







1. 手动分区实践
手动分区的实践,本文的仅拿Zabbix的TRENDS表作为讲解,要对其他表做分区,是一样的套路。 还有,在做这些操作前,请停止上层应用(Zabbix),如果是线上环境,请在合规的时间进行操作。
1.1 对现有表重命名,做好备份
语法
- 语法1:ALTER TABLE table_name RENAME TO new_table_name;
- 语法2:RENAME table_name TO new_table_name;
ALTER TABLE TRENDS RENAME TO TRENDS_OLD_TEMP;
1.2 重新建表(range分区)
范围分区,以列的值(此处以CLOCK)的范围来做为分区的划分条件
-- 创建表
create table TRENDS
(
ITEMID NUMBER(20) not null,
CLOCK NUMBER(10) default '0' not null,
NUM NUMBER(10) default '0' not null,
VALUE_MIN NUMBER(20,4) default '0.0000' not null,
VALUE_AVG NUMBER(20,4) default '0.0000' not null,
VALUE_MAX NUMBER(20,4) default '0.0000' not null
)partition by range (CLOCK)(
partition P_MAX values less than (MAXVALUE)
);
-- 创建/重新创建主键约束、唯一约束和外键约束
alter table TRENDS add primary key (ITEMID, CLOCK) using index
range分区是应用最广的分区方式,它是以列的值(此处以CLOCK)的范围来做为分区的划分条件,将记录存放到列值所在的 range 分区中,因此在创建的时候,需要指定基于的列,以及分区的范围值,如果某些记录暂无法预测范围,可以创建 maxvalue 分区(此处就是这个方式,分区名叫P_MAX),所有不在指定范围内的记录都会被存储到 maxvalue 所在分区中,并且支持多列做为依赖列。每个分区内储存的数据小于该分区指定的values less than数值,除第一个分区外,其它分区都有最小值且等于上一分区指定的values less than数值。
1.3 (可选)如果原来的数据还要的话,可以将 TRENDS_OLD_TEMP 表里的数据迁移到 TRENDS 表中
insert into TRENDS select * from TRENDS_OLD_TEMP;
COMMIT;
1.4 (可选)如果TRENDS_OLD_TEMP表不要了,就可以删掉
drop table trends_old_temp;
1.4 将RANGE分区划分为两个分区
- 参考:
-- 前面那个sql生成id,然后替换进去
select ZBX_ORACLE.ORACLE_TO_UNIX(to_date('2022-12-07','yyyy-mm-dd')) from dual;
-- 时间和分区保持一致
alter table ZBX_ORACLE.HISTORY_UINT split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.HISTORY split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.HISTORY_TEXT split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.TRENDS_UINT split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.TRENDS split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.HISTORY_LOG split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.HISTORY_STR split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.ALERTS split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.EVENTS split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
alter table ZBX_ORACLE.AUDITLOG split partition P_MAX at(1670342400) into (partition P_20221207,partition P_MAX) update global indexes;
- 实战:
-- 1)创建好ORACLE_TO_UNIX函数
CREATE OR REPLACE FUNCTION ORACLE_TO_UNIX(in_date IN DATE) return number is
begin
return( (in_date -TO_DATE('19700101','yyyymmdd'))*86400 - TO_NUMBER(SUBSTR(TZ_OFFSET(sessiontimezone),1,3))*3600);
