






- RNN的结构。循环神经网络的提出背景、优缺点。着重学习RNN的反向传播、RNN出现的问题(梯度问题、长期依赖问题)、BPTT算法。
- 双向RNN3
- LSTM、GRU的结构、提出背景、优缺点。
- 针对梯度消失(LSTM等其他门控RNN)、梯度爆炸(梯度截断)的解决方案。
- Text-RNN的原理。
- 利用Text-RNN模型来进行文本分类。
1.RNN的结构
1.1 RNN
RNNs的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:
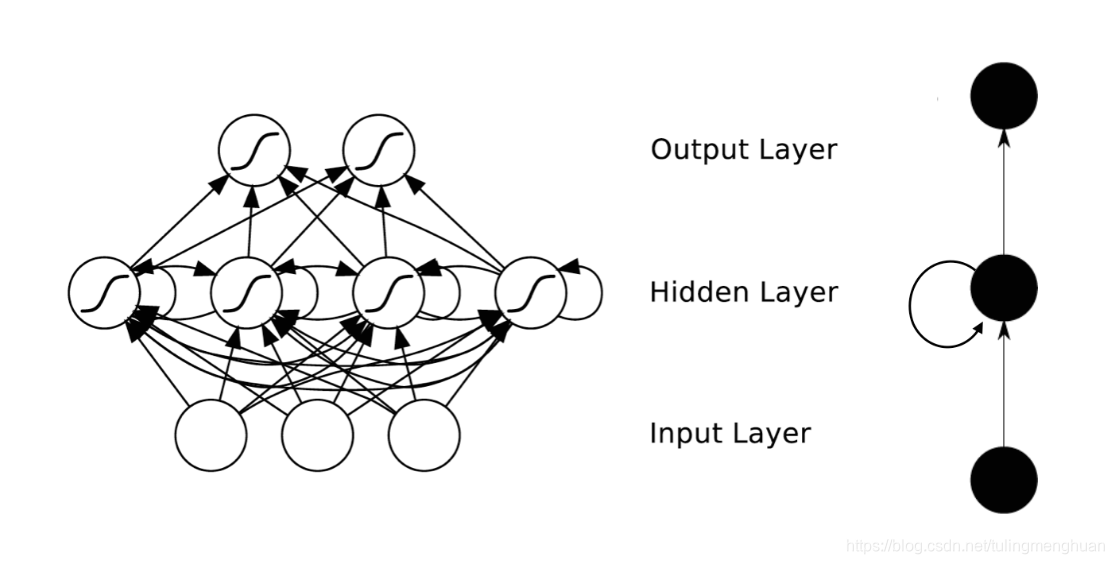
RNNs包含输入单元(Input units),输入集标记为,而输出单元(Output units)的输出集则被标记为。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为,这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
1.2 RNN的反向传播
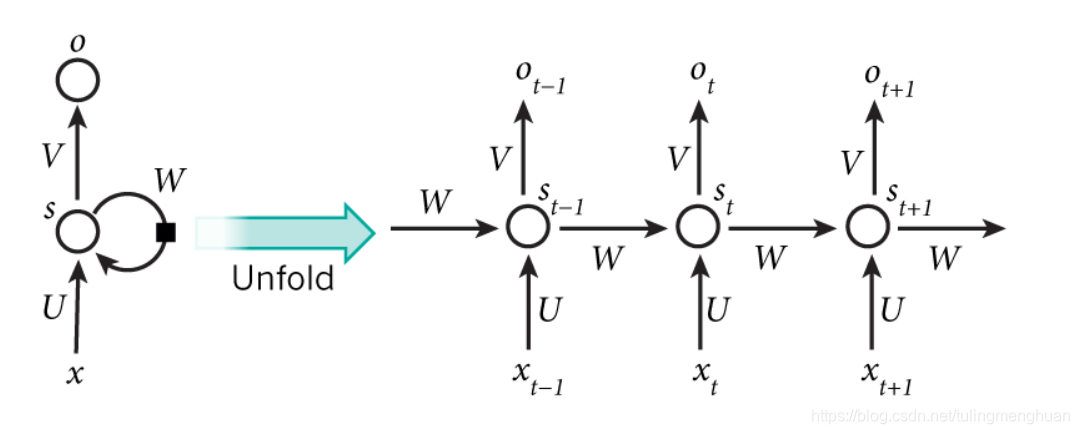
这幅图描述了在序列索引号tt
附近RNN的模型。其中:
1)x(t)代表在序列索引号t时训练样本的输入。同样的,x(t−1)和x(t+1)
代表在序列索引号t−1和t+1时训练样本的输入。
2)h(t)代表在序列索引号t时模型的隐藏状态。h(t)由x(t)和h(t−1)共同决定。
3)o(t)代表在序列索引号t时模型的输出。o(t)只由模型当前的隐藏状态h(t)决定。
4)L(t)代表在序列索引号t时模型的损失函数。
5)y(t)代表在序列索引号t时训练样本序列的真实输出。
6)U,W,V这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
RNN前向传播算法
对于任意一个序列索引号tt,我们隐藏状态h(t)由x(t)和h(t−1)得到:
h
(
t
)
=
σ
(
z
(
t
)
)
=
σ
(
U
x
(
t
)
+
W
h
(
t
−
1
)
+
b
)
