







一、前言
这是一篇指导驱动工程师如何使用DMA API的文档,为了方便理解,文档中给出了伪代码的例程。另外一篇文档dma-api.txt给出了相关API的简明描述,有兴趣也可以看看那一篇,这两份文档在DMA API的描述方面是一致的。
二、从CPU角度看到的地址和从DMA控制器看到的地址有什么不同?
在DMA API中涉及好几个地址的概念(物理地址、虚拟地址和总线地址),正确的理解这些地址是非常重要的。
内核通常使用的地址是虚拟地址。我们调用kmalloc()、vmalloc()或者类似的接口返回的地址都是虚拟地址,保存在"void *"的变量中。
虚拟内存系统(TLB、页表等)将虚拟地址(程序角度)翻译成物理地址(CPU角度),物理地址保存在“phys_addr_t”或“resource_size_t”的变量中。对于一个硬件设备上的寄存器等设备资源,内核是按照物理地址来管理的。通过/proc/iomem,你可以看到这些和设备IO 相关的物理地址。当然,驱动并不能直接使用这些物理地址,必须首先通过ioremap()接口将这些物理地址映射到内核虚拟地址空间上去。
I/O设备使用第三种地址:“总线地址”。如果设备在MMIO地址空间中有若干的寄存器,或者该设备足够的智能,它可以通过DMA执行读写系统内存的操作,这些情况下,设备使用的地址就是总线地址。在某些系统中,总线地址与CPU物理地址相同,但一般来说它们不是。iommus和host bridge可以在物理地址和总线地址之间进行映射。
从设备的角度来看,DMA控制器使用总线地址空间,不过可能仅限于总线空间的一个子集。例如:即便是一个系统支持64位地址内存和64 位地址的PCI bar,但是DMA可以不使用全部的64 bit地址,通过IOMMU的映射,PCI设备上的DMA可以只使用32位DMA地址。
我们用下面这样的系统结构来说明各种地址的概念:
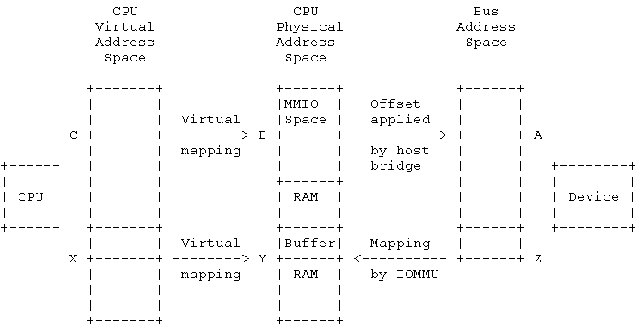
在PCI设备枚举(初始化)过程中,内核了解了所有的IO device及其对应的MMIO地址空间(MMIO是物理地址空间的子集),并且也了解了是PCI主桥设备将这些PCI device和系统连接在一起。PCI设备会有BAR(base address register),表示自己在PCI总线上的地址,CPU并不能通过总线地址A(位于BAR范围内)直接访问总线上的PCI设备,PCI host bridge会在MMIO(即物理地址)和总线地址之间进行mapping。因此,对于CPU,它实际上是可以通过B地址(位于MMIO地址空间)访问PCI设备(反正PCI host bridge会进行翻译)。地址B的信息保存在struct resource变量中,并可以通过/proc/iomem开放给用户空间。对于驱动程序,它往往是通过ioremap()把物理地址B映射成虚拟地址C,这时候,驱动程序就可以通过ioread32(C)来访问PCI总线上的地址A了。
如果PCI设备支持DMA,那么在驱动中我们可以通过kmalloc或者其他类似接口分配一个DMA buffer,并且返回了虚拟地址X,MMU将X地址映射成了物理地址Y,从而定位了DMA buffer在系统内存中的位置。因此,驱动可以通过访问地址X来操作DMA buffer,但是PCI 设备并不能通过X地址来访问DMA buffer,因为MMU对设备不可见,而且系统内存所在的系统总线和PCI总线属于不同的地址空间。
在一些简单的系统中,设备可以通过DMA直接访问物理地址Y,但是在大多数的系统中,有一个IOMMU的硬件block用来将DMA可访问的总线地址翻译成物理地址,也就是把上图中的地址Z翻译成Y。理解了这些底层硬件,你也就知道类似dma_map_single这样的DMA API是在做什么了。驱动在调用dma_map_single这样的接口函数的时候会传递一个虚拟地址X,在这个函数中会设定IOMMU的页表,将地址X映射到Z,并且将返回z这个总线地址。驱动可以把Z这个总线地址设定到设备上的DMA相关的寄存器中。这样,当设备发起对地址Z开始的DMA操作的时候,IOMMU可以进行地址映射,并将DMA操作定位到Y地址开始的DMA buffer。
根据上面的描述我们可以得出这样的结论:Linux可以使用动态DMA 映射(dynamic DMA mapping)的方法,当然,这需要一些来自驱动的协助。所谓动态DMA 映射是指只有在使用的时候,才建立DMA buffer虚拟地址到总线地址的映射,一旦DMA传输完毕,就将之前建立的映射关系销毁。
虽然上面的例子使用IOMMU为例描述,不过本文随后描述的API也可以在没有IOMMU硬件的平台上运行。
顺便说明一点:DMA API适用于各种CPU arch,各种总线类型,DMA mapping framework已经屏蔽了底层硬件的细节。对于驱动工程师而言,你应该使用通用的DMA API(例如dma_map_*() 接口函数),而不是和特定总线相关的API(例如pci_map_*() 接口函数)。
驱动想要使用DMA mapping framework的API,需要首先包含相关头文件:
#include <linux/dma-mapping.h>
这个头文件中定义了dma_addr_t这种数据类型,而这种类型的变量可以保存任何有效的DMA地址,不管是什么总线,什么样的CPU arch。驱动调用了DMA API之后,返回的DMA地址(总线地址)就是这种类型的。
三、什么样的系统内存可以被DMA控制器访问到?
