







1 全文检索概述
我们处理的数据包含两类,一是具有固定格式或有限长度的结构化数据,如数据库、元数据等;另一个是非结构化的数据,如图片、邮件、word文档等。对结构化数据的存储和查询技术比较简单和成熟,可以利用数据的结构特点利用一些算法快速定位数据,效率较高。而对非结构化数据进行检索相对复杂,最原始的方法是顺序扫描,如grep命令,顺序扫描的缺点是显而易见的,每次检索海量数据都进行全范围扫描是不可取和不现实的。另一种方法是将非结构化的数据结构化,然后利用结构化数据查询的方法进行查询。索引就是这个思路的一个实现方式。所谓索引就是从非结构化数据中提取并重新组织的结构化数据,用于提高数据检索的效率。
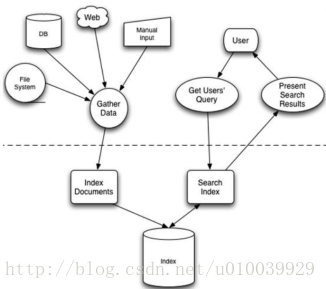
一般全文检索包含两个基本过程:创建索引和搜索索引。
创建索引的过程主要包括下面几个步骤:
- 导入原始数据,如文档;
- 对导入的数据进行处理统计,创建词典和反向索引表;
- 将索引数据持久化到硬盘。
搜索索引的过程主要包括以下几个步骤:
- 获取查询语句;
- 分析查询语句,得到查询树(一种描述查询逻辑的树形结构);
- 利用查询树搜索索引,得到每个词的原始数据链表,对链表进行交、差、并运算得到结果集;
- 按与查询语句的相关性对结果集进行排序;
- 返回排序后的结果集。
2 Solr简介
2.1 Solr服务器框架
Solr是一个Java Web应用,可以运行在主流的Web容器上,如Jetty、tomcat等。Solr的主要模块如下图所示:
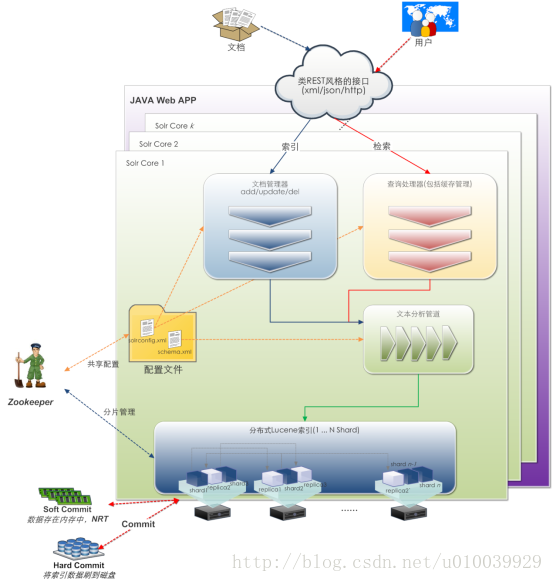
- 每一个Solr引擎都可以包含多个核(Solr Core);
- 索引更新处理器(Update Processors)主要用来处理索引请求,如去重复、语言检测等;
- 搜索组件(Search Components)主要用于处理检索请求和结果,如拼写检查、Faceting、高亮、聚合等;
- 文本分析器(Text Analysis)主要对检索条件、索引文档进行分词、过滤等操作;
- Solr4.0支持分布式索引和检索,节点越多,Solr服务的检索性能越好,并且支持的文档数越多;
- Solr4.0通过副本的形式来保证索引数据的安全,数据的备份数越多,容错能力越强。同时,并发检索的吞吐量也越大(Queries per Second);
Solr支持两种提交方式,Soft Commit和Hard Commit。Soft Commit是指要索引文档在solr服务器的缓存中完成索引的建立而没有持久化就算完成了索引过程的一种索引请求提交方式。Hard Commit只有在文档索引建立完成并持久化后才返回给客户端。Soft Commit可以用于近实时检索(Near Real Time Search)。
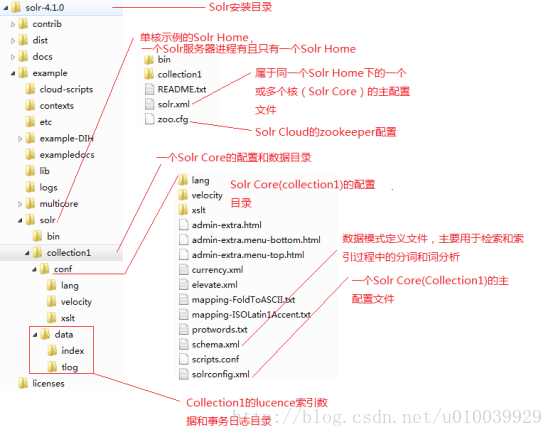
2.2 Solr目录结构
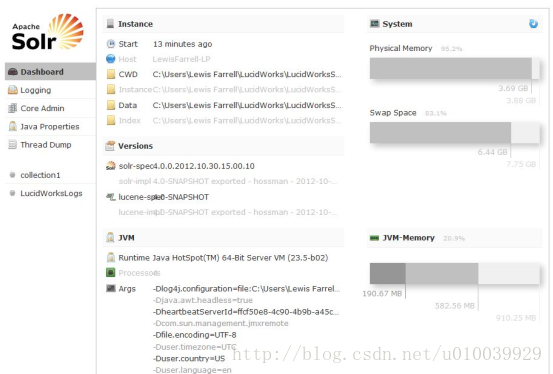
2.3 Solr Admin