h^{(t)} = \sigma(z^{(t)}) = \sigma(Ux^{(t)} + Wh^{(t-1)} +b )
h(t)=σ(z(t))=σ(Ux(t)+Wh(t−1)+b)
其中σσ为RNN的激活函数,一般为tanhtanh, bb为线性关系的偏倚。
序列索引号tt时模型的输出o(t)的表达式比较简单:
o
(
t
)
=
V
h
(
t
)
+
c
o^{(t)} = Vh^{(t)} +c
o(t)=Vh(t)+c
在最终在序列索引号tt时我们的预测输出为:
y
^
(
t
)
=
σ
(
o
(
t
)
)
\hat{y}^{(t)} = \sigma(o^{(t)})
y^(t)=σ(o(t))
通常由于RNN是识别类的分类模型,所以上面这个激活函数一般是softmax。
通过损失函数L(t),比如对数似然损失函数,我们可以量化模型在当前位置的损失,即
y
(
t
)
{y}^{(t)}
y(t)和
y
(
t
)
{y}^{(t)}
y(t)的差距。
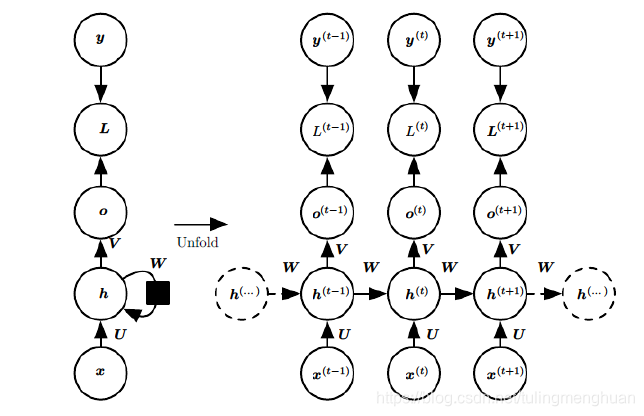
RNN反向传播算法
RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮的迭代,得到合适的RNN模型参数U,W,V,b,cU,W,V,b,c。由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time)。当然这里的BPTT和DNN也有很大的不同点,即这里所有的U,W,V,b,c在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
为了简化描述,这里的损失函数我们为交叉熵损失函数,输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。
对于RNN,由于我们在序列的每个位置都有损失函数,因此最终的损失LL为:
L
=
∑
t
=
1
τ
L
(
t
)
L = \sum\limits_{t=1}^{\tau}L^{(t)}
L=t=1∑τL(t)
其中V,c的梯度计算是比较简单的:
∂
L
∂
c
=
∑
t
=
1
τ
∂
L
(
t
