






MNIST数字识别
MNIST数据集是一个非常有用的手写体数字识别集,这个数据集经常被用来作为深度学习的入门样例,如同我们学习一门新的语言的"Hello World!"。本博客主要参照TensorFlow实战Google深度学习框架(第二版)。
MNIST数据集解析
人工智能离不开数据,在本次的学习中,数据的重要性可想而知,首先我们要了解数据集的基本情况,首先放上数据集的下载网址MNIST数据集下载。本次学习是在tensorflow上实现的,下面对该数据集做一个比较简单的介绍。该数据集下载下来共有4个数据集:

该数据集包含了60000张图片作为训练样本(其中包含5000张图片作为验证数据集,55000张图片作为测试数据集),10000张图片作为测试数据集。MNIST数据集中的每张图片都是代表0-9中的一个数字,每张图片的大小都是28x28,.并且每一张图片都有对应的标签,如下图展示了一张数字图片及其它对应的像素矩阵。(注:在训练模型时,常常将数据集划分为训练集、验证集、测试集)
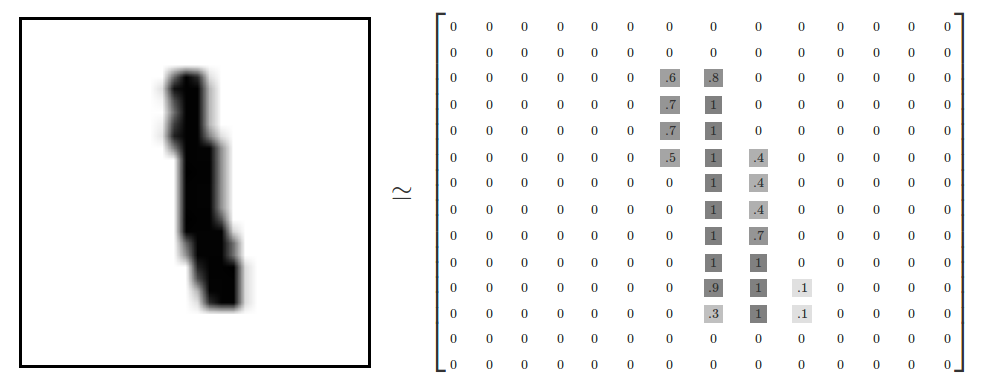
下面以程序的方式打印出来验证MNIST数据集的情况,Tensorflow对MNIST数据集已经做好了封装,因此使用tensorflow来实现非常方便。
#读取数据集,第一次TensorFlow会自动下载数据集到下面的路径中
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
#打印训练数据集的大小
print( "Training data size: ", mnist.train.num_examples) #Training data size: 55000
#打印验证数据集的大小
print( "Validating data size: ", mnist.validation.num_examples) #Validating data size: 5000
#打印测试数据集的大小
print("Testing data size: ", mnist.test.num_examples) #Testing data size: 10000
#打印出训练数据集的标签,注意这里是经过one_hot编码了的
print("Example training data label: ", mnist.train.labels[0]) #Example training data label: [ 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
特别的,我们在训练模型时经常用到随机梯度下降,使用mnist.train.next_batch函数非常方便。
xs, ys = mnist.train.next_batch(batch_size) # 从train的集合中选取batch_size个训练数据
print("xs shape",xs.shape) #输出(batch_size,784)
print("ys shape",ys.shape) #输出(batch_size,10)
神经网络
本次课程运用一个非常简单的神经网络(全连接神经网络),输入层由784个神经元,隐藏层有500个神经元,输出层有10个神经元。
实现代码
代码下载地址:https://github.com/twpsuperman/Study/tree/master/MNIST
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import time
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf', size=14)
#设置神经网络结构参数
INPUT_NODE = 784
HIDE_NODE = 500
OUTPUT_NODE = 10
#设置神经网络学习相关参数
TRAINING_SETPS = 10000
LEARNING_RATE_BASE = 0.8 #设置基础的学习率
LEARNING_RATE_DECAY = 0.99 #学习率的衰减率
BATCH_SIZE = 100 #设置batch处理的数量
REGULARRIZATION_RATE = 0.0001 #设置正则化项前的系数
MOVING_AVERAGE_DECAY = 0.99 #设置滑动平均衰减率
#实现神经网络的前向传播函数
def inference(input_tensor,avg_class,weights1,biases1,weights2,biases2):
if avg_class == None:#当没有提供滑动平均类时,直接使用当前参数的取值
layer1 = tf.nn.relu(tf.matmul(input_tensor,weights1)+biases1)
return tf.matmul(layer1,weights2)+biases2
else:
layer1 = tf.nn.relu(tf.matmul(input_tensor,avg_class.average(weights1))+avg_class.average(biases1))
