









线程不安全的HashMap
众所周知,HashMap是非线程安全的。而 ConcurrentHashMap 是 线程安全的,由于 ConcurrentHashMap 的源代码实现依赖于 Java 内存模型 ,所以我们要线对java内存模型有一定的了解
Java 内存模型
在Java多线程中我们经常会涉及到两个概念就是线程之间是如何通信和线程之间的同步.Java 语言的内存模型由一些规则组成,这些规则确定线程对内存的访问如何排序以及何时可以确保它们对线程是可见的。
原子性,指令有序性,线程可见性
- 重排序(内存屏障)
- 内存可见性(volatile)
- Happens-before 关系
- compare and swap(比较与交换)
ConcurrentHashMap ( JDK1.7 )
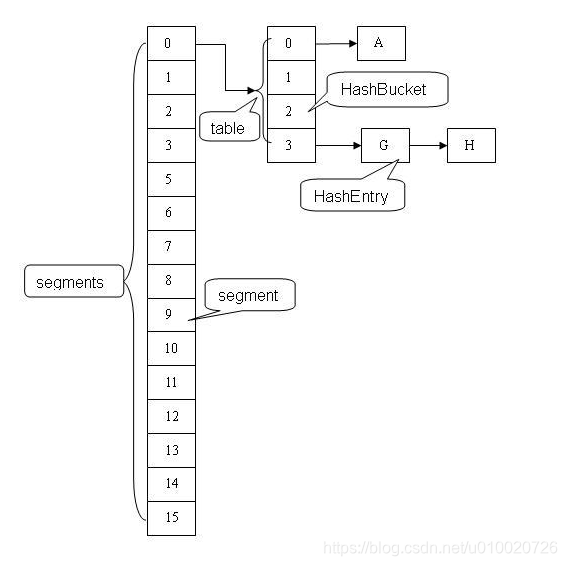
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 继承了ReentrantLock, 用来充当锁的角色,每一个Segment元素存储的是一个HashEntry数组+链表,和HashMap的数据存储结构一样。
public V put(K key, V value) {
if (value == null) //ConcurrentHashMap 中不允许用 null 作为映射值
throw new NullPointerException();
int hash = hash(key.hashCode()); // 计算键对应的散列码
// 根据散列码找到对应的 Segment
return segmentFor(hash).put(key, hash, value, false);
}
/**
* 使用 key 的散列码来得到 segments 数组中对应的 Segment
*/
final Segment<K,V> segmentFor(int hash) {
// 将散列值右移 segmentShift 个位,并在高位填充 0
// 然后把得到的值与 segmentMask 相“与”
// 从而得到 hash 值对应的 segments 数组的下标值
// 最后根据下标值返回散列码对应的 Segment 对象
return segments[(hash >>> segmentShift) & segmentMask];
}
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); // 加锁,这里是锁定某个 Segment 对象而非整个 ConcurrentHashMap
try {
int c = count;
if (c++ > threshold) // 如果超过再散列的阈值
rehash(); // 执行再散列,table 数组的长度将扩充一倍
HashEntry<K,V>[] tab = table;
// 把散列码值与 table 数组的长度减 1 的值相“与”
// 得到该散列码对应的 table 数组的下标值
int index = hash & (tab.length - 1);
// 找到散列码对应的具体的那个桶
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) { // 如果键 / 值对以经存在
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value; // 设置 value 值
}
else { // 键 / 值对不存在
oldValue = null;
++modCount; // 要添加新节点到链表中,所以 modCont 要加 1
// 创建新节点,并添加到链表的头部
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // 写 count 变量
}
return oldValue;
} finally {
unlock(); // 解锁
}
}
// size 实现片段
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) { // 计算了两次的modcount不一致, RETRIES_BEFORE_LOCK=2
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // 对每个segment加锁
}
sum = 0L; // 统计modCount
size = 0;
overflow = false; // 超出界限了
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 连续两次得到的结果一致,则认为这个结果是正确的
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock(); // 解锁
}
}
Put实现: 当执行put方法插入数据时,首先根据key的hash码取得Segment的定位,拿到分段,如果没有hash码定位的Segment则新建,然后将put操作委托给分段Segment。接着执行Segment对象的put方法通过加锁机制插入数据
get实现:ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。
size实现(乐观方法)先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数;
ConcurrentHashMap ( JDK1.8 )
JDK 1.8 中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全
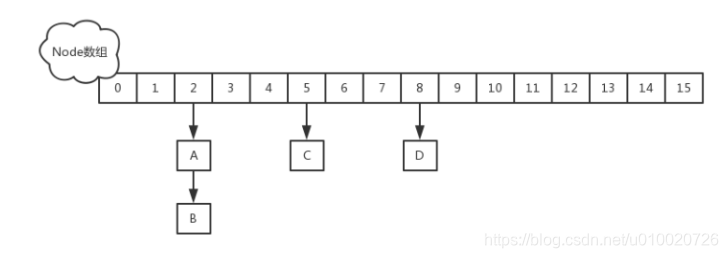
/**
* sizeCtl
* 用于控制table初始化和resize的参数
* -1表示初始化