)
∂
c
=
∑
t
=
1
τ
∂
L
(
t
)
∂
o
(
t
)
∂
o
(
t
)
∂
c
=
∑
t
=
1
τ
y
^
(
t
)
−
y
(
t
)
\frac{\partial L}{\partial c} = \sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial c} = \sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial c} = \sum\limits_{t=1}^{\tau}\hat{y}^{(t)} - y^{(t)}
∂c∂L=t=1∑τ∂c∂L(t)=t=1∑τ∂o(t)∂L(t)∂c∂o(t)=t=1∑τy^(t)−y(t)
∂
L
∂
V
=
∑
t
=
1
τ
∂
L
(
t
)
∂
V
=
∑
t
=
1
τ
∂
L
(
t
)
∂
o
(
t
)
∂
o
(
t
)
∂
V
=
∑
t
=
1
τ
(
y
^
(
t
)
−
y
(
t
)
)
(
h
(
t
)
)
T
\frac{\partial L}{\partial V} =\sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial V} = \sum\limits_{t=1}^{\tau}\frac{\partial L^{(t)}}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial V} = \sum\limits_{t=1}^{\tau}(\hat{y}^{(t)} - y^{(t)}) (h^{(t)})^T
∂V∂L=t=1∑τ∂V∂L(t)=t=1∑τ∂o(t)∂L(t)∂V∂o(t)=t=1∑τ(y^(t)−y(t))(h(t))T
但是W,U,b的梯度计算就比较的复杂了。从RNN的模型可以看出,在反向传播时,在在某一序列位置t的梯度损失由当前位置的输出对应的梯度损失和序列索引位置t+1时的梯度损失两部分共同决定。对于W在某一序列位置t的梯度损失需要反向传播一步步的计算。我们定义序列索引t位置的隐藏状态的梯度为:
δ
