







第二章
1、如何查看分区
2、分区表与普通表对比
--------------------------------华丽的分割线---------------------------------
1、如何查看分区
首先,我们先做一些测试数据,以上一章创建的进货表a为例,为表a添加数据,代码如下:
--为表a添加测试数据
insert [a]
select 1,'矿泉水',100,'2014-01-02' union all
select 2,'方便面',60,'2014-01-03' union all
select 3,'方便面',50,'2014-01-03' union all
select 4,'矿泉水',80,'2014-01-04' union all
select 5,'方便面',60,'2014-01-05' union all
select 6,'方便面',50,'2014-01-06' union all
select 7,'矿泉水',80,'2014-01-06' union all
select 8,'方便面',60,'2014-01-07' union all
select 9,'方便面',50,'2014-01-09' union all
select 10,'矿泉水',80,'2014-01-11'
select * from a
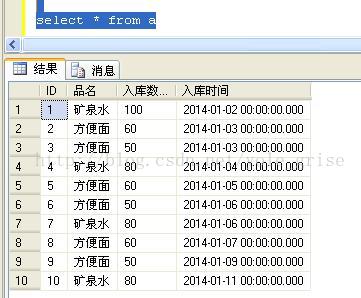
按分区进行查询,代码如下:
--按分区查询
select * from a where $partition.partfunA(id) =1
select * from a where $partition.partfunA(id) =2
select * from a where $partition.partfunA(id) =3
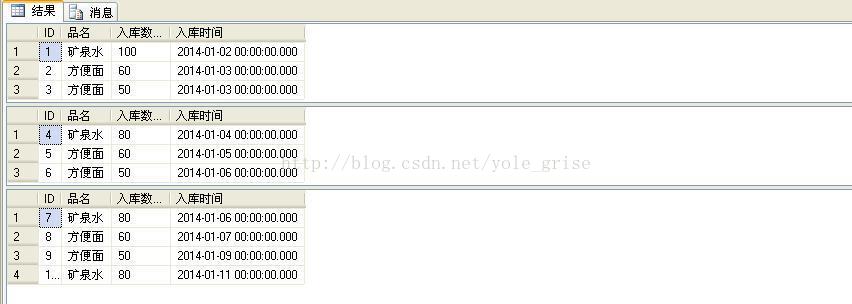
如图2所示,3个区的数据正如我们第一章中创建的分区函数所定的规则一致。
--------------------------------华丽的分割线---------------------------------
2、分区表与普通表对比
创建测试表b,代码如下:
--创建数据库表b,表b为普通表,结构同表a
if object_id('[b]') is not null drop table [b]
go
create table [b]
(
[ID] int,
[品名] varchar(6),
[入库数量] int,
[入库时间] datetime
)
--为表b添加测试数据,数据通表a数据
insert [b]
select 1,'矿泉水',100,'2014-01-02' union all
select 2,'方便面',60,'2014-01-03' union all
select 3,'方便面',50,'2014-01-03' union all
select 4,'矿泉水',80,'2014-01-04' union all
select 5,'方便面',60,'2014-01-05' union all
select 6,'方便面',50,'2014-01-06' union all
select 7,'矿泉水',80,'2014-01-06' union all
select 8,'方便面',60,'2014-01-07' union all
select 9,'方便面',50,'2014-01-09' union all
select 10,'矿泉水',80,'2014-01-11'查看表b属性,如图3所示:
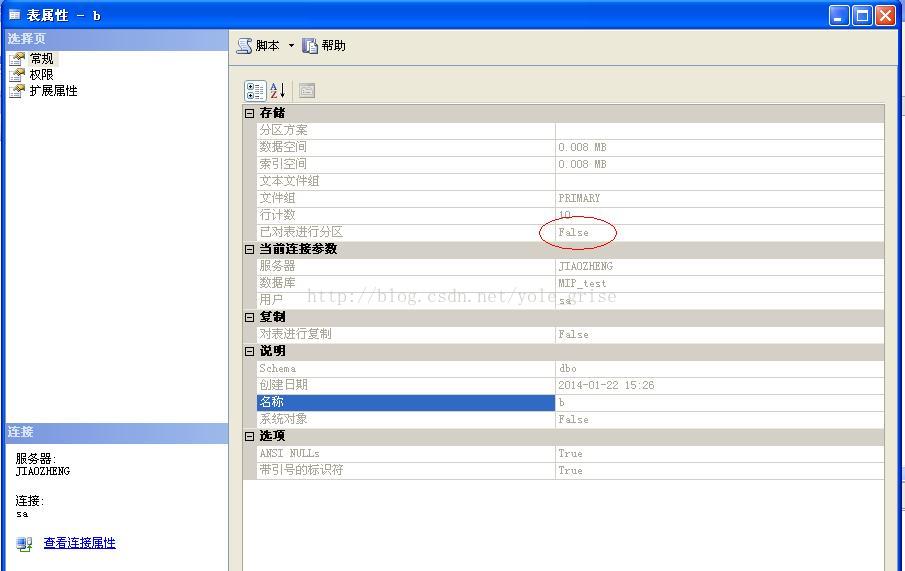
表b为普通表,没有进行分区。
对比开始:
1、全表查询
--全表查询
set statistics io on
select * from a
select * from b
set statistics io off
/*
(10 行受影响)
表 'a'。扫描计数 3,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(10 行受影响)
表 'b'。扫描计数 1,逻辑读取 1 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
*/
我们可以看到,分区后的表a与普通表b,在进行全表查询时,分区表的性能要远远低于普通表。这是因为分区表在全表查询时对所有的分区一一循环扫描,这无形的增加了负担。
2、按条件查询(条件非分区条件),代码如下:
--按条件进行查询(条件非分区条件)
set statistics io on
select * from a where [入库时间]='2014-01-04 00:00:00.000'
select * from b where [入库时间]='2014-01-04 00:00:00.000'
set statistics io off
/*
(1 行受影响)
表 'a'。扫描计数 3,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(1 行受影响)
表 'b'。扫描计数 1,逻辑读取 1 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
*/
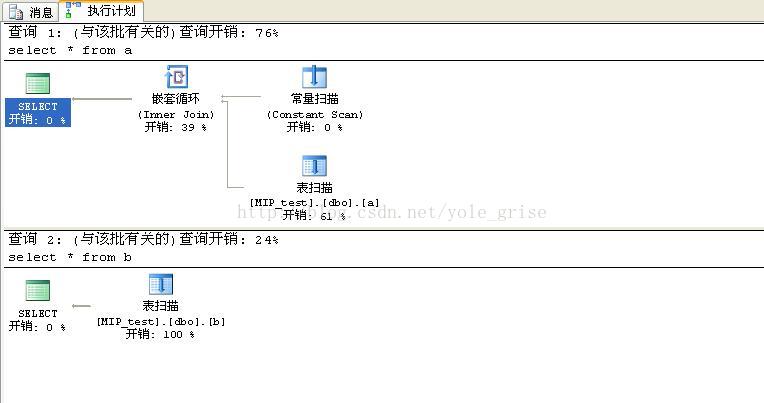
执行计划如图5所示:

