









Spring-data-elasticsearch是Spring提供的操作ElasticSearch的数据层,封装了大量的基础操作,通过它可以很方便的操作ElasticSearch的数据。
版本说明
ElasticSearch目前最新的已到5.5.1
| spring data elasticsearch | elasticsearch |
|---|---|
| 3.0.0.RC1 | 5.5.0 |
| 3.0.0.M4 | 5.4.0 |
| 2.0.4.RELEASE | 2.4.0 |
| 2.0.0.RELEASE | 2.2.0 |
| 1.4.0.M1 | 1.7.3 |
| 1.3.0.RELEASE | 1.5.2 |
| 1.2.0.RELEASE | 1.4.4 |
| 1.1.0.RELEASE | 1.3.2 |
| 1.0.0.RELEASE | 1.1.1 |
这有一个对应关系,不过不太完整,我目前使用的SpringBoot版本1.5.4对应的spring-data-ElasticSearch是2.1.4,在图上就没有体现。
但是可以预见对应的ElasticSearch应该在2.4.*往上,但应该是不支持5.4.0及以上。
注意:我这篇例子,所使用的ElasticSearch版本就是最新的5.5.1,SpringBoot版本是1.5.4,经初步试验,插入及查询都没问题。估计是5.5.*的新特性之类的会无法使用,基本操作应该都没问题。
ElasticSearchRepository的基本使用
- @NoRepositoryBean
- public interface ElasticsearchRepository<T, ID extends Serializable> extends ElasticsearchCrudRepository<T, ID> {
- <S extends T> S index(S var1);
- Iterable<T> search(QueryBuilder var1);
- Page<T> search(QueryBuilder var1, Pageable var2);
- Page<T> search(SearchQuery var1);
- Page<T> searchSimilar(T var1, String[] var2, Pageable var3);
- void refresh();
- Class<T> getEntityClass();
- }
我们是通过继承ElasticsearchRepository来完成基本的CRUD及分页操作的,和普通的JPA没有什么区别。
ElasticsearchRepository继承了ElasticsearchCrudRepository extends PagingAndSortingRepository.
先看看普通查询:
- public interface BookRepository extends Repository<Book, String> {
- List<Book> findByNameAndPrice(String name, Integer price);
- List<Book> findByNameOrPrice(String name, Integer price);
- Page<Book> findByName(String name,Pageable page);
- Page<Book> findByNameNot(String name,Pageable page);
- Page<Book> findByPriceBetween(int price,Pageable page);
- Page<Book> findByNameLike(String name,Pageable page);
- @Query("{\"bool\" : {\"must\" : {\"term\" : {\"message\" : \"?0\"}}}}")
- Page<Book> findByMessage(String message, Pageable pageable);
- }
插入数据也很简单:
- @Autowired
- private SampleElasticsearchRepository repository;
- String documentId = "123456";
- SampleEntity sampleEntity = new SampleEntity();
- sampleEntity.setId(documentId);
- sampleEntity.setMessage("some message");
- repository.save(sampleEntity);
- @Autowired
- private SampleElasticsearchRepository repository;
- String documentId = "123456";
- SampleEntity sampleEntity1 = new SampleEntity();
- sampleEntity1.setId(documentId);
- sampleEntity1.setMessage("some message");
- String documentId2 = "123457"
- SampleEntity sampleEntity2 = new SampleEntity();
- sampleEntity2.setId(documentId2);
- sampleEntity2.setMessage("test message");
- List<SampleEntity> sampleEntities = Arrays.asList(sampleEntity1, sampleEntity2);
- //bulk index
- repository.save(sampleEntities);
特殊情况下,ElasticsearchRepository里面有几个特殊的search方法,这些是ES特有的,和普通的JPA区别的地方,用来构建一些ES查询的。
主要是看QueryBuilder和SearchQuery两个参数,要完成一些特殊查询就主要看构建这两个参数。
我们先来看看它们之间的类关系
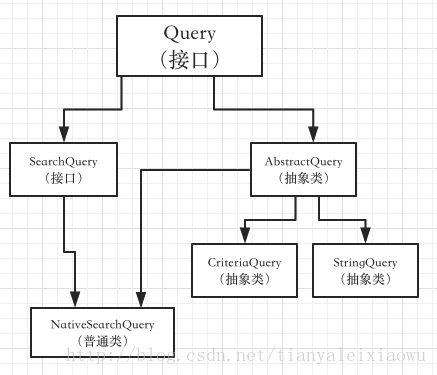
从这个关系中可以看到ES的search方法需要的参数SearchQuery是一个接口,有一个实现类叫NativeSearchQuery,实际使用中,我们的主要任务就是构建NativeSearchQuery来完成一些复杂的查询的。

