







一、概述
- Kafka是一个具有高吞吐量,高拓展性,高性能和高可靠的基于发布订阅模式的消息队列,是由领英基于Java和Scala语言开发。通常适合于大数据量的消息传递场景,如日志分类,流式数据处理等。
- Kafka的体系结构的核心组件包括:消息生产者,消息消费者,基于消息主题进行消息分类,使用Broker集群进行数据存储。同时使用Zookeeper进行集群管理,包括
- 主题 topic 的分区组成信息
- 分区和分区副本所在的 broker 信息
- 分区的消费信息:每个分区由哪些消费者消费,以及各自消费到哪里的 offset 信息。
- Kafka相对于其他MQ,最大的特点是高拓展性,包括消息通过主题拓展,主题通过分区拓展,消息消费通过消费者组拓展,数据存储通过brokers机器集群拓展。
二、主题与分区
1. 主题Topic
-
Kafka作为一个消息队列,故需要对消息进行分类,Kafka是通过Topic主题来对消息进行分类的,即Kafka可以根据需要定义多个主题,每个消息属于一个主题。如下为kafka提供的用于创建,删除和查看kafka当前存在的主题的命令行工具:
-
创建主题:指定分区数partitions,分区副本数replication-factor,zookeeper。
./kafka-topics.sh --create --topic mytopic --partitions 2 --zookeeper localhost:2181 --replication-factor 2 -
查看某个主题的信息:PartitionCount分区数量,ReplicationFactor分区副本数量;Leader分区leader(负责该分区的读写),Isr同步副本。由于在本机存在3个brokers,对应的server.properties的broker.id分别为:0, 1, 2,所以通过–describe选项查看的mytopic的详细信息可知:
mytopic的分区0是分区leader为broker2,同步副本为broker1和broker2;分区1的分区leader为broker0,同步副本为broker0和broker2。xyzdeMacBook-Pro:bin xyz ./kafka-topics.sh --describe --topic mytopic --zookeeper localhost:2181 Topic:mytopic PartitionCount:2 ReplicationFactor:2 Configs: Topic: mytopic Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: mytopic Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2 -
查看所有主题信息:
./kafka-topics.sh --list --zookeeper localhost:2181 -
删除主题:
