







 堆排序是一种基于完全二叉树的排序算法,分为大根堆和小根堆。通过创建最大堆,然后将堆顶元素与末尾元素交换并调整堆,重复该过程实现排序。堆排序不是稳定的排序算法,时间复杂度为O(nlgn)。
堆排序是一种基于完全二叉树的排序算法,分为大根堆和小根堆。通过创建最大堆,然后将堆顶元素与末尾元素交换并调整堆,重复该过程实现排序。堆排序不是稳定的排序算法,时间复杂度为O(nlgn)。
概述
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
什么是堆?
堆(二叉堆)可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示(普通的一般的二叉树通常用链表作为基本容器表示),每一个结点对应数组中的一个元素。
如下图,是一个堆和数组的相互关系
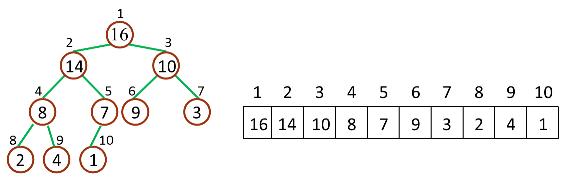
堆和数组的相互关系
堆和数组的相互关系
对于给定的某个结点的下标 i,可以很容易的计算出这个结点的父结点、孩子结点的下标:
Parent(i) = floor(i/2),i 的父节点下标
Left(i) = 2i,i 的左子节点下标
Right(i) = 2i + 1,i 的右子节点下标

二叉堆一般分为两种:最大堆和最小堆。
分类
大根堆和小根堆:根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小根堆,又称最小堆。根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大根堆,又称最大堆。注意:①堆中任一子树亦是堆。②以上讨论的堆实际上是二叉堆(Binary Heap),类似地可定义k叉堆。
高度
堆可以被看成是一棵树,结点在堆中的高度可以被定义为从本结点到叶子结点的最长简单下降路径上边的数目;定义堆的高度为树根的高度。我们将看到,堆结构上的一些基本操作的运行时间至多是与树的高度成正比,为O(lgn)。
堆排序原理
堆排序就是把最大堆堆顶的最大数取出,将剩余的堆继续调整为最大堆,再次将堆顶的最大数取出,这个过程持续到剩余数只有一个时结束。
在堆中定义以下几种操作:
最大堆调整(Max-Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
创建最大堆(Build-Max-Heap):将堆所有数据重新排序,使其成为最大堆
堆排序(Heap-Sort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
继续进行下面的讨论前,需要注意的一个问题是:数组都是 Zero-Based,这就意味着我们的堆数据结构模型要发生改变
相应的,几个计算公式也要作出相应调整:
Parent(i) = floor((i-1)/2),i 的父节点下标
Left(i) = 2i + 1,i 的左子节点下标
Right(i) = 2(i + 1),i 的右子节点下标
最大堆调整(MAX‐HEAPIFY)的作用是保持最大堆的性质,是创建最大堆的核心子程序,作用过程如图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