我们可以看到要构建NativeSearchQuery,主要是需要几个构造参数
- public NativeSearchQuery(QueryBuilder query, QueryBuilder filter, List<SortBuilder> sorts, Field[] highlightFields) {
- this.query = query;
- this.filter = filter;
- this.sorts = sorts;
- this.highlightFields = highlightFields;
- }
可以看出来,大概是需要QueryBuilder,filter,和排序的SortBuilder,和高亮的字段。
一般情况下,我们不是直接是new NativeSearchQuery,而是使用NativeSearchQueryBuilder。
通过NativeSearchQueryBuilder.withQuery(QueryBuilder1).withFilter(QueryBuilder2).withSort(SortBuilder1).withXXXX().build();这样的方式来完成NativeSearchQuery的构建。
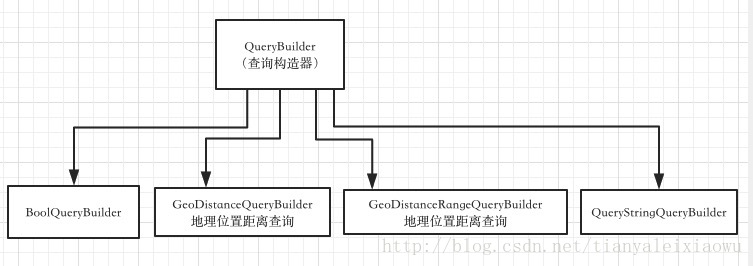

从名字就能看出来,QueryBuilder主要用来构建查询条件、过滤条件,SortBuilder主要是构建排序。
譬如,我们要查询距离某个位置100米范围内的所有人、并且按照距离远近进行排序:
- double lat = 39.929986;
- double lon = 116.395645;
- Long nowTime = System.currentTimeMillis();
- //查询某经纬度100米范围内
- GeoDistanceQueryBuilder builder = QueryBuilders.geoDistanceQuery("address").point(lat, lon)
- .distance(100, DistanceUnit.METERS);
- GeoDistanceSortBuilder sortBuilder = SortBuilders.geoDistanceSort("address")
- .point(lat, lon)
- .unit(DistanceUnit.METERS)
- .order(SortOrder.ASC);
- Pageable pageable = new PageRequest(0, 50);
- NativeSearchQueryBuilder builder1 = new NativeSearchQueryBuilder().withFilter(builder).withSort(sortBuilder).withPageable(pageable);
- SearchQuery searchQuery = builder1.build();
- SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.queryStringQuery("spring boot OR 书籍")).build();
要构建SortBuilder,可以使用SortBuilders来完成各种排序。
然后就可以通过NativeSearchQueryBuilder来组合这些QueryBuilder和SortBuilder,再组合分页的参数等等,最终就能得到一个SearchQuery了。
至此,我们明白了ElasticSearchRepository里那几个search查询方法需要的参数的含义和构建方式了。
ElasticSearchTemplate的使用
ElasticSearchTemplate更多是对ESRepository的补充,里面提供了一些更底层的方法。

这里主要是一些查询相关的,同样是构建各种SearchQuery条件。
也可以完成add操作
- String documentId = "123456";
- SampleEntity sampleEntity = new SampleEntity();
- sampleEntity.setId(documentId);
- sampleEntity.setMessage("some message");
- IndexQuery indexQuery = new IndexQueryBuilder().withId(sampleEntity.getId()).withObject(sampleEntity).build();
- elasticsearchTemplate.index(indexQuery);