xyzdeMacBook-Pro:bin xieyizun$ ./kafka-topics.sh --delete --topic mytopic --zookeeper localhost:2181 Topic mytopic is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.
-
-
主题就相当于一个个消息管道,同一个主题的消息都在同一个管道流动,不同管道的消息互不影响。
-
作为一个高吞吐量和大数据量的消息队列,如果一个主题的消息非常多,由于所有消息都需要排队处理,故很容易导致性能问题。所以在主题的基础上可以对主题进行进一步地分类,这个就是分区。
2. 分区Partition
- 分区是对主题Topic的拓展,每个主题可以包含多个分区,每个分区包含整个主题的全部信息的其中一部分,全部信息由所有分区的消息组成。所以主题就相当于一根网线,而分区是网线里面五颜六色的数据传输线。
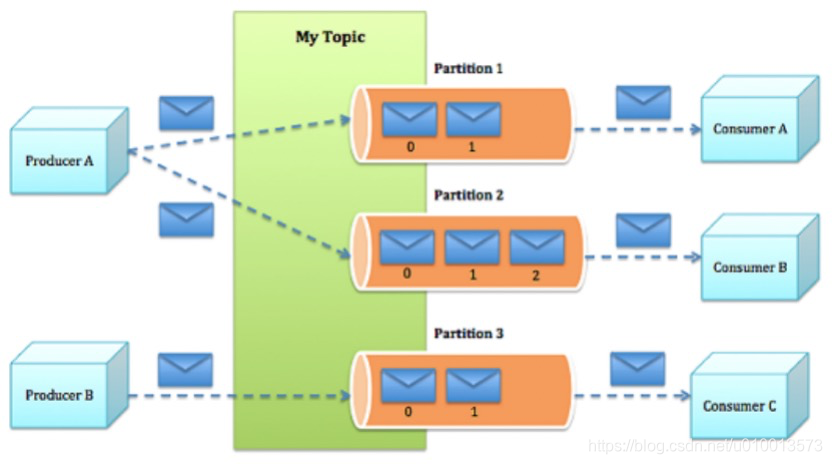
- 有序性:由于主题的消息分散到了各个分区中,故如果存在多个分区,则该主题的消息整体上是无序的,而每个分区相当于以队列,内部的消息是局部有序的。所以如果需要保证主题整体的消息有序,则只能使用一个分区。如图所示:mytopic包含3个partition分区,每个分区内部是一个消息队列。
3. 分区副本Replication:高可靠性
- 为了实现可靠性,即避免分区的消息丢失,每个分区可以包含多个分区副本,通过数据冗余存储来实现数据的高可靠性。
- 每个分区的多个副本中,只有一个作为分区Leader,由该分区Leader来负责该分区的所有消息读写操作,其他分区副本作为Followers从该分区Leader同步数据。
a. 分区副本的存储
- 为了避免某个broker机器节点故障导致数据丢失,每个分区的多个副本需要位于不同的broker机器节点存放,这样当某个broker机器节点出现故障不可用时,可以从将其他broker机器节点选举该分区的另一个副本作为分区Leader继续进行该分区的读写。
- 所以brokers机器集群节点的数量需要大于或者等于最大的分区副本数量,否则会导致主题创建失败。
b. 同步副本Isr
-
分区Leader的选举是由zookeeper负责的,因为zookeeper存储了每个分区的分区副本和分区Leader信息。如果当前分区Leader所在的broker机器节点挂了,则zookeeper会从其他分区副本选举产生一个新的分区Leader。
-
zookeeper不是随便选举一个分区副本作为新的分区Leader的,而是从该分区的同步副本Isr集合中选举。所谓同步副本就是该副本的数据是与分区Leader保持同步。“几乎”一致的,故在分区leader挂了时,可以减少数据的丢失。
-
一个分区副本成为同步副本的条件如下:如果当前不存在同步副本,分区leader可以抛异常拒绝数据写入。