既然驱动想要使用DMA mapping framework提供的接口,我们首先需要知道的就是是否所有的系统内存都是可以调用DMA API进行mapping?还是只有一部分?那么这些可以DMA控制器访问系统内存有什么特点?关于这一点,一直以来有一些不成文的规则,在本文中我们看看是否能够将其全部记录下来。
如果驱动是通过伙伴系统的接口(例如__get_free_page*())或者类似kmalloc() or kmem_cache_alloc()这样的通用内存分配的接口来分配DMA buffer,那么这些接口函数返回的虚拟地址可以直接用于DMA mapping接口API,并通过DMA操作在外设和dma buffer中交换数据。
使用vmalloc() 分配的DMA buffer可以直接使用吗?最好不要这样,虽然强行使用也没有问题,但是终究是比较麻烦。首先,vmalloc分配的page frame是不连续的,如果底层硬件需要物理内存连续,那么vmalloc分配的内存不能满足硬件要求。即便是底层DMA硬件支持scatter-gather,vmalloc分配出来的内存仍然存在其他问题。我们知道vmalloc分配的虚拟地址和对应的物理地址没有线性关系(kmalloc或者__get_free_page*这样的接口,其返回的虚拟地址和物理地址有一个固定偏移的关系),而在做DMA mapping的时候,需要知道物理地址,有线性关系的虚拟地址很容易可以获取其物理地址,但是对于vmalloc分配的虚拟地址,我们需要遍历页表才可以找到其物理地址。
在驱动中定义的全局变量可以用于DMA吗?如果编译到内核,那么全局变量位于内核的数据段或者bss段。在内核初始化的时候,会建立kernel image mapping,因此全局变量所占据的内存都是连续的,并且VA和PA是有固定偏移的线性关系,因此可以用于DMA操作。不过,在定义这些全局变量的DMA buffer的时候,我们要小心的进行cacheline的对齐,并且要处理CPU和DMA controller之间的操作同步,以避免cache coherence问题。
如果驱动编译成模块会怎么样呢?这时候,驱动中的全局定义的DMA buffer不在内核的线性映射区域,其虚拟地址是在模块加载的时候,通过vmalloc分配,因此这时候如果DMA buffer如果大于一个page frame,那么实际上我们也是无法保证其底层物理地址的连续性,也无法保证VA和PA的线性关系,这一点和编译到内核是不同的。
通过kmap接口返回的内存可以做DMA buffer吗?也不行,其原理类似vmalloc,这里就不赘述了。
块设备使用的I/O buffer和网络设备收发数据的buffer是如何确保其内存是可以进行DMA操作的呢?块设备I/O子系统和
网络子系统在分配buffer的时候会确保这一点的。
四、DMA寻址限制
你的设备有DMA寻址限制吗?不同的硬件平台有不同的配置方式,有的平台没有限制,外设可以访问系统内存的每一个Byte,有些则不可以。例如:系统总线有32个bit,而你的设备通过DMA只能驱动低24位地址,在这种情况下,外设在发起DMA操作的时候,只能访问16M以下的系统内存。如果设备有DMA寻址的限制,那么驱动需要将这个限制通知到内核。如果驱动不通知内核,那么内核缺省情况下认为外设的DMA可以访问所有的系统总线的32 bit地址线。对于64 bit平台,情况类似,不再赘述。
是否有DMA寻址限制是和硬件设计相关,有时候标准总线协议也会规定这一点。例如:PCI-X规范规定,所有的PCI-X设备必须要支持64 bit的寻址。
如果有寻址限制,那么在该外设驱动的probe函数中,你需要询问内核,看看是否有DMA controller可以支持这个外设的寻址限制。虽然有缺省的寻址限制的设定,不过最好还是在probe函数中进行相关处理,至少这说明你已经为你的外设考虑过寻址限制这事了。
一旦确定了设备DMA寻址限制之后,我们可以通过下面的接口进行设定:
int dma_set_mask_and_coherent(struct device *dev, u64 mask);
根据DMA buffer的特性,DMA操作有两种:一种是streaming,DMA buffer是一次性的,用完就算。这种DMA buffer需要自己考虑cache一致性。另外一种是DMA buffer是cache coherent的,软件实现上比较简单,更重要的是这种DMA buffer往往是静态的、长时间存在的。不同类型的DMA操作可能有有不同的寻址限制,也可能相同。如果相同,我们可以用上面这个接口设定streaming和coherent两种DMA 操作的地址掩码。如果不同,可以下面的接口进行设定:
int dma_set_mask(struct device *dev, u64 mask);
int dma_set_coherent_mask(struct device *dev, u64 mask);
前者是设定streaming类型的DMA地址掩码,后者是设定coherent类型的DMA地址掩码。为了更好的理解这些接口,我们聊聊参数和返回值。dev指向该设备的struct device对象,一般来说,这个struct device对象应该是嵌入在bus-specific 的实例中,例如对于PCI设备,有一个struct pci_dev的实例与之对应,而在这里需要传入的dev参数则可以通过&pdev->dev得到(pdev指向struct pci_dev的实例)。mask表示你的设备支持的地址线信息。如果调用这些接口返回0,则说明一切OK,从该设备到指定mask的内存的DMA操作是可以被系统支持的(包括DMA controller、bus layer等)。如果返回值非0,那么说明这样的DMA寻址是不能正确完成的,如果强行这么做将会产生不可预知的后果。驱动必须检测返回值,如果不行,那么建议修改mask或者不使用DMA。也就是说,对上面接口调用失败后,你有三个选择:
1、用另外的mask
2、不使用DMA模式,采用普通I/O模式
3、忽略这个设备的存在,不对其进行初始化
一个可以寻址32 bit的设备,其初始化的示例代码如下:
if (dma_set_mask_and_coherent(dev, DMA_BIT_MASK(32))) {
dev_warn(dev, "mydev: No suitable DMA available\n");
goto ignore_this_device;
}
另一个常见的场景是有64位寻址能力的设备。一般来说我们会首先尝试设定64位的地址掩码,但是这时候有可能会失败,从而将掩码降低为32位。内核之所以会在设定64位掩码的时候失败,这并不是因为平台不能进行64位寻址,而仅仅是因为32位寻址比64位寻址效率更高。例如,SPARC64 平台上,PCI SAC寻址比DAC寻址性能更好。
下面的代码描述了如何确定streaming类型DMA的地址掩码:
int using_dac;
if (!dma_set_mask(dev, DMA_BIT_MASK(64))) {
using_dac = 1;
} else if (!dma_set_mask(dev, DMA_BIT_MASK(32))) {
using_dac = 0;
} else {
dev_warn(dev, "mydev: No suitable DMA available\n");
goto ignore_this_device;
}
设定coherent 类型的DMA地址掩码也是类似的,不再赘述。需要说明的是:coherent地址掩码总是等于或者小于streaming地址掩码,因此,一般来说,我们只要设定了streaming地址掩码成功了,那么使用同样的掩码或者小一些的掩码来设定coherent地址掩码总是会成功,因此这时候我们一般就不检查dma_set_coherent_mask的返回值了,当然,有些设备很奇怪,只能使用coherent DMA,那么这种情况下,驱动需要检查dma_set_coherent_mask的返回值。
五、两种类型的DMA mapping
1、一致性DMA映射(Consistent DMA mappings )
Consistent DMA mapping有下面两种特点:
(1)持续使用该DMA buffer(不是一次性的),因此Consistent DMA总是在初始化的时候进行map,在shutdown的时候unmap。
(2)CPU和DMA controller在发起对DMA buffer的并行访问的时候不需要考虑cache的影响,也就是说不需要软件进行cache操作,CPU和DMA controller都可以看到对方对DMA buffer的更新。实际上一致性DMA映射中的那个Consistent实际上可以称为coherent,即cache coherent。
缺省情况下,coherent mask被设定为低32 bit(0xFFFFFFFF),即便缺省值是OK了,我们也建议你通过接口在驱动中设定coherent mask。
一般使用Consistent DMA mapping的场景包括:
(1)网卡驱动和网卡DMA控制器往往是通过一些内存中的描述符(形成环或者链)进行交互,这些保存描述符的memory一般采用Consistent DMA mapping。
(2)SCSI硬件适配器上的DMA可以主存中的一些数据结构(mailbox command)进行交互,这些保存mailbox command的memory一般采用Consistent DMA mapping。
(3)有些外设有能力执行主存上的固件代码(microcode),这些保存microcode的主存一般采用Consistent DMA mapping。
上面的这些例子有同样的特性:CPU对memory的修改可以立刻被device感知到,反之亦然。一致性映射可以保证这一点。
需要注意的是:一致性的DMA映射并不意味着不需要memory barrier这样的工具来保证memory order,CPU有可能为了性能而重排对consistent memory上内存访问指令。例如:如果在DMA consistent memory上有两个word,分别是word0和word1,对于device一侧,必须保证word0先更新,然后才有对word1的更新,那么你需要这样写代码:
desc->word0 = address;
wmb();
desc->word1 = DESC_VALID;
只有这样才能保证在所有的平台上,给设备驱动可以正常的工作。
此外,在有些平台上,修改了DMA Consistent buffer后,你的驱动可能需要flush write buffer,以便让device侧感知到memory的变化。这个动作类似在PCI桥中的flush write buffer的动作。
2、流式DMA映射(streaming DMA mapping)
流式DMA映射是一次性的,一般是需要进行DMA传输的时候才进行mapping,一旦DMA传输完成,就立刻ummap(除非你使用dma_sync_*的接口,下面会描述)。并且硬件可以为顺序化访问进行优化。
这里的streaming可以被认为是asynchronous,或者是不属于coherent memory范围的。
一般使用streaming DMA mapping的场景包括:
(1)网卡进行数据传输使用的DMA buffer
(2)文件系统中的各种数据buffer,这些buffer中的数据最终到读写到SCSI设备上去,一般而言,驱动会接受这些buffer,然后进行streaming DMA mapping,之后和SCSI设备上的DMA进行交互。
设计streaming DMA mapping这样的接口是为了充分优化硬件的性能,为了打到这个目标,在使用这些接口的时候,你必须清清楚楚的知道调用接口会发生什么。
无论哪种类型的DMA映射都有对齐的限制,这些限制来自底层的总线,当然也有可能是某些总线上的设备有这样的限制。此外,如果系统中的cache并不是DMA coherent的,而且底层的DMA buffer不合其他数据共享cacheline,这样的系统将工作的更好。
六、如何使用coherent DMA mapping的接口?
1、分配并映射dma buffer
为了分配并映射一个较大(page大小或者类似)的coherent DMA memory,你需要调用下面的接口:
dma_addr_t dma_handle;
cpu_addr = dma_alloc_coherent(dev, size, &dma_handle, gfp);
DMA操作总是会涉及具体设备上的DMA controller,而dev参数就是执行该设备的struct device对象的。size参数指明了你想要分配的DMA Buffer的大小,byte为单位。dma_alloc_coherent这个接口也可以在中断上下文调用,当然,gfp参数要传递GFP_ATOMIC标记,gfp是内存分配的flag,dma_alloc_coherent仅仅是透传该flag到内存管理模块。
需要注意的是dma_alloc_coherent分配的内存的起始地址和size都是对齐在page上(类似__get_free_pages的感觉,当然__get_free_pages接受的size参数是page order),如果你的驱动不需要那么大的DMA buffer,那么可以选择dma_pool接口,下面会进一步描述。
如果传入非空的dev参数,即使驱动调用了掩码设置接口函数设定了DMA mask,说明该设备可以访问大于32-bit地址空间的地址,一致性DMA映射的接口函数也一般会默认的返回一个32-bit可寻址的DMA buffer地址。要知道dma mask和coherent dma mask是不同的,除非驱动显示的调用dma_set_coherent_mask()接口来修改coherent dma mask,例如大小大于32-bit地址,dma_alloc_coherent接口函数才会返回大于32-bit地址空间的地址。dma pool接口也是如此。
dma_alloc_coherent函数返回两个值,一个是从CPU角度访问DMA buffer的虚拟地址,另外一个是从设备(DMA controller)角度看到的bus address:dma_handle,驱动可以将这个bus address传递给HW。
即便是请求的DMA buffer的大小小于PAGE SIZE,dma_alloc_coherent返回的cpu虚拟地址和DMA总线地址都保证对齐在最小的PAGE_SIZE上,这个特性确保了分配的DMA buffer有这样的特性:如果page size是64K,即便是驱动分配一个小于或者等于64K的dma buffer,那么DMA buffer不会越过64K的边界。
2、umap并释放dma buffer
当驱动需要umap并释放dma buffer的时候,需要调用下面的接口:
dma_free_coherent(dev, size, cpu_addr, dma_handle);
这个接口函数的dev、size参数上面已经描述过了,而cpu_addr和dma_handle这两个参数就是dma_alloc_coherent() 接口的那两个地址返回值。需要强调的一点就是:和dma_alloc_coherent不同,dma_free_coherent不能在中断上下文中调用。(因为在有些平台上,free DMA的操作会引发TLB维护的操作(从而引发cpu core之间的通信),如果关闭了IRQ会锁死在SMP IPI 的代码中)。
3、dma pool
如果你的驱动需非常多的小的dma buffer,那么dma pool是最适合你的机制。这个概念类似kmem_cache,__get_free_pages往往获取的是连续的page frame,而kmem_cache是批发了一大批page frame,然后自己“零售”。dma pool就是通过dma_alloc_coherent接口获取大块一致性的DMA内存,然后驱动可以调用dma_pool_alloc从那个大块DMA内存中分一个小块的dma buffer供自己使用。具体接口描述就不说了,大家可以自行阅读。
七、DMA操作方向
由于下面的章节会用到DMA操作方向这个概念,因此我们先简单的描述一下,DMA操作方向定义如下:
DMA_BIDIRECTIONAL
DMA_TO_DEVICE
DMA_FROM_DEVICE
DMA_NONE
如果你知道的话,你应该尽可能的提供准确的DMA操作方向。
DMA_TO_DEVICE表示“从内存(dma buffer)到设备”,而 DMA_FROM_DEVICE表示“从设备到内存(dma buffer)”,上面的这些字符定义了数据在DMA操作中的移动方向。
虽然我们强烈要求驱动在知道DMA传输方向的适合,精确的指明是DMA_TO_DEVICE或者DMA_FROM_DEVICE,然而,如果你确实是不知道具体的操作方向,那么设定为DMA_BIDIRECTIONAL也是可以的,表示DMA操作可以执行任何一个方向的的数据搬移。你的平台需要保证这一点可以让DMA正常工作,当然,这也有可能会引入一些性能上的额外开销。
DMA_NONE主要是用于调试。在驱动知道精确的DMA方向之前,可以把它保存在DMA控制数据结构中,在dma方向设定有问题的适合,你可以跟踪dma方向的设置情况,以便定位问题所在。
除了潜在的平台相关的性能优化之外,精确地指定DMA操作方向还有另外一个优点就是方便调试。有些平台实际上在创建DMA mapping的时候,页表(指将bus地址映射到物理地址的页表)中有一个写权限布尔值,这个值非常类似于用户程序地址空间中的页保护。当DMA控制器硬件检测到违反权限设置时(这时候dma buffer设定的是MA_TO_DEVICE类型,实际上DMA controller只能是读dma buffer),这样的平台可以将错误写入内核日志,从而方便了debug。
只有streaming mappings才会指明DMA操作方向,一致性DMA映射隐含的DMA操作方向是DMA_BIDIRECTIONAL。我们举一个streaming mappings的例子:在网卡驱动中,如果要发送数据,那么在map/umap的时候需要指明DMA_TO_DEVICE的操作方向,而在接受数据包的时候,map/umap需要指明DMA操作方向是DMA_FROM_DEVICE。
八、如何使用streaming DMA mapping的接口?