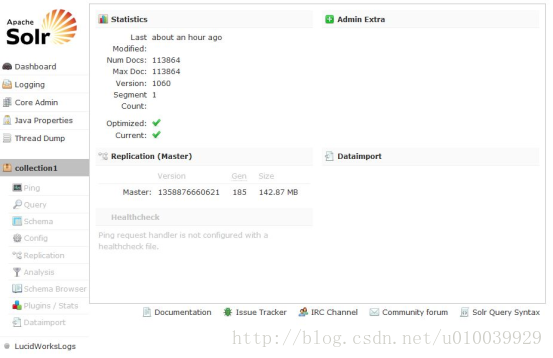
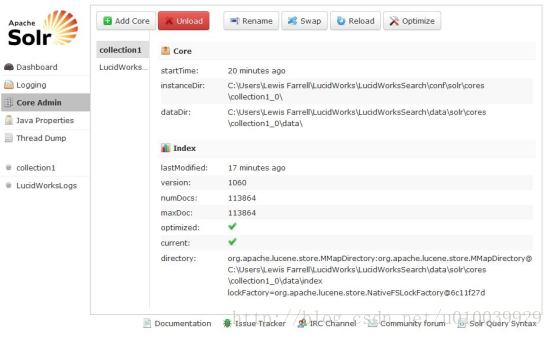
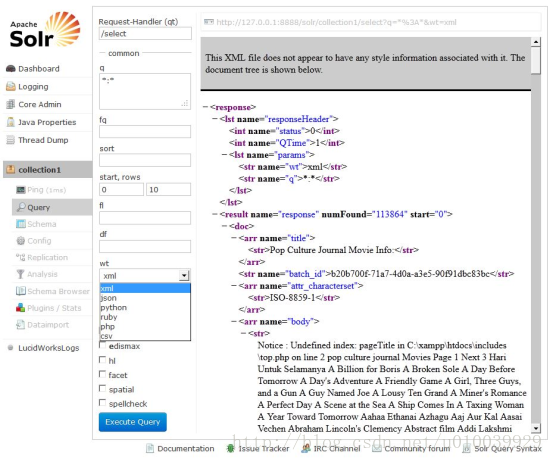
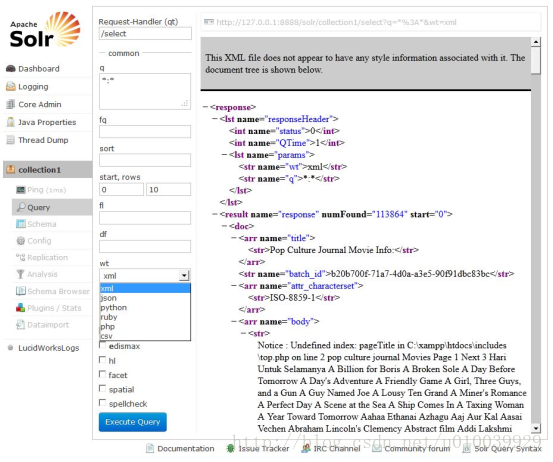
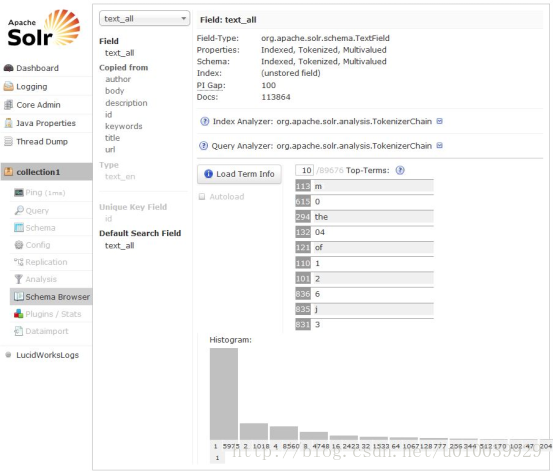
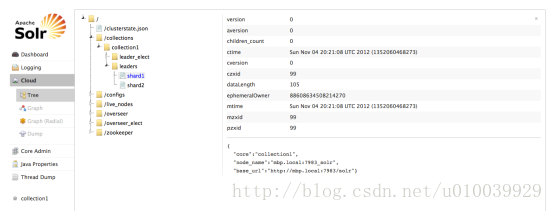
Solr Admin是一个Web客户端,通过它可以配置、监控、使用Solr检索服务器。

2.4 Solr的配置
Solr的配置主要有三个:Solr.xml、solrconfig.xml和schema.xml。其中,Solr.xml是Solr Instance的核心配置,solrconfig.xml和schema.xml则为solr core的配置,solrconfig.xml配置了一个solr core的索引器和检索器,schema.xml则为该Solr core的文本分析器的配置。
2.4.1 solr.xml
<solr persistent="true">
<cores
adminPath="/admin/cores"
defaultCoreName="collection1"
host="${host:}"
hostPort="${jetty.port:}"
hostContext="${hostContext:}"
zkClientTimeout="${zkClientTimeout:15000}">
<core name="collection1" instanceDir="collection1"/>
</cores>
</solr>2.4.2 solrconfig.xml
1、索引配置
indexConfig标记段定义了控制Solr索引处理的一些因素.
useCompoundFile:通过将很多 Lucene 内部文件整合到单一一个文件来减少使用中的文件的数量。这可有助于减少 Solr 使用的文件句柄数目,代价是降低了性能。除非是应用程序用完了文件句柄,否则 false 的默认值应该就已经足够。
mergeFacor:决定Lucene段被合并的频率。较小的值(最小为2)使用的内存较少但导致的索引时间也更慢。较大的值可使索引时间变快但会牺牲较多的内存。(典型的时间与空间 的平衡配置)
maxBufferedDocs:在合并内存中文档和创建新段之前,定义所需索引的最小文档数。段是用来存储索引信息的Lucene文件。较大的值可使索引时间变快但会牺牲较多内存。
maxMergeDocs:控制可由Solr合并的 Document 的最大数。较小的值(<10,000)最适合于具有大量更新的应用程序。
maxFieldLength:对于给定的Document,控制可添加到Field的最大条目数,进而阶段该文档。如果文档可能会很大,就需要增加这个数值。然后,若将这个值设置得过高会导致内存不足错误。
