







我们已经讲解了HashMap的实现原理,LinkedHashMap是HashMap的子类,在其基础上实现了元素的排序功能,接下来对LinkedHashMap的实现进行一个了解。
目录
-
底层数据结构
LinkedHashMap就是实现了LRU(Least Recent Use, 最近最少使用)排序的HashMap,LinkedHashMap就是在HashMap的基础上,在Entry<key,value>对象中添加了before和after两个指针,构成一个双向链表(最少使用的在head,最多使用的在tail),用来存储元素的访问顺序(get和put都算访问),这个双向链表的重要操作就是,当访问了一个元素,那么把他从双向链表中删除,并把它放进双向链表的表头。
LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。
LinkedHashMap的节点定义如下:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}我了便于理解,我们对LinkedHashMap做如下操作:
插入a——>插入b——>插入c——>访问a
那么我们可以得到按照访问顺序来说,排序应该是:b、c、a
此时的LinkedHashMap的结构如下:
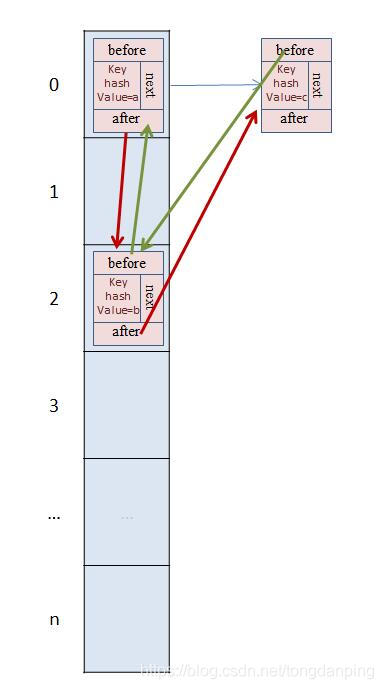
LinkedHashMap定义了排序模式accessOrder,该属性为boolean型变量,对于访问顺序,为true;对于插入顺序,则为false。
LinkedHashMap的处理思路如下:除了像HashMap一样插入和查询节点,还需要维护循环双向链表,accessOrder为true则双向链表维护访问顺序,我们认为get和put操作都是访问操作,也就是说这两个操作需要对双向链表进行操作。那么是如何对双向链表进行处理的呢?当有相关访问操作时,在双向链表中删掉当前节点,并将当前节点添加到双向链表的尾部。
-
查询操作get()
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)//getNode直接继承父类的getNode方法
return null;
if (accessOrder)//按访问顺序排序
afterNodeAccess(e);//对双向链表进行操作,将节点e移到双向链表的尾部
return e.value;
}那么 afterNodeAccess(Node<K,V> e)是怎么实现的呢?以下代码和注释进行了说明:
void afterNodeAccess(Node<K,V> e) { // move node to last即把最常用的放到last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;//因为要把p放到最后,因此p.after是null
if (b == null)//如果p在head(最前面),那么去掉p以后p.after变成head
head = a;
else
b.after = a;//否则b直接链接a
if (a != null)
a.before = b;//如果p在链表中间,那么去掉p以后b直接链接a
else
last = b;//如果p已经在最后,那么去掉p以后last变成b
//以上代码是删掉p,接下来开始把p插到链表尾部
if (last == null)
head = p;//如果链表中只有p一个节点,那么删掉p以后则没有节点,此时last==null,重新插入p节点为head
else {//否则将p放在链表尾部即可
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}-
插入操作put()/putAll()
LinkedHashMap并没有重写HashMap的put()方法,那么他是如何处理双向链表的呢?
通过HashMap的put方法可以看出,其中又两个方法afterNodeAccess(e)和afterNodeInsertion(evict),这两个方法在HashMap中是空方法,在LinkedHashMap中被重写(afterNodeAccess方法在上方)。
afterNodeInsertion(evict)方法的作用:如果removeEldestEntry返回true,表示map的容量一定,在插入一个节点的时候,如果map满了,就需要删掉最少访问的一个节点(first),通过重写removeEldestEntry方法可以实现自定义的 LRU 缓存。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//显然在LinkedHashMap中默认是不删除最少使用的节点的
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}afterNodeAccess(e)方法的作用是:调整双向链表的节点顺序。
但是有一个问题就是,put方法并没有重写,那么插入的节点是HashMap的节点还是LinkedHashMap的节点呢?可以发现,在HashMap的put()方法中调用newNode()方法来构造节点,而LinkedHashMap重写了改方法,因此在LinkedHashMap中调用put()方法时构造的是LinkedHashMap的节点。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);//将当前node添加到双向链表的尾部
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)//如果last==null说明链表为空,那么直接降p放到head
head = p;
else {
p.before = last;
last.after = p;
}
}-
删除remove()方法
同样的,删除方法也是继承自HashMap, 只是重写了afterNodeRemoval(node)方法以便实现双向链表的节点删除操作
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}













 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