* 其他负数+1表示正在进行resize的线程数,为了与-1区别开
* 0代表默认状态
* 在初始化之后,该值表示下次需要resize时map内元素的个数
* DEFAULT_CAPACITY table的初始容量, 默认为16
*/
private transient volatile int sizeCtl;
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//sizeCtl 小于零说明已经有线程正在进行初始化操作
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
//sc 大于零说明容量已经初始化了,否则使用默认容量
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
Put实现: 当执行put方法插入数据时,根据key的hashcode再哈希,在Node数组中找到对应的位置实现 分以下几种
1、当相应位置的Node还未初始化,则使用CAS插入相应的数据;
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
2、如果相应位置的Node不为空,且当前该节点不处于移动状态,则对该节点加synchronized锁,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
}
3、如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
4、如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值;
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
5、如果插入的是一个新节点,则执行addCount()方法尝试更新元素个数baseCount;
get实现:计算hash值,定位到该table索引位置,如果是首节点符合就返回
如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
size实现 使用的一个volatile类型的变量 baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount,实现如下:
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 如果计数盒子不是空 或者
// 如果修改 baseCount 失败
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
// 如果计数盒子是空(尚未出现并发)
// 如果随机取余一个数组位置为空 或者
// 修改这个槽位的变量失败(出现并发了)
// 执行 fullAddCount 方法。并结束
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
// 如果需要检查,检查是否需要扩容,在 putVal 方法调用时,默认就是要检查的。
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
// 如果map.size() 大于 sizeCtl(达到扩容阈值需要扩容) 且
// table 不是空;且 table 的长度小于 1 << 30。(可以扩容)
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
// 根据 length 得到一个标识
int rs = resizeStamp(n);
// 如果正在扩容
if (sc < 0) {
// 如果 sc 的低 16 位不等于 标识符(校验异常 sizeCtl 变化了)
// 如果 sc == 标识符 + 1 (扩容结束了,不再有线程进行扩容)(默认第一个线程设置 sc ==rs 左移 16 位 + 2,当第一个线程结束扩容了,就会将 sc 减一。这个时候,sc 就等于 rs + 1)
// 如果 sc == 标识符 + 65535(帮助线程数已经达到最大)
// 如果 nextTable == null(结束扩容了)
// 如果 transferIndex <= 0 (转移状态变化了)
// 结束循环
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 如果可以帮助扩容,那么将 sc 加 1. 表示多了一个线程在帮助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
// 扩容
transfer(tab, nt);
}
// 如果不在扩容,将 sc 更新:标识符左移 16 位 然后 + 2. 也就是变成一个负数。高 16 位是标识符,低 16 位初始是 2.
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 更新 sizeCtl 为负数后,开始扩容。
transfer(tab, null);
s = sumCount();
}
}
}
总结
其实可以看出JDK1.8版本的ConcurrentHashMap,只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑
- 1.8 降低了锁的粒度 JDK1.7版本锁的粒度是Segment ,而JDK1.8锁的粒度就是HashEntry
- JDK1.8使用红黑树来优化链表
- JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock
减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。














 1133
1133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