unlockOnStartup:告知Solr忽略在多线程环境中用来保护索引的锁定机制。在某些情况下,索引可能会由于不正确的关机或其他错误而一直处于锁定,这就妨碍了添加和更新。将其设置为true可以禁用启动索引,进而允许进行添加和更新。(锁机制)
2、查询处理配置
query标记段中以下一些与缓存无关的特性:
maxBooleanClauses:定义可组合在一起形成以个查询的字句数量的上限。正常情况1024已经足够。如果应用程序大量使用了通配符或范围查询,增加这个限制将能避免当值超出时,抛出TooMangClausesException。
enableLazyFieldLoading:如果应用程序只会检索Document上少数几个Field,那么可以将这个属性设置为 true。懒散加载的一个常见场景大都发生在应用程序返回一些列搜索结果的时候,用户常常会单击其中的一个来查看存储在此索引中的原始文档。初始的现实常常只需要现实很短的一段信息。若是检索大型的Document,除非必需,否则就应该避免加载整个文档。
query部分负责定义与在Solr中发生的时间相关的几个选项:
Solr(实际上是Lucene)使用称为Searcher的Java类来处理Query实例。Searcher将索引内容相关的数据加载到内存中。根据索引、CPU已经可用内存的大小,这个过程可能需要较长的一段时间。要改进这一设计和显著提高性能,Solr引入了一张”温暖”策略,即把这些新的Searcher联机以便为现场用户提供查询服务之前,先对它们进行”热身”。
newSearcher和firstSearcher事件,可以使用这些事件来制定实例化新Searcher或第一个Searcher时,应该执行哪些查询。如果应用程序期望请求某些特定的查询,那么在创建新Searcher或第一个Searcher时就应该反注释这些部分并执行适当的查询。
3、query中的智能缓存:
filterCache:通过存储一个匹配给定查询的文档 id 的无序集,过滤器让 Solr 能够有效提高查询的性能。缓存这些过滤器意味着对Solr的重复调用可以导致结果集的快速查找。更常见的场景是缓存一个过滤器,然后再发起后续的精炼查询,这种查询能使用过滤器来限制要搜索的文档数。
queryResultCache:为查询、排序条件和所请求文档的数量缓存文档 id 的有序集合。
documentCache:缓存Lucene Document,使用内部Lucene文档id(以便不与Solr唯一id相混淆)。由于Lucene的内部Document id 可以因索引操作而更改,这种缓存不能自热。
Named caches:命名缓存是用户定义的缓存,可被 Solr定制插件 所使用。
其中filterCache、queryResultCache、Named caches(如果实现了org.apache.solr. search.CacheRegenerator)可以自热。每个缓存声明都接受最多四个属性:
class:是缓存实现的Java名
size:是最大的条目数
initialSize:是缓存的初始大小
