







前言.Spark简介和hadoop的区别
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
1.架构不同。
Hadoop是对大数据集进行分布式计算的标准工具。提供了包括工具和技巧在内的丰富的生态系统,允许使用相对便宜的商业硬件集群进行超级计算机级别的计算。
Spark使用函数式编程范式扩展了MapReduce编程模型以支持更多计算类型,可以涵盖广泛的工作流。且需要一个第三方的分布式存储系统作为依赖。
2.处理对象不同
Spark处理数据的方式不一样,会比MapReduce快上很多。MapReduce是分步对数据进行处理的: 从集群中读取数据,进行一次处理,将结果写到集群,从集群中读取更新后的数据,进行下一次的处理,将结果写到集群,反观Spark,它会在内存中以接近“实时”的时间完成所有的数据分析:从集群中读取数据,完成所有必须的分析处理,将结果写回集群.所以Hadoop适合处理静态数据,而Spark适合对流数据进行分析。
3.速度
Spark基于内存:Spark使用内存缓存来提升性能,因此进行交互式分析也足够快速(就如同使用Python解释器,与集群进行交互一样)。缓存同时提升了迭代算法的性能,这使得Spark非常适合数据理论任务,特别是机器学习。
Hadoop基于磁盘:MapReduce要求每隔步骤之间的数据要序列化到磁盘,这意味着MapReduce作业的I/O成本很高,导致交互分析和迭代算法(iterative algorithms)开销很大。而事实是,几乎所有的最优化和机器学习都是迭代的。
4.灾难恢复
Hadoop将每次处理后的数据都写入到磁盘上,所以其天生就能很有弹性的对系统错误进行处理。
Spark的数据对象存储在分布于数据集群中的叫做弹性分布式数据集(RDD: Resilient Distributed Dataset)中。这些数据对象既可以放在内存,也可以放在磁盘,所以RDD同样也可以提供完成的灾难恢复功能。
一.环境准备
jdk 1.8.0
hadoop2.7.2 伪分布式部署
scala 2.12.1 支持spark2.0.1及以上版本
spark2.0.1
二.Spark安装模式(本文伪分布式)
spark有以下几种安装模式,每种安装模式都有自己不同的优点和长处。
local(本地模式):
常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
standalone(集群模式):
典型的Mater/slave模式,Master可能有单点故障的;Spark支持ZooKeeper来实现 HA。
on yarn(集群模式):
运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。
on mesos(集群模式):
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。
on cloud(集群模式):
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3。
目前Apache Spark支持三种分布式部署方式,分别是standalone、Spark on mesos和 spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架,比如MapReduce,公用一个集群资源,最大的好处是降低运维成本和提高资源利用率(资源按需分配)。
三.安装scala
1.上传scala包,解压缩
2.配置环境变量SCALA_HOME
3.source /etc/profile使得生效
4.验证scala安装情况
scala -version
及上scala 安装完成
[注意]:集群环境全部分属于santiago用户如下图
四.伪分布式Spark安装部署
1 解压spark安装包,并配置SPARK_HOME环境变量,最后用 source使之生效。
2 更改配置 在/usr/local/spark-2.0.1/conf 下
(1)cp slaves.template slaves
vim hdp(主机名)
(2)cp spark-env.sh.template spark-env.sh
vim spark-env.sh
进行以下配置
export JAVA_HOME=/usr/local/jdk1.8.0
export SCALA_HOME=/usr/local/scala-2.12.1
export SPARK_WORKER_MEMORY=1G
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.137.133
3 启动spark
(1)先启动hadoop 环境
/usr/local/hadoop/sbin# start-all.sh
(2)启动spark环境
/usr/local/spark-2.0.1/sbin# ./start-all.sh
[注] 如果使用start-all.sh时候会重复启动hadoop配置,需要./在当前工作目录下执行脚本文件。
jps 观察进程 多出 worker 和 mater 两个进程
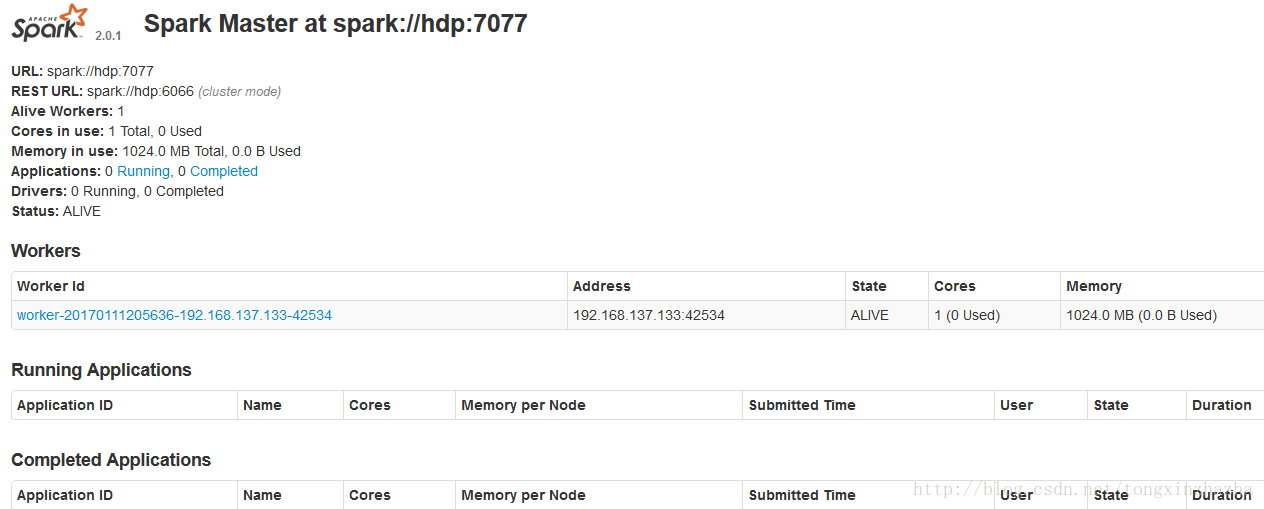
查看spark的web控制页面
http://192.168.137.133:8080/
显示spark的端口是7070
进入交互/bin/spark-shell
查看sparl-shell web界面
http://192.168.137.133:4040/jobs/
五.Spark测试
1.在HDFS上建立目录
hadoop fs -mkdir -p /usr/hadoop
hadoop fs -ls /usr/ 可以查看
hadoop fs -mkdir -p /usr/data/input 建立文件夹input
将本地目录传送到HDFS上
hadoop fs -put /home/santiago/data/spark/spark_test.txt /usr/data/input
2测试spark