构建这个对象,主要是设置一下id,就是你的对象的id,Object就是对象本身,indexName和type就是在你的对象javaBean上声明的

其他的字段自行发掘含义,构建完IndexQuery后就可以通过Template的index方法插入了。
template里还有各种deleteIndex,delete,update等方法,用到的时候就查查看吧。
下面讲一个批量插入的方法,我们经常需要往ElasticSearch中插入大量的测试数据来完成测试搜索,一条一条插肯定是不行的,ES提供了批量插入数据的功能——bulk。
前面讲过JPA的save方法也可以save(List)批量插值,但适用于小数据量,要完成超大数据的插入就要用ES自带的bulk了,可以迅速插入百万级的数据。
在ElasticSearchTemplate里也提供了对应的方法
- public void bulkIndex(List<IndexQuery> queries) {
- BulkRequestBuilder bulkRequest = this.client.prepareBulk();
- Iterator var3 = queries.iterator();
- while(var3.hasNext()) {
- IndexQuery query = (IndexQuery)var3.next();
- bulkRequest.add(this.prepareIndex(query));
- }
- BulkResponse bulkResponse = (BulkResponse)bulkRequest.execute().actionGet();
- if (bulkResponse.hasFailures()) {
- Map<String, String> failedDocuments = new HashMap();
- BulkItemResponse[] var5 = bulkResponse.getItems();
- int var6 = var5.length;
- for(int var7 = 0; var7 < var6; ++var7) {
- BulkItemResponse item = var5[var7];
- if (item.isFailed()) {
- failedDocuments.put(item.getId(), item.getFailureMessage());
- }
- }
- throw new ElasticsearchException("Bulk indexing has failures. Use ElasticsearchException.getFailedDocuments() for detailed messages [" + failedDocuments + "]", failedDocuments);
- }
- }
- public void bulkUpdate(List<UpdateQuery> queries) {
- BulkRequestBuilder bulkRequest = this.client.prepareBulk();
- Iterator var3 = queries.iterator();
- while(var3.hasNext()) {
- UpdateQuery query = (UpdateQuery)var3.next();
- bulkRequest.add(this.prepareUpdate(query));
- }
- BulkResponse bulkResponse = (BulkResponse)bulkRequest.execute().actionGet();
- if (bulkResponse.hasFailures()) {
- Map<String, String> failedDocuments = new HashMap();
- BulkItemResponse[] var5 = bulkResponse.getItems();
- int var6 = var5.length;
- for(int var7 = 0; var7 < var6; ++var7) {
- BulkItemResponse item = var5[var7];
- if (item.isFailed()) {
- failedDocuments.put(item.getId(), item.getFailureMessage());
- }
- }
- throw new ElasticsearchException("Bulk indexing has failures. Use ElasticsearchException.getFailedDocuments() for detailed messages [" + failedDocuments + "]", failedDocuments);
- }
- }
- public void bulkIndex(List<Person> personList) {
- int counter = 0;
- try {
- if (!elasticsearchTemplate.indexExists(PERSON_INDEX_NAME)) {
- elasticsearchTemplate.createIndex(PERSON_INDEX_TYPE);
- }
- List<IndexQuery> queries = new ArrayList<>();
- for (Person person : personList) {
- IndexQuery indexQuery = new IndexQuery();
- indexQuery.setId(person.getId() + "");
- indexQuery.setObject(person);
- indexQuery.setIndexName(PERSON_INDEX_NAME);
- indexQuery.setType(PERSON_INDEX_TYPE);
- //上面的那几步也可以使用IndexQueryBuilder来构建
- //IndexQuery index = new IndexQueryBuilder().withId(person.getId() + "").withObject(person).build();
- queries.add(indexQuery);
- if (counter % 500 == 0) {
- elasticsearchTemplate.bulkIndex(queries);
- queries.clear();
- System.out.println("bulkIndex counter : " + counter);
- }
- counter++;
- }
- if (queries.size() > 0) {
- elasticsearchTemplate.bulkIndex(queries);
- }
- System.out.println("bulkIndex completed.");
- } catch (Exception e) {
- System.out.println("IndexerService.bulkIndex e;" + e.getMessage());
- throw e;
- }
- }
OK,这篇主要是讲一些ElasticSearchRepository和ElasticSearchTemplate的用法,构造QueryBuilder的方式。下一篇用实例来看一下,在百万或者更大量级的数据中查询距离某个坐标100米范围内的所有数据。

















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