autoWarmCount:是取自旧缓存以预热新缓存的条目数。如果条目很多,就意味着缓存的hit会更多,只不过需要花更长的预热时间。
对于所有缓存模式而言,在设置缓存参数时,都有必要在内存、cpu和磁盘访问之间进行均衡。统计信息管理页(管理员界面的Statistics)对于分析缓存的 hit-to-miss 比例以及微调缓存大小的统计数据都非常有用。而且,并非所有应用程序都会从缓存受益。实际上,一些应用程序反而会由于需要将某个永远也用不到的条目存储在缓存中这一额外步骤而受到影响。
2.4.3 schema.xml
schema.xml位于solr/conf/目录下,类似于数据表配置文件,定义了加入索引的数据的数据类型,主要包括type、fields和其他的一些缺省设置。
1、type节点
type节点定义FieldType子节点,包括name,class,positionIncrementGap等一些参数。
name:就是这个FieldType的名称。
class:指向org.apache.solr.analysis包里面对应的class名称,用来定义这个类型的行为。
< schema name = "example" version = "1.5" >
< types >
< fieldType
name = "string"
class = "solr.StrField"
sortMissingLast = "true"
omitNorms = "true" />
< fieldType
name = "boolean"
class = "solr.BoolField"
sortMissingLast = "true"
omitNorms = "true" />
< fieldtype name = "binary" class = "solr.BinaryField" />
< fieldType name = "int"
class = "solr.TrieIntField" precisionStep = "0" omitNorms = "true"
positionIncrementGap = "0" />
< fieldType name = "float"
class = "solr.TrieFloatField" precisionStep = "0" omitNorms = "true"
positionIncrementGap = "0" />
< fieldType name = "long" class = "solr.TrieLongField" precisionStep = "0"
omitNorms = "true" positionIncrementGap = "0" />
< fieldType name = "double" class = "solr.TrieDoubleField" precisionStep = "0"
omitNorms = "true" positionIncrementGap = "0" />
...
</ types >
...