streaming DMA mapping的接口函数可以在中断上下文中调用。streaming DMA mapping有两个版本的接口函数,一个是用来map/umap单个的dma buffer,另外一个是用来map/umap形成scatterlist的多个dma buffer。
1、map/umap单个的dma buffer
map单个的dma buffer的示例如下:
struct device *dev = &my_dev->dev;
dma_addr_t dma_handle;
void *addr = buffer->ptr;
size_t size = buffer->len;dma_handle = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle)) {
goto map_error_handling;
}
umap单个的dma buffer可以使用下面的接口:
dma_unmap_single(dev, dma_handle, size, direction);
当调用dma_map_single()返回错误的时候,你应当调用dma_mapping_error()来处理错误。虽然并不是所有的DMA mapping实现都支持dma_mapping_error这个接口(调用dma_mapping_error函数实际上会调用底层dma_map_ops操作函数集中的mapping_error成员函数),但是调用它来进行出错处理仍然是一个好的做法。这样做的好处是可以确保DMA mapping代码在所有DMA实现中都能正常工作,而不需要依赖底层实现的细节。没有检查错误就使用返回的地址可能会导致程序失败,可能会产生kernel panic或者悄悄的损坏你有用的数据。下面列举了一些不正确的方法来检查DMA mapping错误,之所以是错误的方法是因为这些代码对底层的DMA实现进行了假设。顺便说的是虽然这里是使用dma_map_single作为示例,实际上也是适用于dma_map_page()的。
错误示例一:
dma_addr_t dma_handle;
dma_handle = dma_map_single(dev, addr, size, direction);
if ((dma_handle & 0xffff != 0) || (dma_handle >= 0x1000000)) {
goto map_error;
}
错误示例二:
dma_addr_t dma_handle;
dma_handle = dma_map_single(dev, addr, size, direction);
if (dma_handle == DMA_ERROR_CODE) {
goto map_error;
}
当DMA传输完成的时候,程序应该调用dma_unmap_single()函数umap dma buffer。例如:在DMA完成传输后会通过中断通知CPU,而在interrupt handler中可以调用dma_unmap_single()函数。dma_map_single函数在进行DMA mapping的时候使用的是CPU指针(虚拟地址),这样就导致该函数有一个弊端:不能使用HIGHMEM memory进行mapping。鉴于此,map/unmap接口提供了另外一个类似的接口,这个接口不使用CPU指针,而是使用page和page offset来进行DMA mapping:
struct device *dev = &my_dev->dev;
dma_addr_t dma_handle;
struct page *page = buffer->page;
unsigned long offset = buffer->offset;
size_t size = buffer->len;dma_handle = dma_map_page(dev, page, offset, size, direction);
if (dma_mapping_error(dev, dma_handle)) {
goto map_error_handling;
}...
dma_unmap_page(dev, dma_handle, size, direction);
在上面的代码中,offset表示一个指定page内的页内偏移(以Byte为单位)。和dma_map_single接口函数一样,调用dma_map_page()返回错误后需要调用dma_mapping_error() 来进行错误处理,上面都已经描述了,这里不再赘述。当DMA传输完成的时候,程序应该调用dma_unmap_page()函数umap dma buffer。例如:在DMA完成传输后会通过中断通知CPU,而在interrupt handler中可以调用dma_unmap_page()函数。
2、map/umap多个形成scatterlist的dma buffer
在scatterlist的情况下,你要映射的对象是分散的若干段DMA buffer,示例代码如下:
int i, count = dma_map_sg(dev, sglist, nents, direction);
struct scatterlist *sg;for_each_sg(sglist, sg, count, i) {
hw_address[i] = sg_dma_address(sg);
hw_len[i] = sg_dma_len(sg);
}
上面的代码中nents说明了sglist中条目的数量(即map多少段dma buffer)。
具体DMA映射的实现是自由的,它可以把scatterlist 中的若干段连续的DMA buffer映射成一个大块的,连续的bus address region。例如:如果DMA mapping是以PAGE_SIZE为粒度进行映射,那么那些分散的一块块的dma buffer可以被映射到一个对齐在PAGE_SIZE,然后各个dma buffer依次首尾相接的一个大的总线地址区域上。这样做的好处就是对于那些不支持(或者支持有限)scatter-gather 的DMA controller,仍然可以通过mapping来实现。dma_map_sg调用识别的时候返回0,当调用成功的时候,返回成功mapping的数目。
一旦调用成功,你需要调用for_each_sg来遍历所有成功映射的mappings(这个数目可能会小于nents)并且使用sg_dma_address() 和 sg_dma_len() 这两个宏来得到mapping后的dma地址和长度。
umap多个形成scatterlist的dma buffer是通过下面的接口实现的:
dma_unmap_sg(dev, sglist, nents, direction);
再次强调,调用dma_unmap_sg的时候要确保DMA操作已经完成。另外,传递给dma_unmap_sg的nents参数需要等于传递给dma_map_sg的nents参数,而不是该函数返回的count。
由于DMA地址空间是共享资源,每一次dma_map_{single,sg}() 的调用都需要有其对应的dma_unmap_{single,sg}(),如果你总是分配dma地址资源而不回收,那么系统将会由于DMA address被用尽而陷入不可用的状态。
3、sync操作
如果你需要多次访问同一个streaming DMA buffer,并且在DMA传输之间读写DMA Buffer上的数据,这时候你需要小心进行DMA buffer的sync操作,以便CPU和设备(DMA controller)可以看到最新的、正确的数据。
首先用dma_map_{single,sg}()进行映射,在完成DMA传输之后,用:
dma_sync_single_for_cpu(dev, dma_handle, size, direction);
或者:
dma_sync_sg_for_cpu(dev, sglist, nents, direction);
来完成sync的操作,以便CPU可以看到最新的数据。
如果,CPU操作了DMA buffer的数据,然后你又想把控制权交给设备上的DMA 控制器,让DMA controller访问DMA buffer,这时候,在真正让HW(指DMA控制器)去访问DMA buffer之前,你需要调用:
dma_sync_single_for_device(dev, dma_handle, size, direction);
或者:
dma_sync_sg_for_device(dev, sglist, nents, direction);
以便device(也就是设备上的DMA控制器)可以看到cpu更新后的数据。此外,需要强调的是:传递给dma_sync_sg_for_cpu() 和 dma_sync_sg_for_device()的ents参数需要等于传递给dma_map_sg的nents参数,而不是该函数返回的count。
在完成最后依次DMA传输之后,你需要调用DMA unmap函数dma_unmap_{single,sg}()。如果在第一次dma_map_*() 调用和dma_unmap_*()之间,你从来都没有碰过DMA buffer中的数据,那么你根本不需要调用dma_sync_*() 这样的sync操作。
下面的例子给出了一个sync操作的示例:
my_card_setup_receive_buffer(struct my_card *cp, char *buffer, int len)
{
dma_addr_t mapping;mapping = dma_map_single(cp->dev, buffer, len, DMA_FROM_DEVICE);
if (dma_mapping_error(cp->dev, mapping)) {
goto map_error_handling;
}cp->rx_buf = buffer;
cp->rx_len = len;
cp->rx_dma = mapping;give_rx_buf_to_card(cp);
}...
