










作者Toby,原文来源公众号:python风控模型,论文解析_客户分组对商业银行个人信用评分模型的提升作用研究
经典分组模型论文
大家好,我是Toby老师,之前发布过文章《银行客户分群模型-customer segmentation model-更好提升模型预测能力》。今天会为大家解析一篇客户分群论文。2021年有篇经典论文《客户分组对商业银行个人信用评分模型的提升作用研究》发布。其作者在中国人民银行征信中心博士后工作站工作,发布过多篇金融风控相关论文,在此论文有较深研究,其论文有一定深度。各位学员可以多关注和学习。

此论文下载量较高,达到599。该论文得到国家三个基金资助,包括国家自然科学基金重点项目(71731003);国家自然科学基金项目(72071026); 中国博士后科学基金资助项目(2020M680804)

下面我简单解析一下论文经典地方。作者将总体样本进行分组,再对分组后的每个客群单独构建信用评分模型。作者采用 CART 决策树、模糊 C 均值聚类两种方法对样本数据中全部借款人进行客户分组,再对 分 组 后 的 每 个 客 群 进 行 WOE(Weight ofEvidence)数值转换和逻辑回归信用评分模型的构建,并采用模型性能指标AUC(Area Under Curve)、KS(Kolmogorov-Smirnov)进行模型对比,分析分组对于模型精度的影响,并比较无监督学习与有监督学习在分组模型中的优劣。
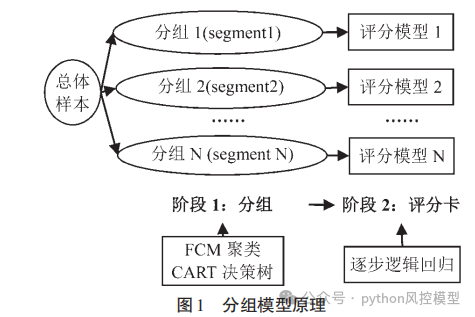
分组模型意义
实际建模中,很多建模人员往往只重视机器学习技术,算法本身,试图从多算法比较,调参来提高模型性能,而忽略了如何从业务方面提升模型性能。
市场细分是知识营销最重要的领域之一。在银行中,这确实是一项具有挑战性的任务,因为数据库庞大且多维。
分组在我们专业领域也可以称为分群。客户分组是信用评分模型开发的重要一环,即根据客户特点将样本划分为不同客群,再针对每个客群构建信用评分卡。相较于直接使用全样本构建的单一信用评分模型,分组后构建的信用评分模型可能在一定程度上提升评分模型的准确率。
数据选择和划分
作者选取美国网络借贷平台 Prosper 的个人贷款数据集,样本时间跨度为2011年7月至2014年 7 月,共 71 817 个样本。作者抽取 80%的样本为训练集,20%的样本为测试集,如表1所示。将逾期90天以上的样本作为违约坏客户,令 y=1;其余为好客户,令y=0。Prosper数据集之前Toby老师有发文章介绍《美国真正的p2p鼻祖-PROSPER金融科技公司-理想风控建模数据集》。金融领域很多人长期把lendingclub当成美国p2p鼻祖。真相是Prosper公司才是美国真正意义上p2p鼻祖。lendingclub只是名气更大,让人产生错觉。Prosper Marketplace, Inc.是一家位于加利福尼亚州旧金山的金融服务公司。Prosper Funding LLC 是其子公司之一,运营着 Prosper.com,这是一个个人可以申请借钱、开信用卡或投资个人贷款的网站。
Prosper数据集在我们公司《Python风控建模实战案例数据库》里可以找到。
CART分类(有监督学习)
作者用CART模型把客户分为4组结果。参数选择上,作者用基尼系数评估变量重要性,叶子节点最小样本数min_sample设为5000,depth深度设为3。
CART(Classification and Regression Trees)模型是一种决策树学习技术,用于分类和回归任务。CART模型通过递归地将数据集分割成越来越小的组(或节点),每个组内的样本在目标变量上具有高度的相似性。
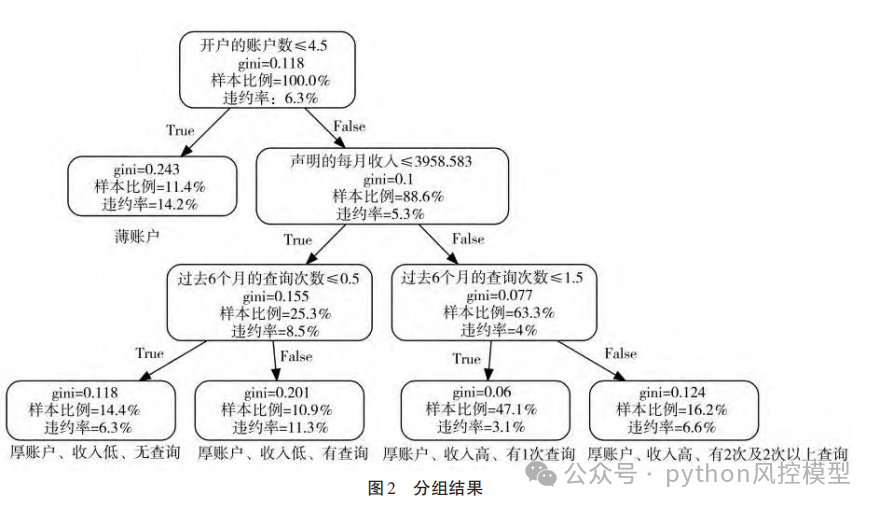
Toby老师补充一下CART更多细节,CART使用基尼不纯度(Gini impurity)或交叉熵作为分割标准。在回归问题中,CART使用均方误差(MSE)作为分割标准。CART通常使用成本复杂度剪枝(cost-complexity pruning),这是一种在构建树之后进行的剪枝方法,旨在优化模型的泛化能力。
'''
在这段代码中,我们使用了鸢尾花(Iris)数据集来训练和测试CART模型。我们创建了一个DecisionTreeClassifier对象,并指定了使用基尼不纯度(Gini index)作为分割标准。然后,我们训练模型并预测测试集,最后计算了模型的准确率。
代码问题反馈方式,QQ:231469242,微信:drug666123
'''
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建CART模型
cart_model = DecisionTreeClassifier(criterion='gini', random_state=42)
# 训练模型
cart_model.fit(X_train, y_train)
# 预测测试集
y_pred = cart_model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.4f}')模糊聚类Fuzzy Clustering(无监督学习)
作者使用模糊聚类方法,把数据集分为5组客群。提醒一下,模糊聚类之前,需要将数据进行归一化,本文采用“最大值最小值”方法将数据转化为 0 到 1 之间。
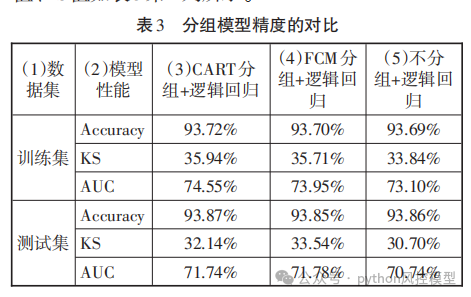
下图是作者采用模糊聚类(Fuzzy Clustering)后坏客户占比和样本比例。

