






图像识别、文字识别,这些都是现在比较火的东西,现在大部分的AI都有在做这些东西,那我们就过来了解一下吧!
只需要四行代码,完成从图片中读取图片中的文字!
准备工作:
我们需要两个安装包,先来安装一下:
pip install pillow

pip install pytesseract

安装完之后,我们需要下载Tesseract-OCR这个软件,这里我已经将东西都打包好了放在百度云中,大家可以直接下载:
链接:
https://pan.baidu.com/s/1osNf95ScZJYhtzsGFLtxaA
密码:
npmn
打开安装包,一路next
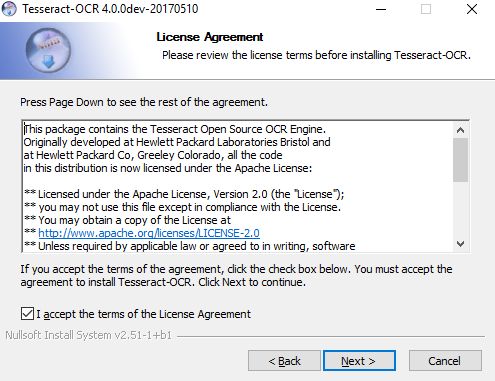
记录好自己的安装路径
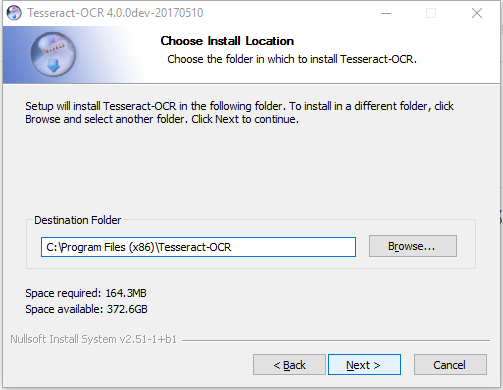
安装完之后找到tessdata目录下,将下载的chi_sim.traineddata文件放到该目录下。这样它就能识别中文了。
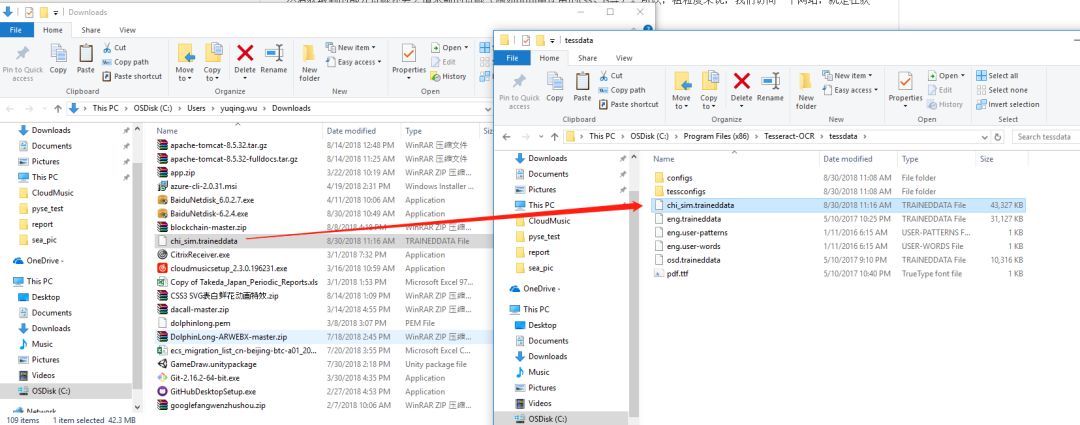
之后,我们只剩下一个东西要配一下了,在pytesseract模块中的pytesseract.py文件中去配置一下Tesseract-OCR的工作目录,这个时候我们可以通过刚刚pip安装的位置找到pytesseract.py文件,如下图:

进入目录找到pytesseract.py文件并且打开它:
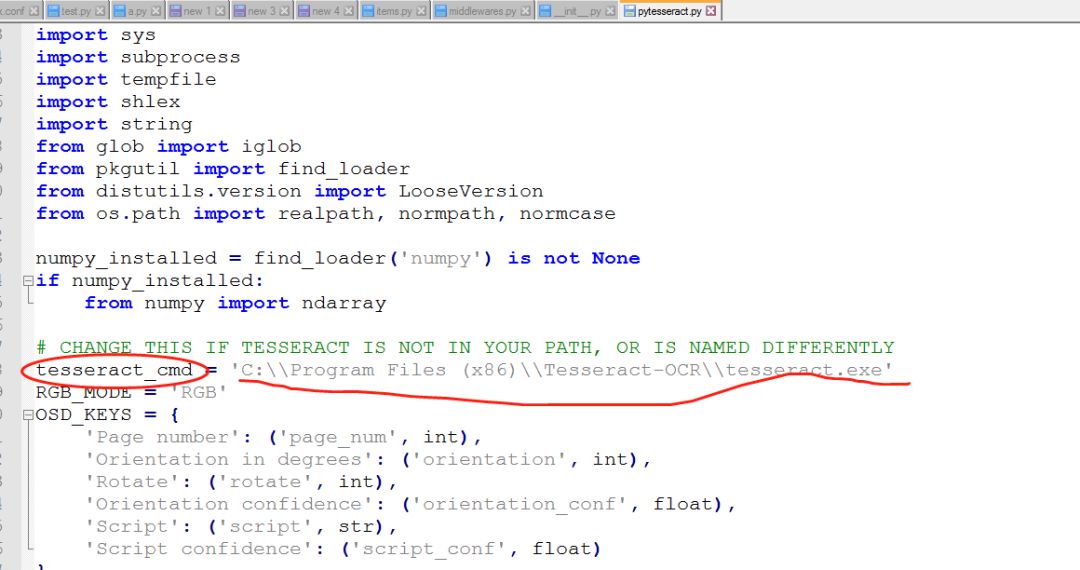
将tesseract_cmd这个变量的值改成Tesseract-OCR的安装目录即可。
现在,我们在准备一张图片,用来识别,小编就用微信截图好了,放置在桌面文件夹上:

开始代码:
到这里,我们所有的预备环境以及全部搭建好了,下面我们就开始来敲代码咯:

from PIL import Image
import pytesseract
pic_content=pytesseract.image_to_string(Image.open('C:\\Users\\yuqing.wu\\Desktop\\all\\3.png'),lang='chi_sim')
print(pic_content)
我们来看看运行结果:

结果还是比较准的。
大家也来试试吧!
像这样的图像识别还是挺重要、挺常用的,例如图片验证码等等,都是可以去完成的,就看大家怎么去用了!

感兴趣的扫个二维码吧!














 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