my_card_interrupt_handler(int irq, void *devid, struct pt_regs *regs)
{
struct my_card *cp = devid;...
if (read_card_status(cp) == RX_BUF_TRANSFERRED) {
struct my_card_header *hp;HW已经完成了传输,在cpu访问buffer之前,cpu需要先sync一下,以便看到最新的数据。
dma_sync_single_for_cpu(&cp->dev, cp->rx_dma,
cp->rx_len,
DMA_FROM_DEVICE);sync之后就可以安全的读dma buffer了
hp = (struct my_card_header *) cp->rx_buf;
if (header_is_ok(hp)) {
dma_unmap_single(&cp->dev, cp->rx_dma, cp->rx_len,
DMA_FROM_DEVICE);
pass_to_upper_layers(cp->rx_buf);
make_and_setup_new_rx_buf(cp);
} else {
give_rx_buf_to_card(cp);
}
}
}
当使用了这套DMA mapping接口后,驱动不应该再使用virt_to_bus() 这个接口了,当然bus_to_virt()也不行。不过,如果你的驱动使用了这些接口怎么办呢?其实这套新的DMA mapping接口没有和virt_to_bus、bus_to_virt()一一对应的接口,因此,为了让你的程序能工作,你需要对驱动程序进行小小的修改:你必须要保存从dma_alloc_coherent()、dma_pool_alloc()以及dma_map_single()接口函数返回的dma address(对于dma_map_sg()这个接口,dma地址保存在scatterlist 中,当然这需要硬件支持dynamic DMA mapping ),并把这个dma address保存在驱动的数据结构中,并且同时/或者保存在硬件的寄存器中。
所有的驱动代码都需要迁移到DMA mapping framework的接口函数上来。目前内核已经计划完全移除virt_to_bus() 和bus_to_virt() 这两个函数,因为它们已经过时了。有些平台由于不能正确的支持virt_to_bus() 和bus_to_virt(),因此根本就没有提供这两个接口。
九、错误处理
DMA地址空间在某些CPU架构上是有限的,因此分配并mapping可能会产生错误,我们可以通过下面的方法来判定是否发生了错误:
(1)检查是否dma_alloc_coherent() 返回了NULL或者dma_map_sg 返回0
(2)检查dma_map_single和dma_map_page返回了dma address(通过dma_mapping_error函数)
dma_addr_t dma_handle;
dma_handle = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle)) {
goto map_error_handling;
}
(3)当在mapping多个page的时候,如果中间发生了mapping error,那么需要对那些已经mapped的page进行unmap的操作。下面的示例代码用dma_map_single函数,对于dma_map_page也一样适用。
示例代码一:
dma_addr_t dma_handle1;
dma_addr_t dma_handle2;dma_handle1 = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle1)) {
goto map_error_handling1;
}
dma_handle2 = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle2)) {
goto map_error_handling2;
}...
map_error_handling2:
dma_unmap_single(dma_handle1);
map_error_handling1:
示例代码二(如果我们在循环中mapping dma buffer,当在中间出错的时候,一样要unmap所有已经映射的dma buffer):
dma_addr_t dma_addr;
dma_addr_t array[DMA_BUFFERS];
int save_index = 0;for (i = 0; i < DMA_BUFFERS; i++) {
...
dma_addr = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_addr)) {
goto map_error_handling;
}
array[i].dma_addr = dma_addr;
save_index++;
}...
map_error_handling:
for (i = 0; i < save_index; i++) {
...
