







在数据挖掘中,决策树主要有两种类型:
分类树 的输出是样本的类标。
回归树 的输出是一个实数 (例如房子的价格,病人呆在医院的时间等)。
术语分类和回归树 (CART) 包含了上述两种决策树, 最先由Breiman 等提出.分类树和回归树有些共同点和不同点—例如处理在何处分裂的问题。
分类回归树(CART,Classification And Regression Tree)也属于一种决策树,之前我们介绍了基于ID3和C4.5算法的决策树。这里只介绍CART是怎样用于分类的。
分类回归树是一棵二叉树,且每个非叶子节点都有两个孩子,所以对于第一棵子树其叶子节点数比非叶子节点数多1。
CART与ID3区别:
CART中用于选择变量的不纯性度量是Gini指数;
如果目标变量是标称的,并且是具有两个以上的类别,则CART可能考虑将目标类别合并成两个超类别(双化);
如果目标变量是连续的,则CART算法找出一组基于树的回归方程来预测目标变量。
二、构建决策树
构建决策树时通常采用自上而下的方法,在每一步选择一个最好的属性来分裂。 "最好" 的定义是使得子节点中的训练集尽量的纯。不同的算法使用不同的指标来定义"最好"。本部分介绍一中最常见的指标。
有4中不同的不纯度量可以用来发现CART模型的划分,取决于目标变量的类型,对于分类的目标变量,可以选择GINI,双化或有序双化;
对于连续的目标变量,可以使用最小二乘偏差(LSD)或最小绝对偏差(LAD)。
下面我们只讲GINI指数。
GINI指数:
1、是一种不等性度量;
2、通常用来度量收入不平衡,可以用来度量任何不均匀分布;
3、是介于0~1之间的数,0-完全相等,1-完全不相等;
4、总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)
CART分析步骤
1、从根节点t=1开始,从所有可能候选S集合中搜索使不纯性降低最大的划分S*,然后,使用划分S*将节点1(t=1)划分成两个节点t=2和t=3;
2、在t=2和t=3上分别重复划分搜索过程。
基尼不纯度指标
在CART算法中, 基尼不纯度表示一个随机选中的样本在子集中被分错的可能性。基尼不纯度为这个样本被选中的概率乘以它被分错的概率。当一个节点中所有样本都是一个类时,基尼不纯度为零。
假设y的可能取值为{1, 2, ..., m},令fi是样本被赋予i的概率,则基尼指数可以通过如下计算:
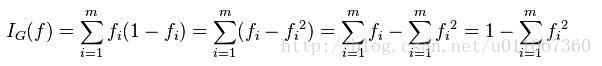
例如:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