return tf.matmul(layer1,avg_class.average(weights2))+avg_class.average(biases2)
#定义一个训练过程
def train(mnist):
plot_saves = []
x = tf.placeholder(tf.float32,shape=[None,INPUT_NODE],name='x-input')
y_ = tf.placeholder(tf.float32,shape=[None,OUTPUT_NODE],name='y-input')
#生成隐藏层参数
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE,HIDE_NODE],stddev=0.1))
biases1 = tf.Variable(tf.constant([0.1],shape=[HIDE_NODE]))
#生成输出层参数
weights2 = tf.Variable(tf.truncated_normal([HIDE_NODE,OUTPUT_NODE],stddev=0.1))
biases2 = tf.Variable(tf.constant([0.1],shape=[OUTPUT_NODE]))
#计算不含滑动平均的前向传播
y = inference(x,None,weights1,biases1,weights2,biases2)
# 定义训练轮数及相关的滑动平均类
global_step = tf.Variable(0,trainable=False)
#定义一个滑动平均类
variable_averages = tf.train.ExponentialMovingAverage(LEARNING_RATE_DECAY,global_step)
#定义一个更新变量滑动平均的操作,每次执行这个操作时,都会更新需要更新的变量
variables_averages_op = variable_averages.apply(tf.trainable_variables())
average_y = inference(x,variable_averages,weights1,biases1,weights2,biases2)
#计算损失函数的交叉熵和平均值
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = y,labels = tf.argmax(y_,1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
#计算带L2正则化的损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARRIZATION_RATE)
regularaztion = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularaztion
# 设置指数衰减的学习率,staircase=True;
# 那就表明每decay_steps次计算学习速率变化,更新原始学习速率,如果是False,那就是每一步都更新学习速率
#global_step为记录当前轮数 LEARNING_RATE_DECAY为事先设定的学习率
#LEARNING_RATE_STEP: 是学习率更新速度, 及每LEARNING_RATE_STEP轮训练后要乘以学习率衰减系数;
#LEARNING_RATE_DECAY为学习率衰减系数
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples / BATCH_SIZE,LEARNING_RATE_DECAY,staircase=True)
# 优化损失函数
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
# 反向传播更新参数和更新参数每一个参数的滑动平均值
with tf.control_dependencies([train_step,variables_averages_op]):
train_op = tf.no_op(name='train')
#计算正确率
correct_prediction = tf.equal(tf.arg_max(average_y,1),tf.arg_max(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#初始化并开始进行会话
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
#准备验证数据集
validate_feed = {x:mnist.validation.images,y_:mnist.validation.labels}
#准备测试数据集
test_feed = {x:mnist.test.images,y_:mnist.test.labels}
#循环训练神经网络
for i in range(TRAINING_SETPS+1):
if i % 1000 == 0:
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print('After %d training step(s), validation accuracy using average model is %g'%(i,validate_acc))
dynamic_learningrate = sess.run(learning_rate, feed_dict={global_step: i})#获取动态动态学习率
xs,ys = mnist.train.next_batch(BATCH_SIZE)#产生这一轮使用的一个batch训练的数据,并运行训练过程
sess.run(train_op,feed_dict={x:xs,y_:ys})
val_acc_bitch = sess.run(accuracy, feed_dict=validate_feed)#验证集准确率
test_acc_bitch = sess.run(accuracy, feed_dict=test_feed)#测试集的准确率
plot_save = (i,test_acc_bitch,val_acc_bitch,dynamic_learningrate)
plot_saves.append(plot_save)
test_acc = sess.run(accuracy,feed_dict=test_feed)
print(("After %d training step(s), test accuracy using average model is %g" % (TRAINING_SETPS, test_acc)))
return plot_saves
def plot_accuracy(plot_saves):
m = len(plot_saves)
x_epoach = []#保存训练次数的列表
y_test_acc = []#保存测试集准确率的列表
y_val_acc = []#保持验证集准确率列表
dynamic_learning_rate = []#保存动态学习率的列表
for i in range(m):
x_epoach.append(plot_saves[i][0])
y_test_acc.append(plot_saves[i][1])
y_val_acc.append(plot_saves[i][2])
dynamic_learning_rate.append(plot_saves[i][3])
plt.figure(1)
plt.plot(x_epoach,y_test_acc,'m',label = 'test acc')
plt.plot(x_epoach,y_val_acc,'r',label='val acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('测试集的正确率', fontproperties=font) # 绘制图形的标题
plt.legend() # 显示图形的图例
plt.figure(2)
plt.plot(x_epoach, dynamic_learning_rate, 'r', label='learning_rate')
plt.xlabel('Epochs')
plt.ylabel('Learning_rate')
plt.title('动态学习率曲线', fontproperties=font) # 绘制图形的标题
plt.legend()#显示图形的图例
plt.show()
def main(argv=None):
mnist = input_data.read_data_sets(r"MNIST_data",one_hot=True)
plot_saves = train(mnist)
#绘制曲线
plot_accuracy(plot_saves)
if __name__ == '__main__':
start = time.time()
main()
end = time.time()
print("总花费时间为:"+str((end-start)/60)+'min')
代码部分添加了部分注释,故不再分模块解释。
结果分析
本程序是在tensorflow-gpu上运行的,运行的时间依个人电脑的配置情况而定。本次一共训练了10000轮,每1000轮打印在验证集上的准确率,在10000轮时打印在测试集上的准确率。并且绘制了在验证数据集和测试数据集上的准确率曲线,同时绘制了学习率变化的曲线。
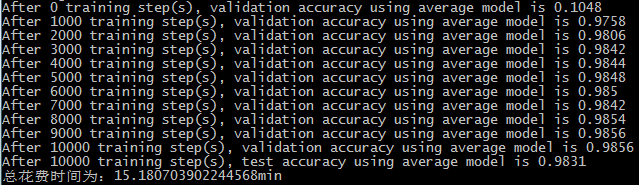
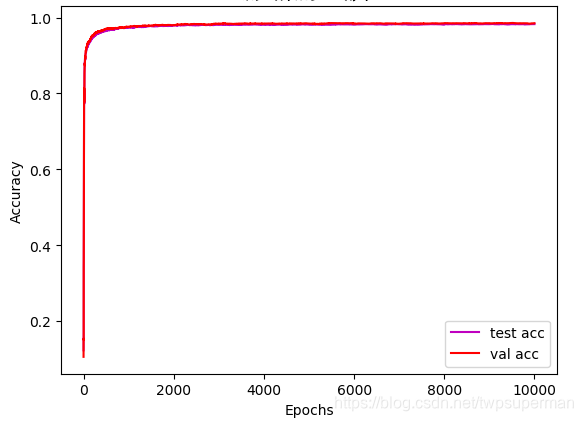
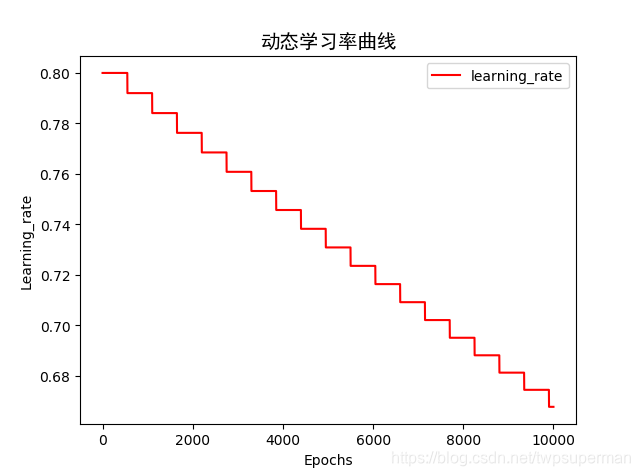
损失函数计算
这里可能会遇到两个函数tf.nn.sparse_softmax_cross_entropy_with_logits和tf.nn.softmax_cross_entropy_with_logits,一定要注意这两个函数的区别,他们的区别见这里:两个函数的区别。
以上是我这次所学,难免存在错误与不足,希望大家批评指正,共同进步!














 4630
4630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