dma_unmap_single(array[i].dma_addr);
}
如果在网卡驱动的tx回调函数(例如ndo_start_xmit)中出现了DMA mapping失败,那么驱动必须调用dev_kfree_skb() 来是否socket buffer并返回NETDEV_TX_OK 。这表示这个socket buffer由于错误而丢弃掉了。
如果在SCSI driver的queue command回调函数中出现了DMA mapping失败,那么驱动必须返回SCSI_MLQUEUE_HOST_BUSY 。这意味着SCSI子系统稍后会再次重传该command给driver。
十、优化数据结构
在很多的平台上,dma_unmap_{single,page}()其实什么也没有做,是空函数。因此,跟踪映射的dma address及其长度基本上就是浪费内存空间。为了方便驱动工程师编写代码方便,我们提供了几个实用工具(宏定义),如果没有它们,驱动程序中将充分ifdef或者类似的一些“work around”。下面我们并不是一个个的介绍这些宏定义,而是给出一些示例代码,驱动工程师可以照葫芦画瓢。
1、DEFINE_DMA_UNMAP_{ADDR,LEN}。在DMA buffer数据结构中使用这个宏定义,具体例子如下:
before:
struct ring_state {
struct sk_buff *skb;
dma_addr_t mapping;
__u32 len;
};after:
struct ring_state {
struct sk_buff *skb;
DEFINE_DMA_UNMAP_ADDR(mapping);
DEFINE_DMA_UNMAP_LEN(len);
};
根据CONFIG_NEED_DMA_MAP_STATE的配置不同,DEFINE_DMA_UNMAP_{ADDR,LEN}可能是定义相关的dma address和长度的成员,也可能是空。
2、dma_unmap_{addr,len}_set()。使用该宏定义来赋值,具体例子如下:
before:
ringp->mapping = FOO;
ringp->len = BAR;after:
dma_unmap_addr_set(ringp, mapping, FOO);
dma_unmap_len_set(ringp, len, BAR);
3、dma_unmap_{addr,len}(),使用该宏来访问变量。
before:
dma_unmap_single(dev, ringp->mapping, ringp->len,
DMA_FROM_DEVICE);after:
dma_unmap_single(dev,
dma_unmap_addr(ringp, mapping),
dma_unmap_len(ringp, len),
DMA_FROM_DEVICE);
上面的这些代码基本是不需要解释你就会明白的了。另外,我们对于dma address和len是分开处理的,因为在有些实现中,unmaping的操作仅仅需要dma address信息就够了。
十一、平台移植需要注意的问题
如果你仅仅是驱动工程师,并不负责将linux迁移到某个cpu arch上去,那么后面的内容其实你可以忽略掉了。
1、Struct scatterlist的需求
如果cpu arch支持IOMMU(包括软件模拟的IOMMU),那么你需要打开CONFIG_NEED_SG_DMA_LENGTH 这个内核选项。
2、ARCH_DMA_MINALIGN
CPU体系结构相关的代码必须要要保证kmalloc分配的buffer是DMA-safe的(kmalloc分配的buffer也是有可能用于DMA buffer),驱动和内核子系统的正确运行都是依赖这个条件的。如果一个cpu arch不是全面支持DMA-coherent的(例如硬件并不保证cpu cache中的数据等于main memory中的数据),那么必须定义ARCH_DMA_MINALIGN。而通过这个宏定义,kmalloc分配的buffer可以保证对齐在ARCH_DMA_MINALIGN上,从而保证了kmalloc分配的DMA Buffer不会和其他的buffer共享一个cacheline。想要了解具体的实例可以参考arch/arm/include/asm/cache.h。
另外,请注意:ARCH_DMA_MINALIGN 是DMA buffer的对齐约束,你不需要担心CPU ARCH的数据对齐约束(例如,有些CPU arch要求有些数据对象需要64-bit对齐)。
十二、后记
如果没有来自广大人民群众的反馈和建议,这份文档(包括DMA API本身)可能会显得过时,陈旧。
此外,对这份文档有帮助的人如下(没有按照什么特别的顺序):
Russell King <rmk@arm.linux.org.uk>
Leo Dagum <dagum@barrel.engr.sgi.com>
Ralf Baechle <ralf@oss.sgi.com>
Grant Grundler <grundler@cup.hp.com>
Jay Estabrook <jay.estabrook@compaq.com>
Thomas Sailer <sailer@ife.ee.ethz.ch>
Andrea Arcangeli <andrea@suse.de>
Jens Axboe <jens.axboe@oracle.com>
David Mosberger-Tang davidm@hpl.hp.com
备注:本文基本上是内核文档DMA-API-HOWTO.txt的翻译,如果有兴趣可以参考原文。















 5342
5342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