replica.lag.time.max.ms,默认10000,副本未同步数据的时间 replica.lag.max.messages,4000,副本滞后的最大消息条数
三、生产者
1. 消息路由
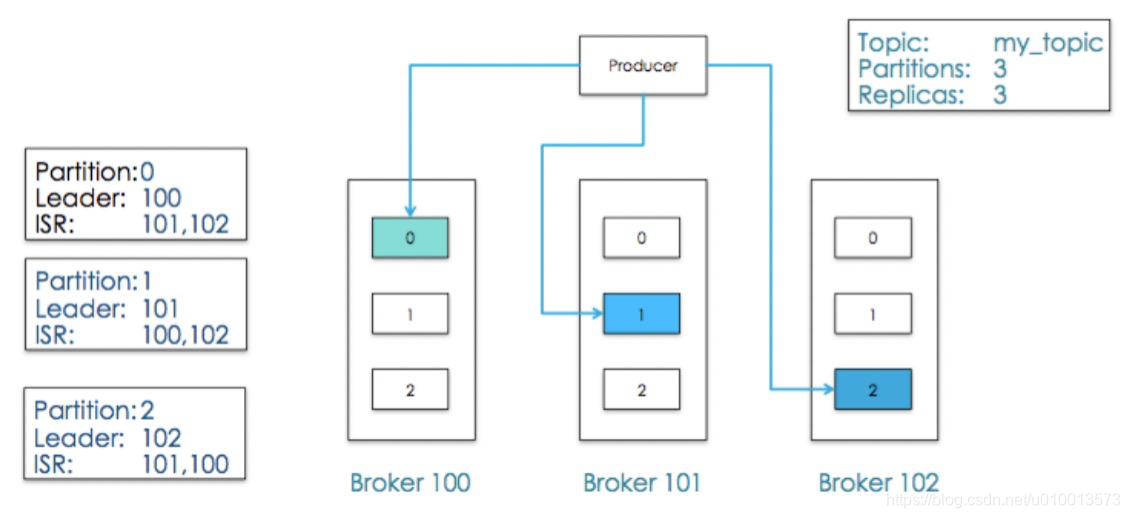
- 前面介绍了kafka通过主题和分区来对消息进行分类存储,而消息生产者负责生产消息,指定每个消息属于哪个主题的哪个分区。即kafka的消息路由是由生产者负责的,生产者在生成消息时需要指定消息的主题和分区。如图:producer将生成mytopic主题的三个消息分别传给分区0,1,2的分区leader对应的broker100,broker101,broker102。
- 分区的指定的可选:
- 如果生产者不显示指定消息的分区,则kafka的Producer API默认是基于round-robin轮询来发送消息给该主题的多个分区的。
- 生产者可以指定一个key,然后kafka会基于该key的hash值来将相同key的消息路由到同一个分区,从而实现相同key的消息的有序,如在股票行情中,使用股票代号作为
key,从而实现同一股票的分时价格数据有序。 - 自定义partition:可以实现Partitioner接口并重写partition方法来自定义分区路由。
2. 消息ack实现可靠性
- 生产者负责生成并发送消息给各个主体的各个分区,由于网络的不稳定性和分区leader所在的broker机器可能出现故障,故需要一种机制来保证消息的可靠性传输,这种机制就是ack机制,即生产者发送一个消息之后,只有在收到kafka服务器返回的ack确认之后才认为该消息成功发送,否则进行消息重发。其中kafka的消息重发是幂等的,幂等性的实现为 producer 初始化的时候生成一个唯一的 PID, 生成的消息也生成一个seq,实现 producer 端的消息不重复。
- ack实现消息可靠性和整体的吞吐量和性能需要取一个折中,故kafka的ack机制相关配置参数如下:主要包括acks,retries,producer.type。
-
acks参数:消息确认
acks=0:发送后则生产者立即返回,不管消息上是否写入成功,这种吞吐量和性能最好,但是可靠性最差; acks=1:默认,发送后,等待分区leader写入成功返回ack则生产者返回; acks=-1: 发送后,不仅需要分区leader的ack,还需要等待所有副本写入后的ack,可靠性最高,吞吐量和性能最差。 -
retries:可重试错误的重试次数,如返回LEADER_NOT_AVALIAVLE错误时,则需要重试;
-
producer.type:发送类型,sync同步发送(默认)和async异步发送(batch发送)
-
3. 消费生成与消费测试
-
kafka提供了命令行工具来生产消息,方便进行主题的测试:执行如下命令后,则可以在命令行输入各种消息,然后可以在另一个终端消费查看消息是否生成成功。
./kafka-console-producer.sh --topic mytopic --broker-list localhost:19092 -
