







HiveHive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
- 每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
- Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds = 20090801, ctry = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
- Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020
- External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。与HBase比较hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储
区别:
hbase是物理表,Hive中的表纯逻辑;
hive元数据的三种存储方式
Hive 将元数据存储在 RDBMS 中,有三种模式可以连接到数据库,其中1、2均属于本地存储,3属于远端存储,对于使用外部数据库存储元数据的情况,我们在此将会以mysql举例说明。
1、Single User Mode:
默认安装hive,hive是使用derby内存数据库保存hive的元数据,这样是不可以并发调用hive的,这种模式时hive默认的存储模式, 使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,配置文件中的“hive.metastore.warehouse.dir”指出了仓库的存储位置(注意对于hive来说,数据是存储在hdfs上的,元数据存储在数据库),默认属性值为/user/hive/warehouse,假如利用hive CLI创建表records,则在hdfs上会看到如下目录:/user/hive/warehouse/records/ 此目录下存放数据。命令:load data local inpath ‘input/test.txt’ overwrite into table records; 这一命令会告诉hive把指定的本地文件放到它的仓库位置,此操作只是一个文件的移动操作,去掉local的load命令为把hdfs中的文件进行移动。。
2、Multi
User Mode:
通过网络连接到一个数据库中,是最经常使用到的模式。假设使用本机mysql服务器存储元数据。这种存储方式需要在本地运行一个mysql服务器,并作如下配置(需要将mysql的jar包拷贝到$HIVE_HOME/lib目录下)。
3、Remote Server Mode:
在服务器端启动一个 MetaStoreServer,客户端利用 Thrift 协议通过 MetaStoreServer 访问元数据库。 客户端重要配置是hive.metastore.urls,用于通过thrift连接metastore,默认 metastore端口是9083
这种方式要单独启动metastore,命令为hive –service metastore
创建一个表加载data.txt里的数据到test表里:data.txt数据形式:javascript0,name01,name12,name2
create table test(id int,name string) row format delimited fields terminated by ',';LOAD DATA LOCAL INPATH '/home/xmm/source/data.txt' OVERWRITE INTO TABLE test;在hive shell里执行sql语句,会启动一个Spark任务;(感觉是Hive on Spark)
Hive 将元数据存储在数据库中(metastore),目前只支持mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在HDFS 中,并在随后有 MapReduce 调用执行Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
Hive查询优化:
http://zh.hortonworks.com/blog/5-ways-make-hive-queries-run-faster/
这篇文章中提到Spark可以不通过hive直接操作hdfs; (还可以缓存)
https://hivevssparksql.wordpress.com/2015/10/13/hive-vs-sparksql/#comments
检查hive server2是否启动
netstat -anp |grep 10000
HDFS的体系架构
整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的(在最新的Hadoop2.2版本已经实现多个NameNode的配置-这也是一些大公司通过修改hadoop源代码实现的功能,在最新的版本中就已经实现了)。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
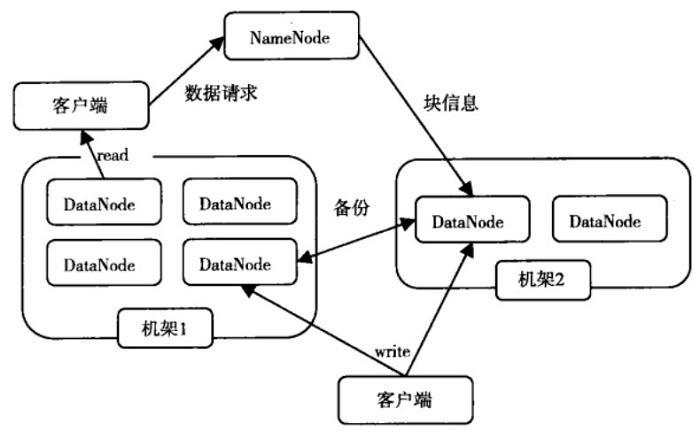
如图:HDFS体系结构图
图中涉及三个角色:NameNode、DataNode、Client。NameNode是管理者,DataNode是文件存储者、Client是需要获取分布式文件系统的应用程序。
文件写入:
1) Client向NameNode发起文件写入的请求。
2) NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode的信息。
3) Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。
文件读取:
1) Client向NameNode发起读取文件的请求。
2) NameNode返回文件存储的DataNode信息。
3) Client读取文件信息。
HDFS作为分布式文件系统在数据管理方面可借鉴点:
文件块的放置:一个Block会有三份备份,一份在NameNode指定的DateNode上,一份放在与指定的DataNode不在同一台机器的DataNode上,一根在于指定的DataNode在同一Rack上的DataNode上。备份的目的是为了数据安全,采用这种方式是为了考虑到同一Rack失败的情况,以及不同数据拷贝带来的性能的问题。
Hive中内部表与外部表的区别:
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,
不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,
而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
schema on read
需要注意的是传统数据库对表数据验证是 schema on write(写时模式),而 Hive 在load时是不检查数据是否
符合schema的,hive 遵循的是 schema on read(读时模式),只有在读的时候hive才检查、解析具体的
数据字段、schema。
读时模式的优势是load data 非常迅速,因为它不需要读取数据进行解析,仅仅进行文件的复制或者移动。
写时模式的优势是提升了查询性能,因为预先解析之后可以对列建立索引,并压缩,但这样也会花费要多的加载时间。
HIVE的分区通过在创建表时启用partitionby实现,用来partition的维度并不是实际数据的某一列,具体分区的标志是由插入内容时给定的。当要查询某一分区的内容时可以采用where语句,形似where tablename.partition_key >a来实现。
查看下数据文件fieldX
里面都只包含两列ts和line并不包含dt和country这两个分区列,但是从查询结果看分区列和非分区列并无差别,实际上分区列都是从数据仓库的分区目录名得来的。
查看sampling数据:
select * from student tablesample(bucket 1 out of 2 on id);
tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取 (64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例 如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据。
join 优化
对于map端连接的情况,两个表以相同方式划分桶。处理左边表内某个桶的 mapper知道右边表内相匹配的行在对应的桶内。因此,mapper只需要获取那个桶 (这只是右边表内存储数据的一小部分)即可进行连接。这一优化方法并不一定要求 两个表必须桶的个数相同,两个表的桶个数是倍数关系也可以。















 819
819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









