









前言
在之前的系列内, 多数都是介绍Hadoop MR的基本操作, 对于运行原理涉及较少. 本章, 主要补充下这部分的内容. 方便以后的理解.
本章主要分为如下几个部分:
- WordCount的分布式运算设计
- WordCount的执行过程
- Job的提交流程
- MR运行总过程
- Yarn的提交流程
正文
WordCount运行设计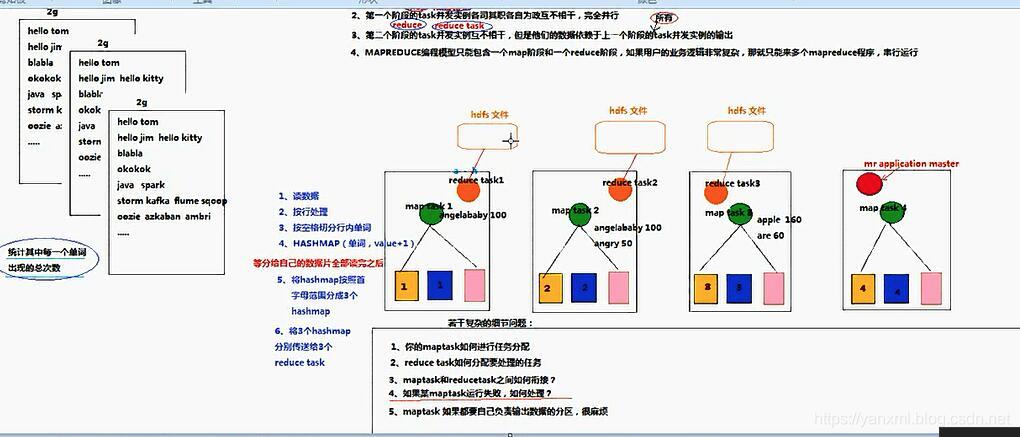
WordCount的Map/Reduce主要分为如下几个阶段:
Mapper主要负责任务的初级处理,Reducer主要负责数据的合并;Mapper端的操作为(读取数据/按行处理/每行按空格切分单词/数据存入HashMap/将HashMap按照范围切分/HashMap 数据传递给下游, 即Reducer端)Reducer端的操作为(累加操作/输出操作)NodeManager处理如下操作:MapTask分配 /ReduceTask分配 /MapTask与ReduceTask的串链(包括数据的切分) /MapTask&ReduceTask失败机制
Job提交过程(WordCount为例子)
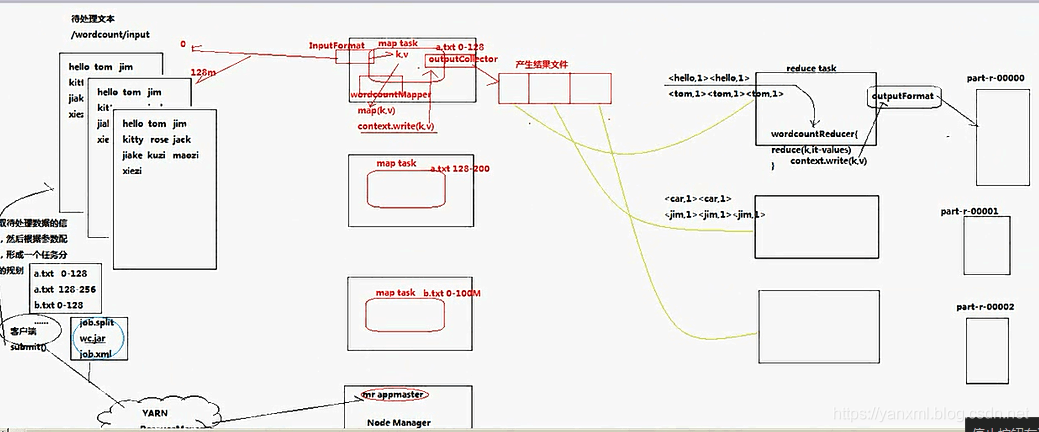
Job的提交流程如上所示:
- Client端首先根据数据, 对文件进行切分(切分后即知道需要几个
MapTask进行处理), 切分后提交给Yarn, 即ResourceManager. 提交给Yarn时, 主要包括job.split/a.jar/job.xml三个文件. Yarn首先会启动一个MR Process运行这个程序, 即运行Jar包.MR Process通过job.split等得知需要启动几个MapTask, 启动MapTask执行Map的操作.MapTask通过InputFormat去既定的资源中读取数据, 分别执行map()操作, 随后将自己处理后的数据放入context.(context.write(xx,xx);). 随后通过OutputCollect及ReduceTask的相关信息, 将处理过的数据传递给ReduceTask.ReduceTask得到数据后, 通过map()进行遍历处理. 处理结束后, 通过OutputFormat将数据存放在约定位置.