我们可以看到,分区后的表a与普通表b,在进行按条件(非分区条件)查询时,分区表的性能要远远低于普通表。这是因为分区表在查询时对所有的分区一一循环扫描,这无形的增加了负担。
3、按条件查询(条件为分区条件),代码如下:
--按分区条件(id)查询
set statistics io on
select * from a where id=1
select * from b where id=1
set statistics io off
/*
(1 行受影响)
表 'a'。扫描计数 1,逻辑读取 1 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(1 行受影响)
表 'b'。扫描计数 1,逻辑读取 1 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
*/执行计划如图6所示:

我们可以看到,分区表a的开销与普通表b的开销一样(可以说是分区表a的开销比起之前开销要少了很多)。由于表中数据量较小,所以分区表与普通表查询开销基本一致。当表中数据越来越大的时候,分区表的开销会远远小于普通表。
通过本章的对比实践,相信大家应该知道何时应该去用分区表了吧。
--------------------------------华丽的分割线----------------------------华丽的分割线---------------------------------
补充一下:我又做了一个大的数据的测试,用来证明表分区的优势,代码如下:
--测试数据
declare @count int
set @count=11
while @count<=10000
begin
insert into a select
@count,'矿泉水',100,'2014-01-23'
set @count=@count+1
end
declare @count int
set @count=11
while @count<=10000
begin
insert into b select
@count,'矿泉水',100,'2014-01-23'
set @count=@count+1
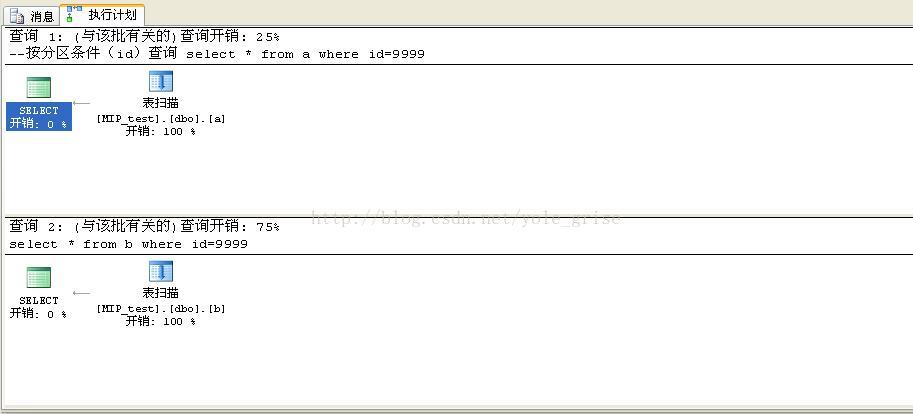
end --按分区条件(id)查询
set statistics io on
select * from a where id=9999
select * from b where id=9999
set statistics io off
/*
(1 行受影响)
表 'a'。扫描计数 1,逻辑读取 47 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(1 行受影响)
表 'b'。扫描计数 1,逻辑读取 47 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
*/














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