(
t
)
=
∂
L
∂
h
(
t
)
\delta^{(t)} = \frac{\partial L}{\partial h^{(t)}}
δ(t)=∂h(t)∂L
δ
(
t
)
=
∂
L
∂
o
(
t
)
∂
o
(
t
)
∂
h
(
t
)
+
∂
L
∂
h
(
t
+
1
)
∂
h
(
t
+
1
)
∂
h
(
t
)
=
V
T
(
y
^
(
t
)
−
y
(
t
)
)
+
W
T
δ
(
t
+
1
)
d
i
a
g
(
1
−
(
h
(
t
+
1
)
)
2
)
\delta^{(t)} =\frac{\partial L}{\partial o^{(t)}} \frac{\partial o^{(t)}}{\partial h^{(t)}} + \frac{\partial L}{\partial h^{(t+1)}}\frac{\partial h^{(t+1)}}{\partial h^{(t)}} = V^T(\hat{y}^{(t)} - y^{(t)}) + W^T\delta^{(t+1)}diag(1-(h^{(t+1)})^2)
δ(t)=∂o(t)∂L∂h(t)∂o(t)+∂h(t+1)∂L∂h(t)∂h(t+1)=VT(y^(t)−y(t))+WTδ(t+1)diag(1−(h(t+1))2)
对于δ(τ)δ(τ),由于它的后面没有其他的序列索引了,因此有:
δ
(
τ
)
=
∂
L
∂
o
(
τ
)
∂
o
(
τ
)
∂
h
(
τ
)
=
V
T
(
y
^
(
τ
)
−
y
(
τ
)
)
\delta^{(\tau)} =\frac{\partial L}{\partial o^{(\tau)}} \frac{\partial o^{(\tau)}}{\partial h^{(\tau)}} = V^T(\hat{y}^{(\tau)} - y^{(\tau)})
δ(τ)=∂o(τ)∂L∂h(τ)∂o(τ)=VT(y^(τ)−y(τ))
有了δ(t),计算W,U,b就容易了,这里给出W,U,b的梯度计算表达式:
∂
L
∂
W
=
∑
t
=
1
τ
∂
L
∂
h
(
t
)
∂
h
(
t
)