消息消费命令:
./kafka-console-consumer.sh --topic quote-depth --zookeeper localhost:2181
四、Broker集群
- broker机器集群就是kafka的服务端实现,主要负责存储主题各分区的消息,负责接收生产者的数据写入请求,处理消费者的数据读取请求。
1. 分区数据存储
a. 分区与分区副本的存储方案
- 每个broker可以存放多个主题的多个分区的消息,而这些统计信息,即某个分区位于哪个broker是由zookeeper维护的。
- 同一个分区的多个分区副本需要位于不同的broker中,从而避免某个broker机器故障导致该分区的数据丢失。
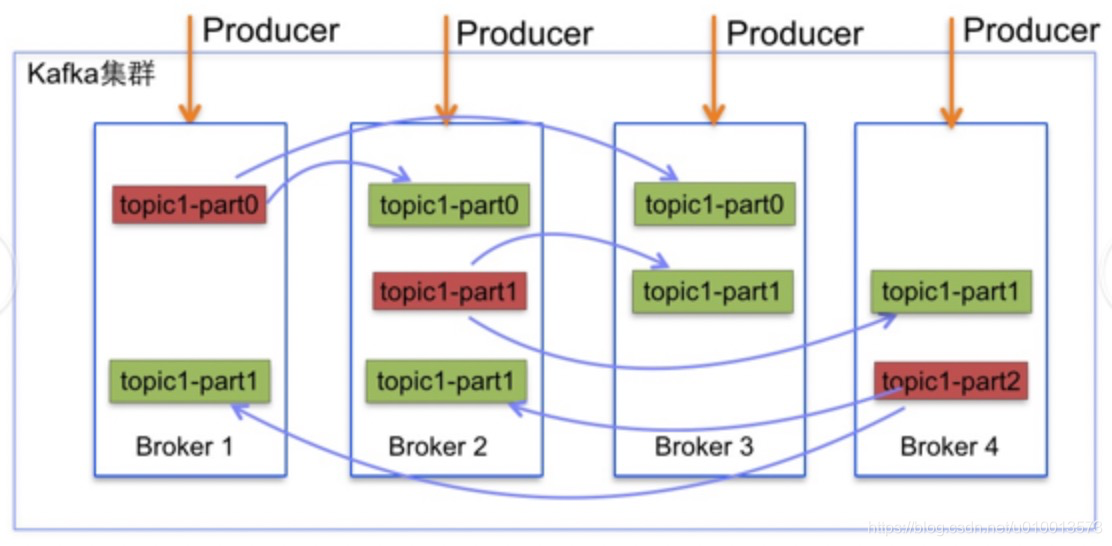
- 具体存储关系如图:红色的为分区leader,绿色的为分区副本,同一个分区的不同分区副本位于不同的broker中。
b. 消息数据的存储方式
- Kafka 是基于磁盘文件来存储消息数据的,具体为每个 Topic的每个分区 对应一个文件目录,目录名一般为 主题名-分区号,如mytopic-0,每个分区对应该目录下的一个文件或多个文件(当单个文件超出指定大小时,则创建一个新的文件),其中文件是二进制文件并且通过在文件尾追加消息的方式来存储消息。
- 关于 Kafka 磁盘存储消息的具体设计,可以参考我的另外一篇文章:Kafka的高性能磁盘读写实现原理
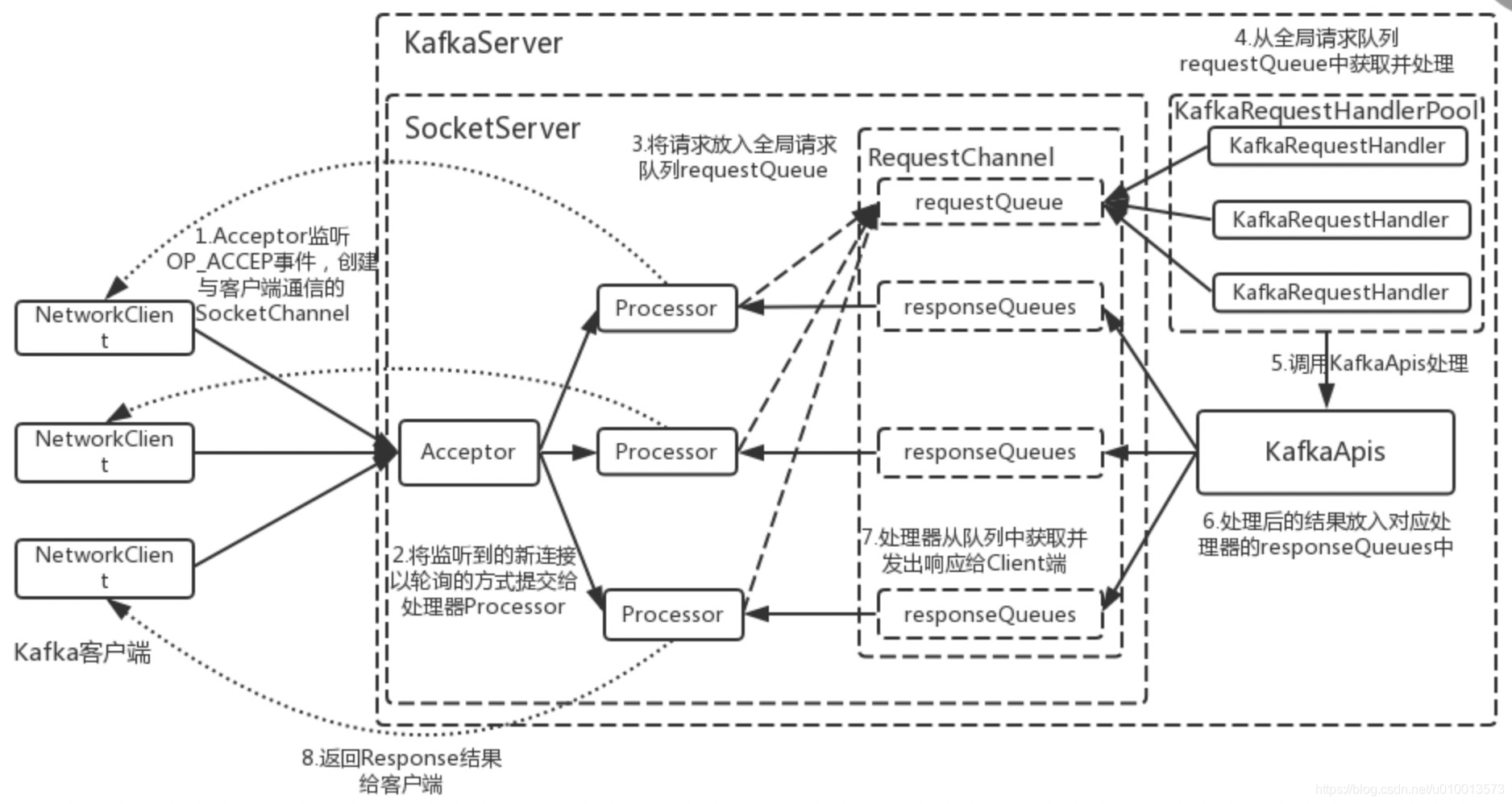
2. 请求处理模型
- kafka基于C/S架构,broker作为kafka的服务端实现,生产者和消费者作为kafka的客户端实现,故broker需要接收生产者和消费者的连接请求并处理。
- 客户端与服务端之间是通过TCP长连接来通信的,减少连接创建的开销。
- 如下为该请求处理模型示意图:
五、消费者
- 可拓展性:消费者负责消费某个主题的某个分区的数据,为了实现可拓展性,实现同一个分区的数据被多种不同的业务重复利用,kafka定义了消费者组的概念,即每个消费者属于一个消费者组。
- 高可用:由于一个消费者组内可以包含多个消费者,所以如果消费某个分区的消费者挂了,则可以由该消费者内的另外一个消费者来继续消费该分区,实现了分区消费的高可用。
1. 消息重复利用
a. 同一个消费者组:单播
- 一个主题的其中一个分区只能被同一个消费者组中的一个消费者消费,消费者内的一个消费者可以消费多个主题的多个分区,从而避免消费者组内对同一个分区的消息的重复消费。
- 如股票的股价提醒当中,对于同一只股票只能由同一个消费者组组的一个消费者线程处理,否则会导致重复提醒。
b. 不同消费者组:广播
- 不同的消费者组代表不同的业务,每个消费者组都可以有一个消费者对同一个主题的同一个分区消费一次,所以实现了消息的重复消费利用,实现了消费的高度可拓展性。
- 具体消费者组与消费者的消费情况如图所示:broker1的分区0分别被消费者组A的消费者C1和消费者组B的消费者C3消费。