</ schema > 必要的时候fieldType还需要自己定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤,如下:
< fieldType name = "text_ws" class = "solr.TextField" positionIncrementGap = "100" >
< analyzer >
< tokenizer class = "solr.WhitespaceTokenizerFactory" />
</ analyzer >
</ fieldType >
< fieldType name = "text" class = "solr.TextField" positionIncrementGap = "100" >
< analyzer type = "index" >
<!--这个分词包是空格分词,在向索引库添加text类型的索引时,Solr会首先用空格进行分词,然后把分词结果依次使用指定的过滤器进行过滤,最后剩下的结果,才会加入到索引库中以备查询。 注意:Solr的analysis包并没有带支持中文的包,需要自己添加中文分词器. -->
< tokenizer class = "solr.WhitespaceTokenizerFactory" />
< filter class = "solr.StopFilterFactory"
ignoreCase = "true"
words = "stopwords.txt"
enablePositionIncrements = "true"
/>
< filter class = "solr.WordDelimiterFilterFactory"
generateWordParts = "1"
generateNumberParts = "1"
catenateWords = "1"
catenateNumbers = "1"
catenateAll = "0"
splitOnCaseChange = "1" />
< filter class = "solr.LowerCaseFilterFactory" />
< filter class = "solr.SnowballPorterFilterFactory"
language = "English"
protected = "protwords.txt" />
</ analyzer >
< analyzer type = "query" >
< tokenizer class = "solr.WhitespaceTokenizerFactory" />
< filter class = "solr.SynonymFilterFactory"
synonyms = "synonyms.txt"
ignoreCase = "true"
expand = "true" />
< filter class = "solr.StopFilterFactory"
ignoreCase = "true"
words = "stopwords.txt"
enablePositionIncrements = "true"
/>
< filter class = "solr.WordDelimiterFilterFactory" generateWordParts = "1"
generateNumberParts = "1" catenateWords = "0" catenateNumbers = "0"
catenateAll = "0" splitOnCaseChange = "1" />
< filter class = "solr.LowerCaseFilterFactory" />
< filter class = "solr.SnowballPorterFilterFactory" language = "English"
protected = "protwords.txt" />
</ analyzer >
</ fieldType > 2、fields节点
fields节点内定义具体的字段(类似数据库的字段),含有以下属性:
name:字段名
type:之前定义过的各种FieldType
indexed:是否被索引
stored:是否被存储(如果不需要存储相应字段值,尽量设为false)
multiValued:是否有多个值(对可能存在多值的字段尽量设置为true,避免建索引时抛出错误)
< fields >
< field name = "id" type = "integer" indexed = "true" stored = "true" required = "true" />
< field name = "name" type = "text" indexed = "true" stored = "true" />
< field name = "summary" type = "text" indexed = "true" stored = "true" />
< field name = "author" type = "string" indexed = "true" stored = "true" />
< field name = "date" type = "date" indexed = "false" stored = "true" />
< field name = "content" type = "text" indexed = "true" stored = "false" />
< field name = "keywords" type = "keyword_text" indexed = "true" stored = "false" multiValued = "true" />
<!-拷贝字段->
< field name = "all" type = "text" indexed = "true" stored = "false" multiValued = "true" />
</ fields > 3、copyField节点
建议建立一个拷贝字段,将所有的全文本字段复制到一个字段中,以便进行统一的检索, 以下是拷贝设置:
< copyField source = "name" dest = "all" />
< copyField source = "summary" dest = "all" /> 4、dynamicField节点
dynamicFiel动态字段,没有具体名称的字段,用dynamicField字段。如:name为*_i,定义它的type为int,那么在使用这个字段的时候,任务以_i结果的字段都被认为符合这个定义。如name_i, school_i
< dynamicField name = "*_i" type = "int" indexed = "true" stored = "true" />
< dynamicField name = "*_s" type = "string" indexed = "true" stored = "true" />
< dynamicField name = "*_l" type = "long" indexed = "true" stored = "true" />
< dynamicField name = "*_t" type = "text" indexed = "true" stored = "true" />
< dynamicField name = "*_b" type = "boolean" indexed = "true" stored = "true" />
< dynamicField name = "*_f" type = "float" indexed = "true" stored = "true" />
< dynamicField name = "*_d" type = "double" indexed = "true" stored = "true" />
< dynamicField name = "*_dt" type = "date" indexed = "true" stored = "true" /> 5、其他一些标签
< uniqueKey > id </ uniqueKey >文档的唯一标识, 必须填写这个field(除非该field被标记required=”false”),否则solr建立索引报错。
< defaultSearchField > text </ defaultSearchField >如果搜索参数中没有指定具体的field,那么这是默认的域。
< solrQueryParser defaultOperator =" OR " />配置搜索参数短语间的逻辑,可以是”AND|OR”。














 4871
4871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