∂
W
=
∑
t
=
1
τ
d
i
a
g
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
(
h
(
t
−
1
)
)
T
\frac{\partial L}{\partial W} = \sum\limits_{t=1}^{\tau}\frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial W} = \sum\limits_{t=1}^{\tau}diag(1-(h^{(t)})^2)\delta^{(t)}(h^{(t-1)})^T
∂W∂L=t=1∑τ∂h(t)∂L∂W∂h(t)=t=1∑τdiag(1−(h(t))2)δ(t)(h(t−1))T
∂
L
∂
b
=
∑
t
=
1
τ
∂
L
∂
h
(
t
)
∂
h
(
t
)
∂
b
=
∑
t
=
1
τ
d
i
a
g
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
\frac{\partial L}{\partial b}= \sum\limits_{t=1}^{\tau}\frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial b} = \sum\limits_{t=1}^{\tau}diag(1-(h^{(t)})^2)\delta^{(t)}
∂b∂L=t=1∑τ∂h(t)∂L∂b∂h(t)=t=1∑τdiag(1−(h(t))2)δ(t)
∂
L
∂
U
=
∑
t
=
1
τ
∂
L
∂
h
(
t
)
∂
h
(
t
)
∂
U
=
∑
t
=
1
τ
d
i
a
g
(
1
−
(
h
(
t
)
)
2
)
δ
(
t
)
(
x
(
t
)
)
T
\frac{\partial L}{\partial U} = \sum\limits_{t=1}^{\tau}\frac{\partial L}{\partial h^{(t)}} \frac{\partial h^{(t)}}{\partial U} = \sum\limits_{t=1}^{\tau}diag(1-(h^{(t)})^2)\delta^{(t)}(x^{(t)})^T
