






查看ES信息
查看版本
kibana :
GET /
查看节点信息
GET /_cat/nodes?v
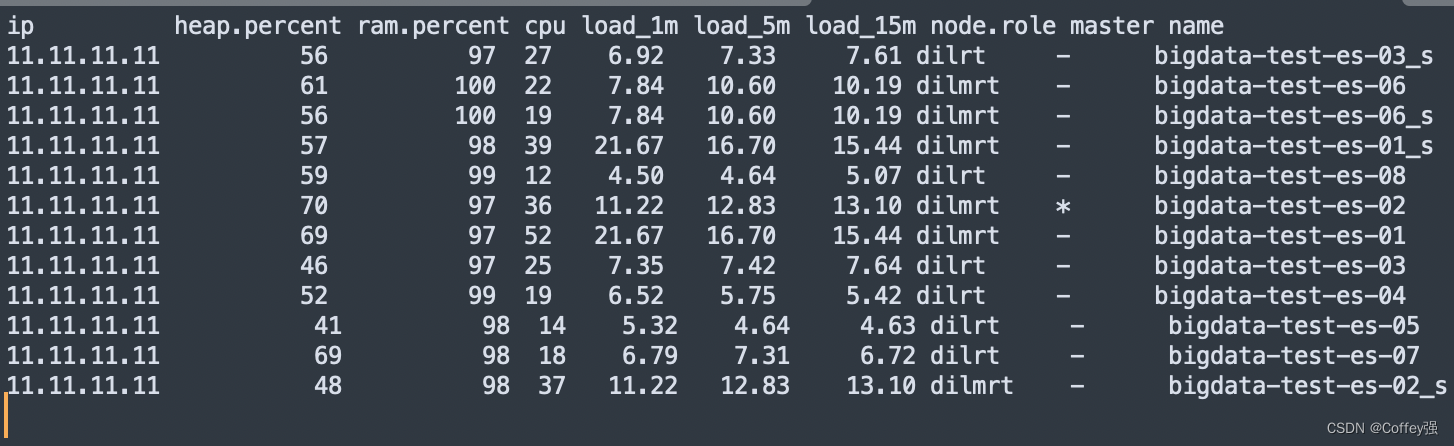
解释:
ip:集群中节点的 ip 地址;
heap.percent:堆内存的占用百分比;
ram.percent:总内存的占用百分比,其实这个不是很准确,因为 buff/cache 和 available 也被当作使用内存;
cpu:cpu 占用百分比;
load_1m:1 分钟内 cpu 负载;
load_5m:5 分钟内 cpu 负载;
load_15m:15 分钟内 cpu 负载;
node.role:上图的dilmrt代表全部权限
master:* 代表是 master 节点,- 代表普通节点;
name:节点的名称。
node.role详解
- master
- data
- ingest
- ml machine learn 机器学习 和xpack有关 这个确实不太懂
- remote_cluster_client
- transform X-pack专用角色 转换节点运行转换并处理转换 API 请求
查看分片信息
首先看下面的图片 数据来源于elk
具体命令是
GET /_cat/shards?v
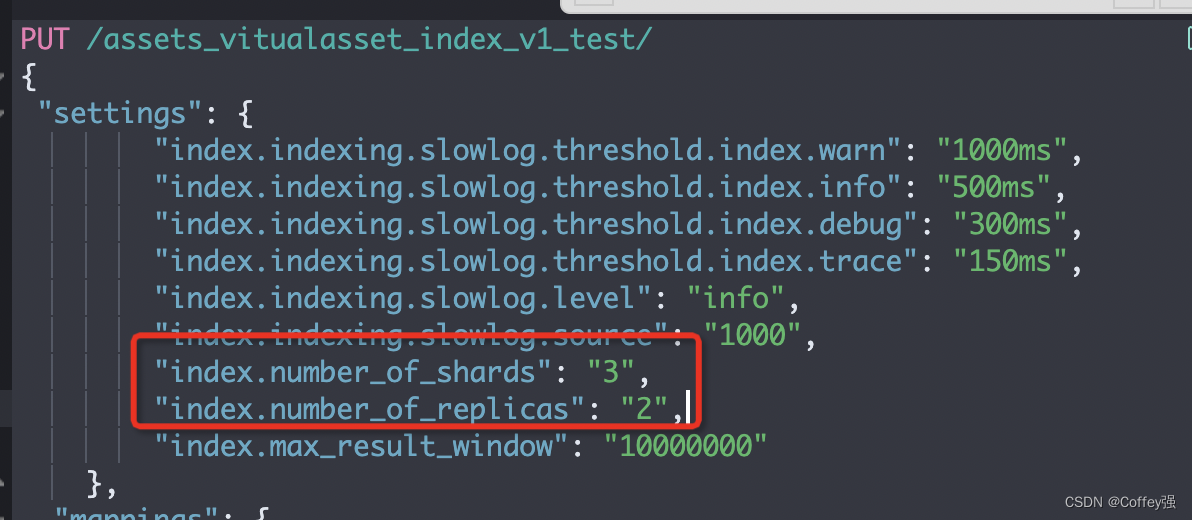
一个名叫assets_vitualasset_index_v1_test 的索引(相当于数据库的表) 这里可以看到有9个 每三个为一组 那么为什么是这样的设定呢

index:索引名称
shard:分片数
prirep:分片类型,p:primary为主分片,r:replicas为复制分片
state:分片状态,STARTED为正常分片,INITIALIZING为异常分片
docs:记录数
store:存储大小
ip:es节点ip
node:es节点名称
请看下图
分片数量为3 代表数据会被均分的切成三份 保证分布式的最大性能 也提高了扩展性 number_of_replicas为副本数量 这个是用来保证高可用的
从上图我们可以看到三个为一组的容量是很接近的 因为这三个存放的内容是相同的 即使有一个节点挂掉也能保证数据正常访问
(节点数量=分片数*(副本数量+1))
实际场景下ES分片及副本数量应该怎么分
/elasticsearch-head可视化工具
首先需要考虑生产环境上总体节点的数量 如实际节点数量为6(三台主机)
那么我们尽量配置成3个分片1个副本 这样数据会很均匀的散落在这6个节点上
如果分成3个分片2个副本可能会造成分布不均匀 从而导致master所在的节点压力过大 master节点尽量不要有太大压力 因为除了数据查询他还有额外的任务:分配数据
注意:新增副本时主节点会自动协调,然后拷贝数据到新增的副本节点,副本数是可以随时调整的!
具体设置方式如下
PUT /my_temp_index/_settings
{ "number_of_replicas": 1 }
关于ES的灵活使用
我们先来介绍下面这样一个场景
SMS系统 业务场景是每天发送各家银行的登录短信等,一个数据表 每天产生的数据量是50G 查询场景是按时间段按银行(如过去三个月 民生银行)查询短信发送记录
那么如果是mysql的话 就算建立索引 效率也会很慢
在mysql中优化的话 需要拆表 将各个银行的短信拆分出来 再按照日期拆
但是这样会造成跨库和跨表
ES场景
思路和mysql基本一致 建立索引如下
bankName_date_index















 2625
2625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