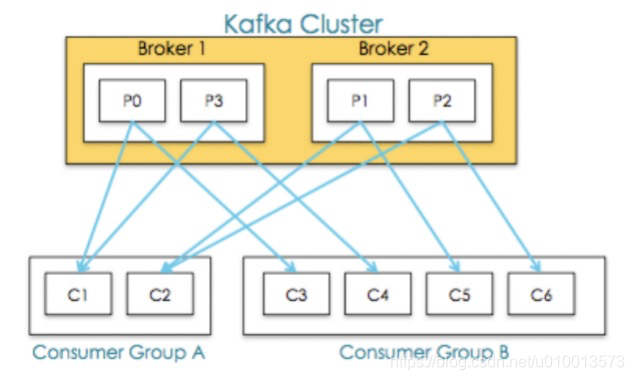
2. 消息消费跟踪
-
每个消费者在消费某个主题的一个分区的消息时,基于offset机制来保证对该分区所有消息的完整消费和通过修改offset来实现对该分区消息的回溯。
-
消费者每消费该分区内的一个消息,则递增消费offset并上传给zookeeper来维护,使用zookeeper维护的好处时,假如该消费者挂了,则zookeeper可以从该消费者组选择另外一个消费者从offset往后继续消费,避免数据的重复消费或者漏掉消费。其中上传提交offset给zookeeper可以是自动提交或者由应用程序控制手动提交。具体通过参数来定义:
enable.auto.commit:默认为true,即自动提交,是Kafka Consumer会在后台周期性的去commit。 auto.commit.interval.ms:自动提交间隔。范围:[0,Integer.MAX],默认值是 5000 (5 s)
a. 自动提交offset:至多一次
- 消费者消费消息默认是自动提交offset给zookeeper的。使用自动提交的好处是编程简单,应用代码不需要处理offset的提交。缺点是可能导致消息的丢失,即当消费者从broker读取到了消息,然后自动提交offset给zookeeper,如果消费者在处理该消息之前挂了,则会导致消息没有处理而丢失了,因为此时已经上传了offset给zookeeper,则下一个消费者不会消费该消息了。
- 故自动提交模型是at most once,即最多消费一次,可能存在消息丢失。
b. 手动提交offset:至少一次
- 如果关掉自动提交,即设置enable.auto.commit为false,则需要应用程序消费消息后手动提交。这种方式的好处是消费者线程可以在成功处理该消息后才提交到zookeeper,如果处理中途挂了,则不会上传给zookeeper,下个消费者线程可以继续处理该消息。所以缺点是可能导致消费的重复消费,如消费者线程在成功处理该消息后,如写入数据库成功了,但是在提交之前消费者线程挂了没有提交该offset给zookeeper,则会造成重复消费。
- 故手动提交模型是at least once,即至少消费一次,可能存在重复消费。
c. 手动提交 offset 的原子性:刚好一次
- 刚好一次也是基于手动提交 offset 来实现的,具体需要保证消息的处理和消息消费的offset提交反馈保持在一个事务内,实现原子性。
- 实现层面,可以结合数据库来存放该条消息消费记录,同时消息的消费记录的落库和往 zookeeper 提交 offset 需要保持在一个事务内。具体可以参考这个博主的实现:https://blog.csdn.net/laojiaqi/article/details/79034798














 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