∂U∂L=t=1∑τ∂h(t)∂L∂U∂h(t)=t=1∑τdiag(1−(h(t))2)δ(t)(x(t))T
1.3RNN出现的问题(梯度问题、长期依赖问题)
对于V求偏导不存在依赖问题;但是对于L,U求偏导的时候,由于时间序列长度,存在长期依赖的情况。 St会随着时间序列向前传播,同时 St是 L,U 的函数。
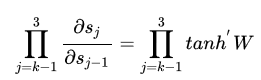
当激活函数是tanh函数时,tanh函数的导数最大值为1,又不可能一直都取1这种情况,而且这种情况很少出现.大部分都是小于1的数在做累乘,若当 很大的时候,最后累乘的结果趋向0,这是RNN中梯度消失的原因
上式中,除了需要参数tanh,还需要网络参数W ,如果参数W中的值太大,随着序列长度同样存在长期依赖的情况,那么产生问题就是梯度爆炸,而不是梯度消失了。
2双向RNN
Bidirectional recurrent neural networks在1997年由Mike Schuster等提出。
2.1 结构
BRNN的idea是将传统RNN的状态神经元拆分为两个部分,一个负责positive time direction(forward states),另一个负责negative time direction(backward states)。Forward states的输出并不会连接到Backward states的输入。因此结构如下所示。如果没有backward layer的话就跟传统RNN相同了。
这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一个时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。
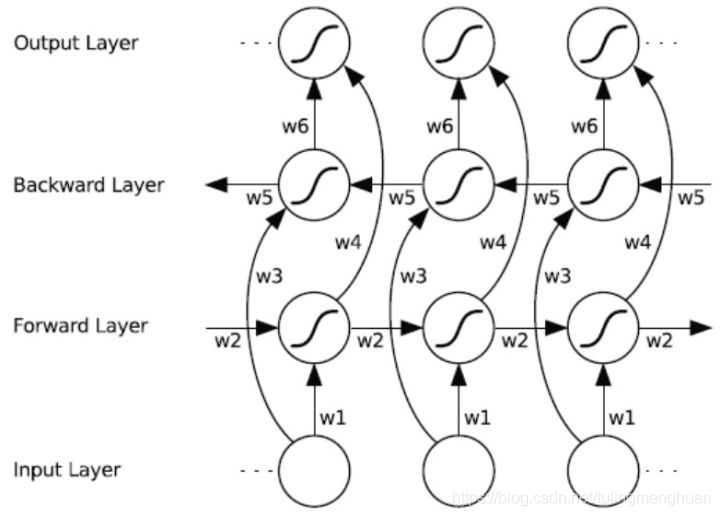
2.2训练
BRNN同样采用BPTT的算法,只是稍微有一点不同
前向传播

后向传播

3. LSTM、GRU的结构、提出背景、优缺点
3.1 LSTM的结构