实验结果来看,模糊聚类在测试集的AUC略高于cart算法,accuracy稍差。
模糊聚类(Fuzzy Clustering)是一种统计方法,用于将数据集中的样本划分为多个类别或簇,同时考虑到样本可能属于多个类别的程度。这种方法特别适用于处理具有不确定性或模糊性的分类问题。
基本原理
模糊聚类的核心思想是使用模糊集合理论来描述样本与类别之间的关系。在模糊聚类中,每个样本对于每个类别都有一个隶属度,表示样本属于该类别的程度。隶属度的取值范围在0到1之间,1表示完全属于该类别,0表示完全不属于。
常见算法
-
模糊C均值聚类(Fuzzy C-Means, FCM):
-
这是最常用的模糊聚类算法之一。它通过迭代优化一个目标函数来确定样本的隶属度和类别中心。算法的目标是最小化样本与类别中心之间的加权距离的平方和。作者论文中使用的就是此方法。
-
-
模糊C中心聚类(Fuzzy C-Centroid):
-
与FCM类似,但更侧重于类别中心的确定。
-
-
模糊C均值聚类算法的改进版本:
-
包括模糊C均值聚类算法的多种改进版本,如模糊C均值聚类算法的改进版本,它们通过引入不同的距离度量、隶属度函数或优化策略来提高聚类性能 .
-
Python:使用scikit-fuzzy库可以实现模糊聚类(Fuzzy Clustering)
'''
pip install scikit-fuzzy
在这段代码中,我们首先生成了一些随机数据作为示例。然后,我们定义了模糊聚类的参数,包括聚类个数、隶属度的幂指数、误差阈值和最大迭代次数。接着,我们使用cluster.cmeans函数执行模糊C均值聚类,并绘制了聚类结果。
请注意,这个示例代码提供了一个基本的框架,你可能需要根据实际的数据集和问题进行调整。此外,你可以尝试不同的参数(如n_clusters和m)来观察聚类效果的变化。
代码问题反馈方式,QQ:231469242,微信:drug666123
'''
import numpy as np
import matplotlib.pyplot as plt
from skfuzzy import cluster
# 创建一些随机数据
data = np.random.rand(100, 2)
# 定义模糊聚类的参数
n_clusters = 3 # 聚类个数
m = 2 # 隶属度的幂指数
error = 0.005 # 误差阈值
maxiter = 1000 # 最大迭代次数
# 执行模糊C均值聚类
cntr, u, u0, d, jm, p, fpc = cluster.cmeans(data, n_clusters, m, error=error, maxiter=maxiter, init=None)
# 绘制聚类结果
plt.scatter(data[:, 0], data[:, 1], c=p[:, 0], cmap='viridis', edgecolor='k', s=50, alpha=0.5)
plt.scatter(cntr[:, 0], cntr[:, 1], c='red', s=200, edgecolor='k', marker='x') # 聚类中心
plt.title('Fuzzy C-Means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()实战中分群模型更复杂
上述论文《客户分组对商业银行个人信用评分模型的提升作用研究》只给我们展示了部分实验数据,并没有显示所有数据。实战中分群模型更复杂,分群模型并不一定能提升模型性能。有时候可以,有时候反而更低。这取决于分类方法,变量选择和数据分布。
样本分群后,也不意味着每个分群子模型性能都能得到提高。Toby老师在分群模型实验中发现,部分分群子模型性能可以提高,其它子模型会降低。
在大量实验中,有监督学习的模型效果会明显高于无监督学习模型,此论文的结论不一定适用于其它数据集,泛化能力有待进一步验证。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









