







本文来自于网易云课堂
5 激活函数
搭建一个神经网络时,你可以选择隐藏层中或者输出层中使用什么激活函数(actuation function),到目前为止,我们一直使用的是sigmoid函数,但其他函数效果会更好。
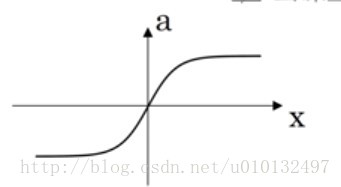
在实际训练中,有个函数表现总是比sigmoid好,叫tanh(双曲正切函数),它的输出是(-1,1),从数学上,它其实是sigmoid函数的平移。
tanh=ez−e(−z)ez−+(−z)
t
a
n
h
=
e
z
−
e
(
−
z
)
e
z
−
+
(
−
z
)
但是这两个函数在z很大或者很小的时候,导数接近与0,这会拖慢梯度下降算法。
目前最受欢迎的修正线性单元Relu(rectified linear unit),它在z大于0的时候导数一直为1.在小于0的情况下,导数为0,但是实际运算中,z同时为0的概率很低。
a=max(0,z)
a
=
m
a
x
(
0
,
z
)
还有一个带泄露的Relu(leaky Relu),这通常比Relu效果好,不过实际使用的频率并不高。
在选择激活函数时有个经验法则:如果输出是0或者1或者二分类问题,输出层激活函数可以选择sigmoid函数,其余全部为Relu。实际使用Relu或者Leaky Relu,神经网络收敛会快的多。
为什么激活函数都要使用非线性函数呢?事实证明,要让你的神经网络计算出有趣的函数,你必须使用非线性函数。因为你如果采用了线性激活函数,那么你的预测输出只不过是输入的线性组合
6 激活函数的导数
当你对神经网络进行反向传播时,你需要计算激活函数的斜率或者导数。利用微积分我们可以轻易的计算常见激活函数的导数。下面给出激活函数的导数公式:
sigmoid function:
dz=a(1−a)
d
z
=
a
(
1
−
a
)
tanh function:
dz=1−a2
d
z
=
1
−
a
2
Relu function:
dz=1ifz>0,dz=0ifz<0
d
z
=
1
i
f
z
>
0
,
d
z
=
0
i
f
z
<
0
leaky dunction
dz=1ifz>0,dz=0.oz,ifz<0
d
z
=
1
i
f
z
>
0
,
d
z
=
0.
o
z
,
i
f
z
<
0
, 这里我们取leaky Relu = max(0.01z, z)
7 梯度下降法
对于2层的神经网络,我们有:
参数:
w[1],b[1],w[2],b[2]
w
[
1
]
,
b
[
1
]
,
w
[
2
]
,
b
[
2
]
成本函数:
J(w[1],b[1],w[2],b[2])
J
(
w
[
1
]
,
b
[
1
]
,
w
[
2
]
,
b
[
2
]
)
那么梯度下降法就可以写成:
repeat{
计算J;
求第一层导数:
dw[1]=dJdw[1]
d
w
[
1
]
=
d
J
d
w
[
1
]
,
db[1]=dJdb[1]
d
b
[
1
]
=
d
J
d
b
[
1
]
求第二层导数:
dw[2]=dJdw[2]
d
w
[
2
]
=
d
J
d
w
[
2
]
,
db[2]=dJdb[2]
d
b
[
2
]
=
d
J
d
b
[
2
]
更新第一层权重:
w[1]=w[1]−αdw[1]
w
[
1
]
=
w
[
1
]
−
α
d
w
[
1
]
,
b[1]=b[1]−αdb[1]
b
[
1
]
=
b
[
1
]
−
α
d
b
[
1
]
更新第二层权重:
w[2]=w[1]−αdw[2]
w
[
2
]
=
w
[
1
]
−
α
d
w
[
2
]
,
b[2]=wb[2]−αdb[2]
b
[
2
]
=
w
b
[
2
]
−
α
d
b
[
2
]
}
这样,我们就实现了一次迭代。每个导数的具体实现只需要根据链式求导方法就可以计算出来。最后结果如下:
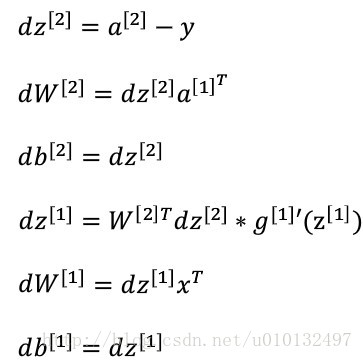
8 随机初始化
对于神经网络的权重不能同时初始化为0,因为这样会发现,所有的节点都是完全对称的,每个节点都在计算相同的函数。这个问题的解决方案是随机初始化所有参数,如 w[1]]=np.random.randn((2,2))∗0.01 w [ 1 ] ] = n p . r a n d o m . r a n d n ( ( 2 , 2 ) ) ∗ 0.01 ,即将其初始化为高斯分布的很小的权重。b其实没有具备的破坏对称性问题,故它可以初始化为0。之所以后面*0.01是因为如果激活函数为sigmoid或者tanh,会减小收敛速度。














 2618
2618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