RNN的结构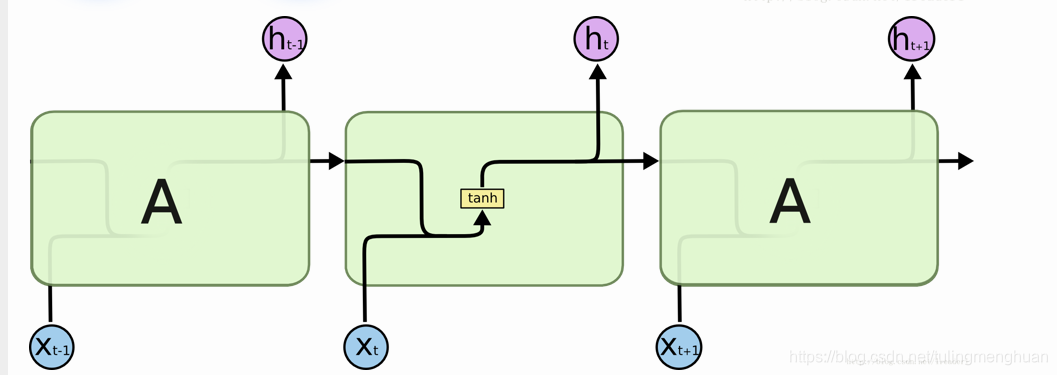
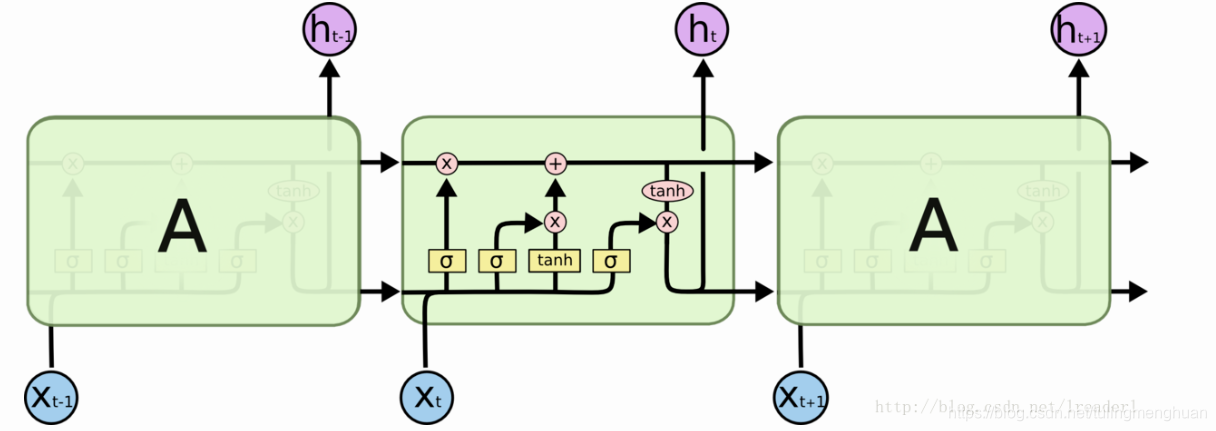
标准LSTM模型是一种特殊的RNN类型,在每一个重复的模块中有四个特殊的结构,以一种特殊的方式进行交互。在图中,每一条黑线传输着一整个向量,粉色的圈代表一种pointwise 操作(将定义域上的每一点的函数值分别进行运算),诸如向量的和,而黄色的矩阵就是学习到的神经网络层。
LSTM模型的核心思想是“细胞状态”。“细胞状态”类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
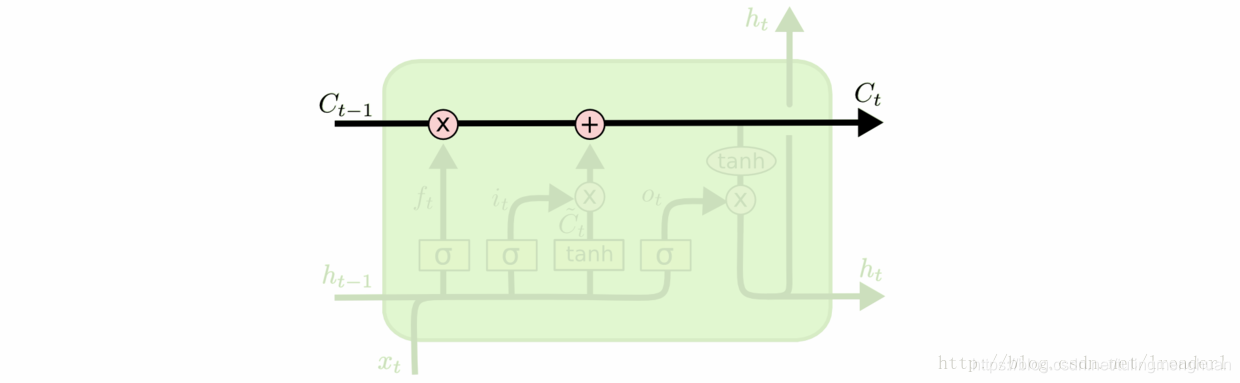
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”。LSTM 拥有三个门,来保护和控制细胞状态。
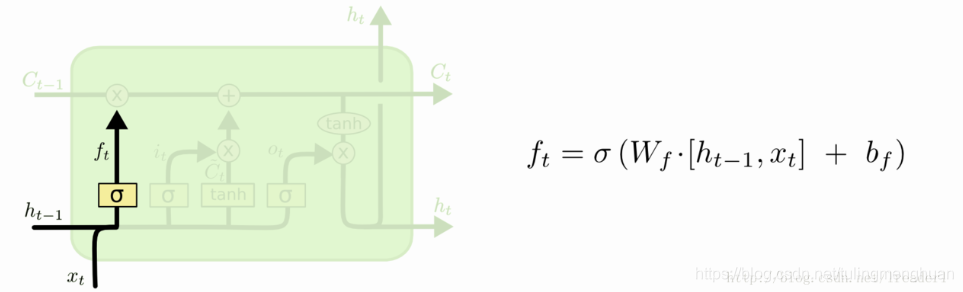
在LSTM模型中,第一步是决定我们从“细胞”中丢弃什么信息,这个操作由一个忘记门层来完成。该层读取当前输入x和前神经元信息h,由ft来决定丢弃的信息。输出结果1表示“完全保留”,0 表示“完全舍弃”。
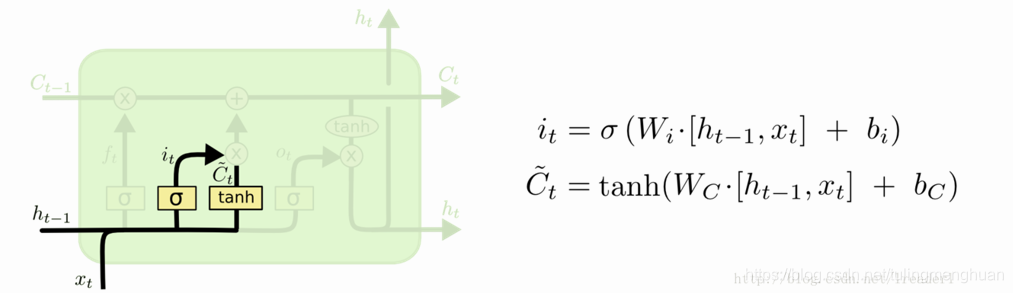
第二步是确定细胞状态所存放的新信息,这一步由两层组成。sigmoid层作为“输入门层”,决定我们将要更新的值i;tanh层来创建一个新的候选值向量~Ct加入到状态中。在语言模型的例子中,我们希望增加新的主语到细胞状态中,来替代旧的需要忘记的主语。
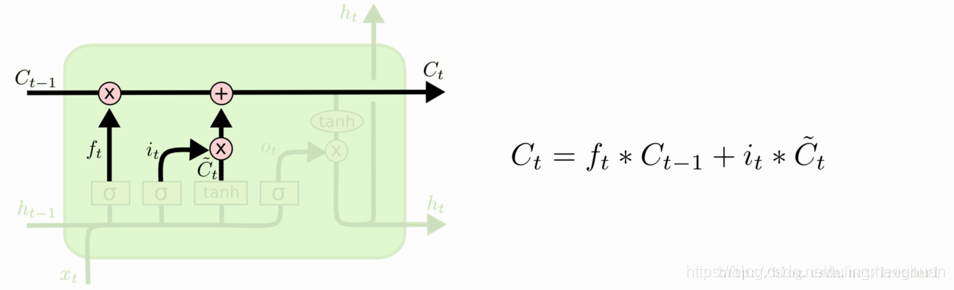
第三步就是更新旧细胞的状态,将Ct-1更新为Ct。我们把旧状态与 ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上 it * ~Ct。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的信息并添加新的信息的地方。
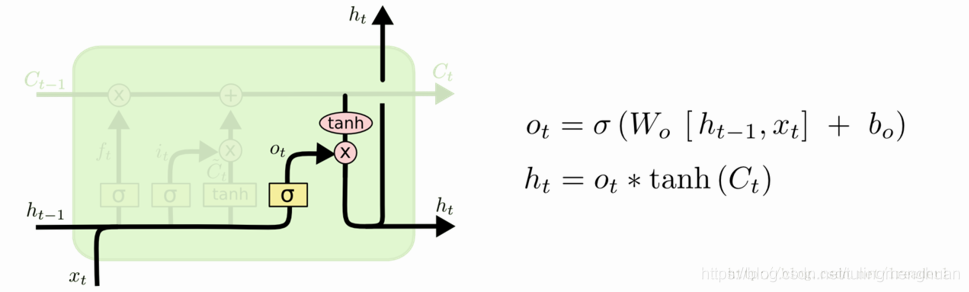