end oracle_to_unix;
-- 2)执行下面的sql生成id,本次为1670428800
select ORACLE_TO_UNIX(to_date('2022-12-08','yyyy-mm-dd')) from dual;
-- 3)将上一步得到的id:1670428800传入at()函数,时间和分区名保持一致,这里是P_20221208
alter table TRENDS split partition P_MAX at(1670428800) into (partition P_20221208,partition P_MAX) update global indexes;
1.5 查询分区表
select segment_name,segment_type,partition_name, sum(bytes)/1024/1024/1024 GB
from dba_segments
where owner = 'ZBX5_USER'
and partition_name like 'P_%'
group by segment_name,segment_type,partition_name;
2. 存储过程+定时任务 实现自动表分区的操作
说明:在本次使用的存储过程代码中,有使用到相关函数和额外的表,需提前创建好。
2.1 创建有调用到的函数
CREATE OR REPLACE FUNCTION date_to_unix_ts( p_date IN DATE )
RETURN number
IS
l_number number(10);
BEGIN
l_number := to_number((p_date - to_date('1970-01-01','YYYY-MM-DD')) * (24*60*60));
RETURN l_number;
END;
2.2 创建有使用到的表
-- Create table
create table T_PART_MAINTAIN_ERR
(
ER_DATE DATE,
ER_TAB VARCHAR2(30),
ER_PARTNAME VARCHAR2(30),
ER_OPT VARCHAR2(20),
ER_CODE VARCHAR2(20),
ER_MSG VARCHAR2(60)
);
-- Create/Recreate indexes
create index IX_T_PART_MAIN_ERR_DATE on T_PART_MAINTAIN_ERR (ER_DATE);
2.3 创建存储过程
请注意创建顺序。
- 1)按天创建分区的存储过程:p_create_partition
create or replace procedure p_create_partition(p_tab in varchar2,p_partname in varchar2,p_clock in number)
as
v_tabname varchar2(30);
v_partname varchar2(30);
v_clock number;
v_sql varchar2(1000);
v_count integer;
v_sqlcode varchar2(20);
v_sqlmsg varchar2(60);
begin
v_tabname := upper(p_tab);
v_partname := upper(p_partname);
v_clock := p_clock;
v_count :=0;
select count(*) into v_count from user_tab_partitions
where table_name = v_tabname
and partition_name = v_partname;
if v_count = 0
then
v_sql := 'alter table '||v_tabname||' split partition p_max at('||v_clock||') into ( partition '||v_partname||',partition p_max) update global indexes';
execute immediate v_sql;
end if;
EXCEPTION
WHEN OTHERS
THEN
v_sqlcode := substr(SQLCODE,1,20);
v_sqlmsg := substr(SQLERRM,1,60);
insert into t_part_maintain_err values(sysdate,v_tabname,v_partname,'create partition',v_sqlcode,v_sqlmsg);
commit;
end;
- 2)生成时间和检查分区是否存在等功能的存储过程:p_create_next_partitions
create or replace procedure p_create_next_partitions(p_tabname in varchar2)
as
v_date date;
v_tabname varchar2(30);
v_partname varchar2(30);
v_clock number;
v_clock_date date;
