l2;
l2=l2.next;
}
ListNode p=head;
while(l1!=null && l2!=null)
{
if(l1.val<l2.val)
{
p.next=l1;
p=l1;
l1=l1.next;
}
else
{
p.next=l2;
p=l2;
l2=l2.next;
}
}
if(l1==null)
p.next=l2;
if(l2==null)
p.next=l1;
return head;
}
}递归代码如下:
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if(l1==null)
return l2;
if(l2==null)
return l1;
if(l1.val<l2.val)
{
l1.next=mergeTwoLists(l1.next,l2);
return l1;
}
else
{
l2.next=mergeTwoLists(l1,l2.next);
return l2;
}
}
}递归运行时间比非递归长,可能是因为递归函数的调用的时间开销。
再看这条题目,最朴素的思路就是:
思路一:就是将上一次归并的链表与下一个数组元素指向的链表头进行归并,代码如下:
class Solution {
public static ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if(l1==null)
return l2;
if(l2==null)
return l1;
ListNode head=null;
if(l1.val<l2.val)
{
head=l1;
l1=l1.next;
}
else
{
head=l2;
l2=l2.next;
}
ListNode p=head;
while(l1!=null && l2!=null)
{
if(l1.val<l2.val)
{
p.next=l1;
p=l1;
l1=l1.next;
}
else
{
p.next=l2;
p=l2;
l2=l2.next;
}
}
if(l1==null)
p.next=l2;
if(l2==null)
p.next=l1;
return head;
}
public ListNode mergeKLists(ListNode[] lists){
ListNode q=new ListNode(0);
for(int i=0;i<lists.length;i++)
{
q.next=mergeTwoLists(q.next,lists[i]);
}
return q.next;
}
}不难看出,里面存在较多的重复比较的过程,所以运行时间较长。
思路二:就是使用优先队列这种数据结构,优先队列的底层实现使用的堆数据结构(小顶堆),但java实现需要一个比较器:
class Solution {
public static Comparator<ListNode> MyComparator = new Comparator<ListNode>(){
@Override
public int compare(ListNode c1, ListNode c2) {
return c1.val-c2.val;
}
};
public ListNode mergeKLists(ListNode[] lists) {
PriorityQueue<ListNode> pq=new PriorityQueue<ListNode>(MyComparator);
for(ListNode l:lists)
{
if(l!=null)
pq.add(l);
}
ListNode p=new ListNode(0),q=p;
while(!pq.isEmpty())
{
q.next=pq.remove();
q=q.next;
if(q.next!=null)
pq.add(q.next);
}
return p.next;
}
}还有一种基于思路一的优化方案(参考的官方解答的思路):
思路三:利用类似于归并排序的思想进行自底向上的链表归并操作:回忆归并排序可以看看https://blog.csdn.net/To_be_to_thought/article/details/83988767,里面有几乎相同的代码块!!!
如图所示:
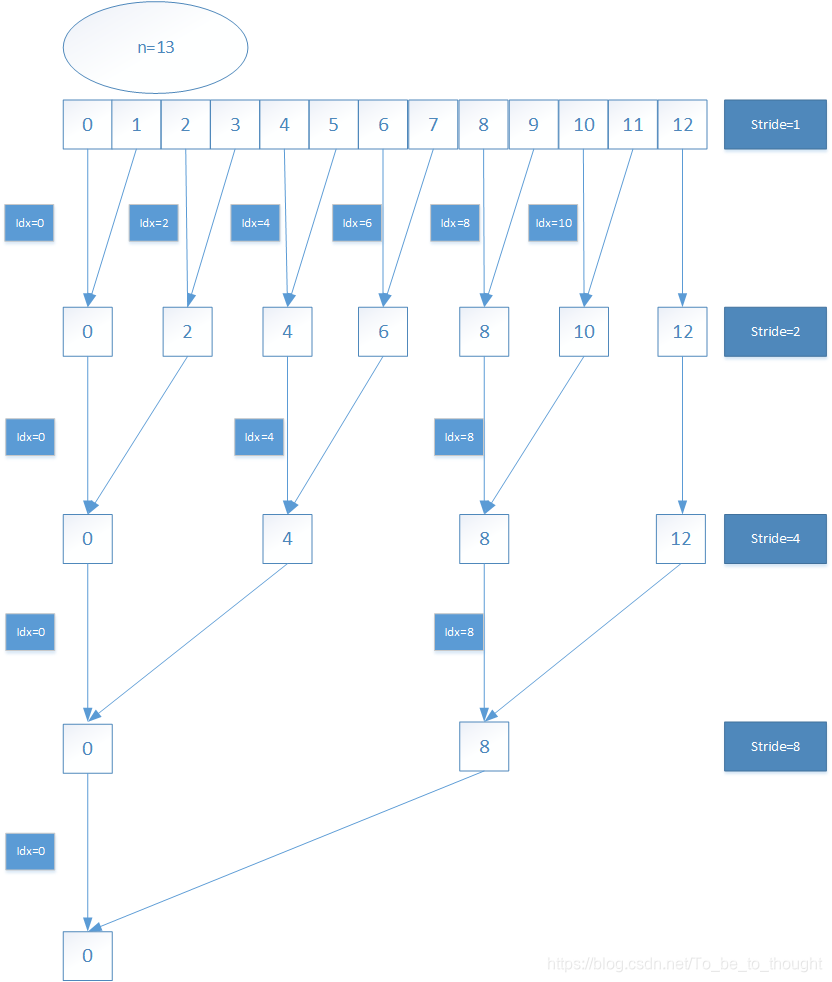
代码如下:
class Solution {
public static ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if(l1==null)
return l2;
if(l2==null)
return l1;
ListNode head=null;
if(l1.val<l2.val)
{
head=l1;
l1=l1.next;
}
else
{
head=l2;
l2=l2.next;
}
ListNode p=head;
while(l1!=null && l2!=null)
{
if(l1.val<l2.val)
{
p.next=l1;
p=l1;
l1=l1.next;
}
else
{
p.next=l2;
p=l2;
l2=l2.next;
}
}
if(l1==null)
p.next=l2;
if(l2==null)
p.next=l1;
return head;
}
public ListNode mergeKLists(ListNode[] lists){
if(lists.length==0)
return null;
int n = lists.length;
int stride = 1;
while(stride < n)
{
int idx = 0;
while(idx < n-stride)
{
lists[idx] = mergeTwoLists(lists[idx],lists[idx+stride]);
idx += 2*stride;
}
stride *= 2;
}
return lists[0];
}
}这次优化确实在思路一的基础上提高了不少性能,Beat100%!!!














 1061
1061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