最后一步就是确定输出了,这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。在语言模型的例子中,因为语境中有一个代词,可能需要输出与之相关的信息。例如,输出判断是一个动词,那么我们需要根据代词是单数还是负数,进行动词的词形变化。
3.2GRU( Gated Recurrent Unit,LSTM变体)
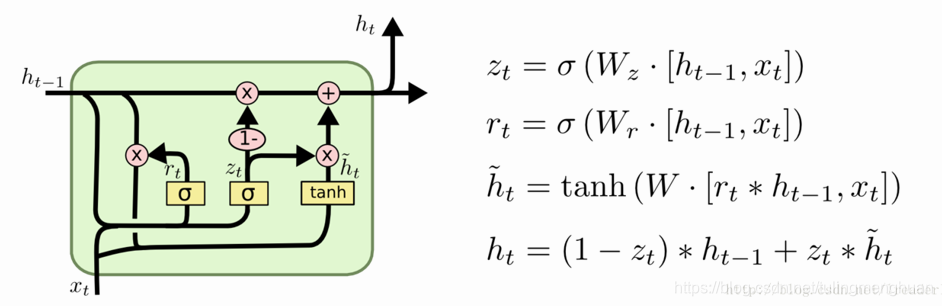
3.3优缺点
LSTM 的优点
该算法桥接长时间滞后的能力来自其架构的记忆单元中的常量误差反向传播。
LSTM 可以近似有噪声的问题域、分布式表征和连续值。
LSTM 可以很好地泛化其所考虑的问题域。这是很重要的,因为有的任务无法用已有的循环网络解决。在问题域上对网络参数进行微调看起来是不必要的。
在每个权重和时间步的更新复杂度方面,LSTM 基本上就等于 BPTT。LSTM 很强大,在机器翻译等领域实现了当前最佳的结果。
LSTM 的局限性
LSTM 有效的截断版本无法轻松解决类似于「强延迟的异或(strongly delayed XOR)」这样的问题。
每个记忆单元模块都需要一个输入门和一个输出门。并不一定需要其它循环方法。
在记忆单元内穿过「常量误差传送带(Constant Error Carrousels)」的常量误差流可以得到与传统的前馈架构(会一次性获得整个输入串)一样的效果。
和其它前馈方法一样,LSTM 也有「regency」概念上的缺陷。如果需要精密的计数时间步骤,那么可能就需要额外的计数机制。
GRU的优点
GRU只有两个门,因此结构简单,计算速度快,可以进行大规模的运算。
4.Text-RNN的原理
4.1模型
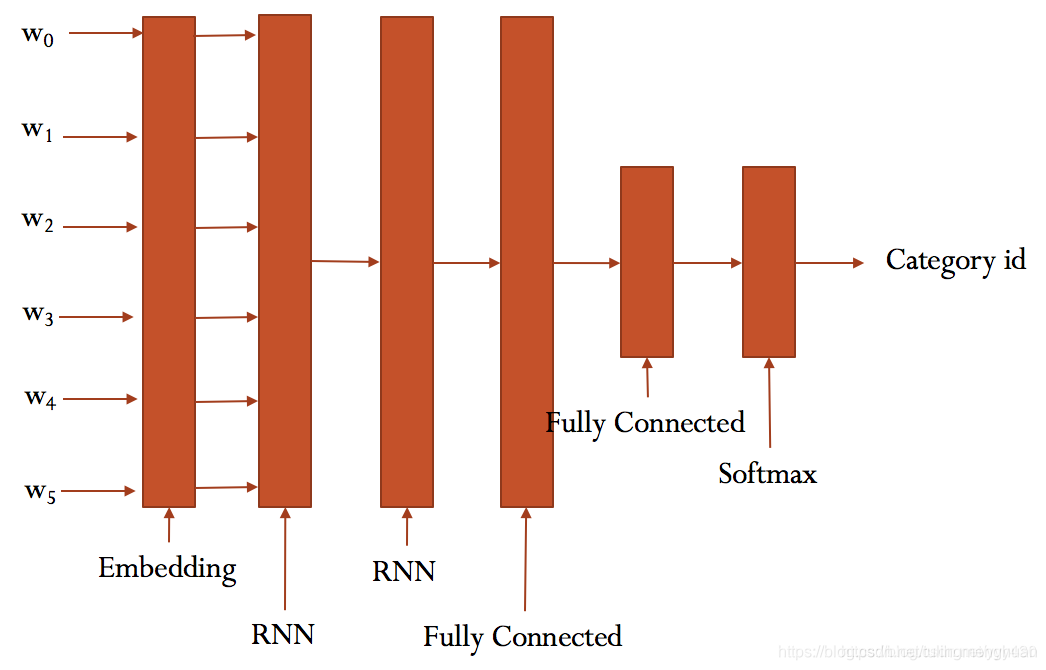
4.2 实战
https://github.com/Tulingmenghuan/nlp_learning/tree/master-2/task11














 1339
1339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