观察job网页
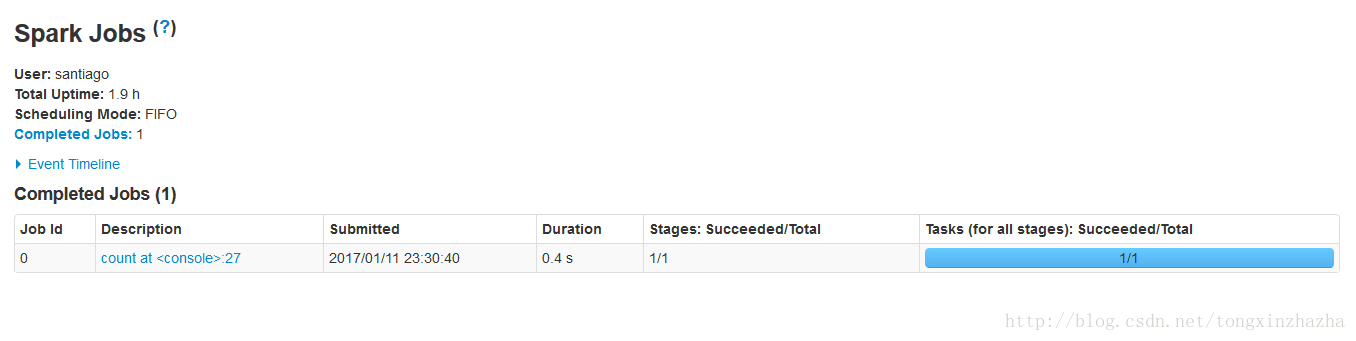
配置成功
[注意]
1. spark处理HDFS的文件
2.查看spark的web控制页面 spark集群的web端口:8080
http://192.168.137.133:8080/
3.查看sparl-shell web界面 spark-job监控端口:4040
http://192.168.137.133:4040/jobs/
参考文献
http://www.myexception.cn/cloud/1846423.html
http://www.myexception.cn/cloud/2001019.html
www.36dsj.com/archives/8001














 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