v_total_days integer;
v_day integer;
v_sqlcode varchar2(20);
v_sqlmsg varchar2(60);
begin
v_total_days := 7;
v_date := sysdate;
v_tabname := p_tabname;
for v_day in 1..v_total_days
loop
v_date := trunc(sysdate + v_day);
v_partname := 'p_'||to_char(v_date,'YYYYMMDD');
v_clock_date := trunc(v_date + 1);
v_clock := date_to_unix_ts(v_clock_date);
p_create_partition(v_tabname,v_partname,v_clock);
end loop;
EXCEPTION
WHEN OTHERS
THEN
v_sqlcode := substr(SQLCODE,1,20);
v_sqlmsg := substr(SQLERRM,1,60);
insert into t_part_maintain_err values(sysdate,v_tabname,v_partname,'call create partition',v_sqlcode,v_sqlmsg);
commit;
end;
- 3)总调度存储过程:p_maintain_partitions
create or replace procedure p_maintain_partitions
as
v_sqlcode varchar2(20);
v_sqlmsg varchar2(60);
begin
p_create_next_partitions('TRENDS');
EXCEPTION
WHEN OTHERS
THEN
v_sqlcode := substr(SQLCODE,1,20);
v_sqlmsg := substr(SQLERRM,1,60);
insert into t_part_maintain_err values(sysdate,' ',' ','p_maintain_partitions',v_sqlcode,v_sqlmsg);
commit;
end;
说明,以后通过存储过程来对其他表进行创建分区,只需要在总调度的存储过程(p_maintain_partitions)中,增加 p_create_next_partitions(‘XXXX’);,比如要增加HISTORY表,p_create_next_partitions(‘HISTORY’)。但在这之前,请确保HISTORY这个表已经是range分区的表,可参考本文中的1.2小节。
2.4 创建定时任务
疑问:存储过程创建好,要编译吗?还是说,存储过程创建好,就可以创job了?答案:会自动编译的
下面对创建jon的sql语句进行简单说明,如下:
variable job number;
begin
sys.dbms_job.submit(job => :job,
what => 'p_maintain_partitions;',
next_date => to_date('06-12-2022 09:00:00', 'dd-mm-yyyy hh24:mi:ss'),
interval => 'trunc(sysdate)+1+9/24');
commit;
end;
/
to_date的说明:定时任务是每台早上9点钟执行。to_date函数中的年月日可以改,比如改成当前的日期,如果当前日期的时间已经过了早上9点,则会马上执行这个定时任务,如果日期改成当前日期的明天,那么将会在明天的9点执行该定时任务。 疑问:最下面个 / 不要了吧?答案:要的,在命令行执行,那个是提交。
下面开始在命令行上执行:
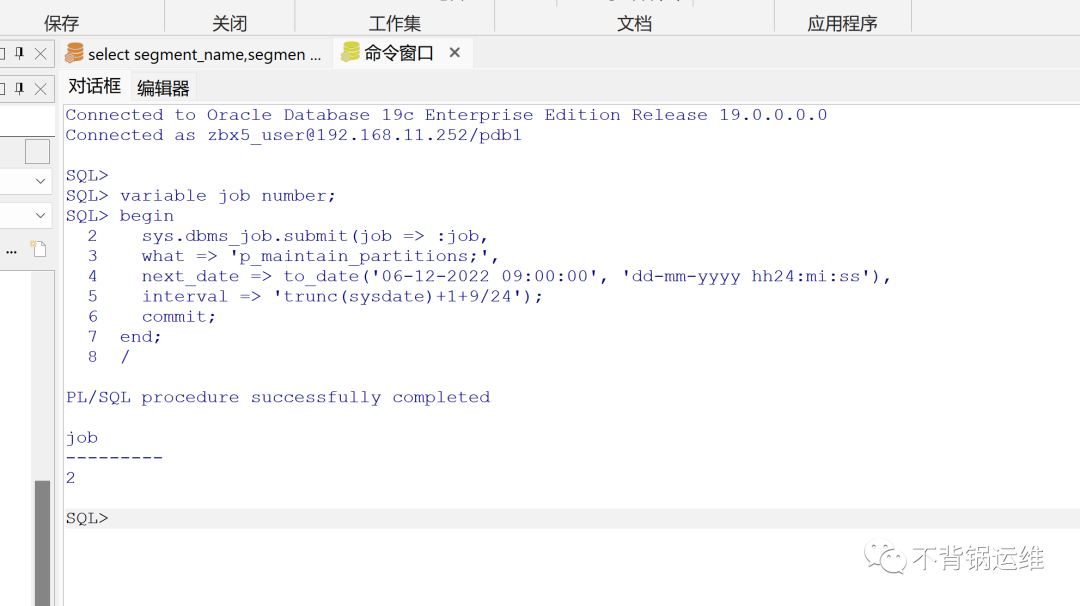
根据数据库组专家对to_date的说明,我创建job后并没有马上执行,于是手动运行了一次,
鼠标右击这个job,选择“运行”
运行后,再次查询表分区
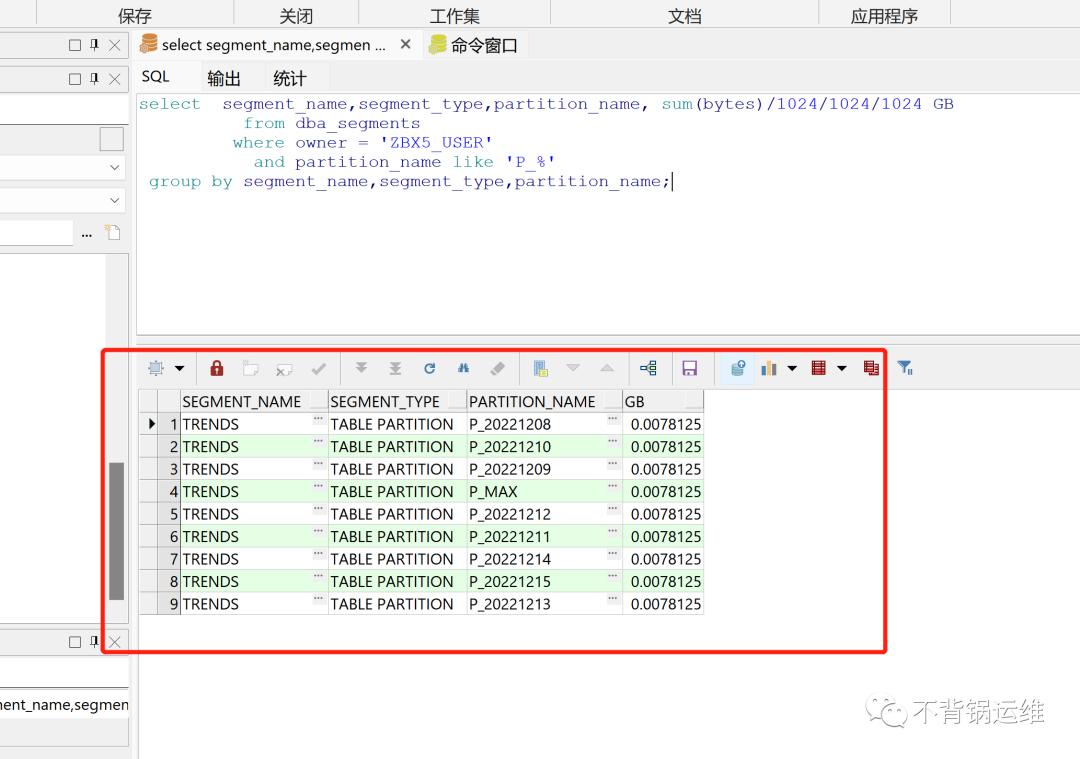
已经创建了未来7天的分区,当天的那个(P_20221208)是我手动创建的,经验证,存储过程不会创建当天的分区。
3. 分区表常用管理
查询表的分区
select segment_name,segment_type,partition_name, sum(bytes)/1024/1024/1024 GB
from dba_segments
where owner = 'ZBX5_USER'
and partition_name like 'P_%'
group by segment_name,segment_type,partition_name;
手动删除分区
alter table TRENDS drop partition P_20221208 update global indexes;
本文转载于(喜欢的盆友关注我们):https://mp.weixin.qq.com/s/VWPcaaiHo11u7O_0nnmWHQ















 4197
4197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