注意: 值得一提的是ReduceTask和MapTask在运行map()方法前都会通过setup()方法进行初始化操作. 运行map()方法后, 会通过cleanup()方法进行处理操作. 其中map()方法可能执行多次, 而初始化和结束方法都只执行一次.
InputFormat与数据切片
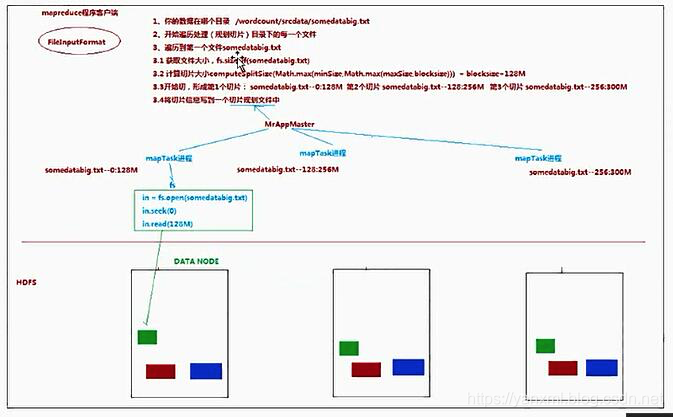
主要流程为:
- 读取文件所在目录,获取原文件大小.
- 通过
split()方法对其进行切片; - 将切片的规划放入文件内
job.xml等文件.
切片相关参数: Math.max(minSize,Math.min(maxSize,blockSize)).
minSize: 默认为1, 配置参数mapreduce.input.fileinputformat.split.minsize.maxSize: 默认值为Long.MAXVALUE, 配置参数mapreduce.input.fileinputformat.split.maxsize.blockSize
默认情况下,切片大小为BlockSize.maxsize, 如果设置比blockSize小会使得切片变小.minsize, 如果设置比BlockSize大, 则可以让切片变得比BlockSize大.
实例:
比如有两个文件: file1.txt 320M file2.txt 10M
切分后的结果为: file1.txt.split1 1-128M / file1.txt.split2 128-256 / file1.txt.split3 256-320 /file2.txt.split1 1-10M
主要影响: 结点硬件环境/运算类型:IO密集型/CPU密集型/运算任务的数据量,
Job的提交流程
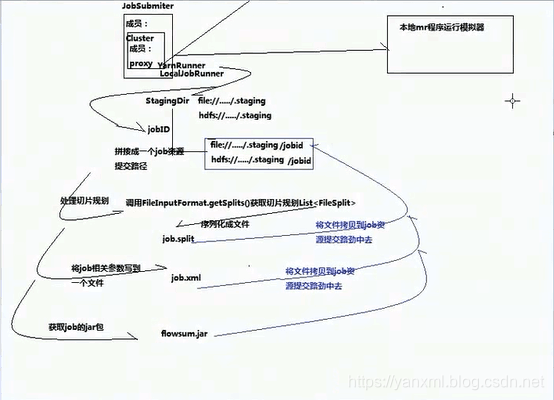
- Job通过
Job.getInstance(conf)获取Job对象实例. 随后通过submit()或waitForCompletion()提交给JobSubmiter. JobSumiter提交到Yarn的YarnRunner或本地的LocalUobRunner上.- 从
Yarn上获取提交资源的路径StagingDir与JobID. 并将其拼接成一个Job提交路径. - 通过
FileInputFormat.getSplits()方法获取任务切片规划. 并将其序列化成文件job.split拷贝到任务提交目录. - 将Job相关参数, 写入一个文件
job.xml, 拷贝到Job的提交路径中. - 获取Job的运行Jar包, 也提交到响应路径.(通过
job.setJar()方法处理.)
MR运行总流程
Mapper处理流程
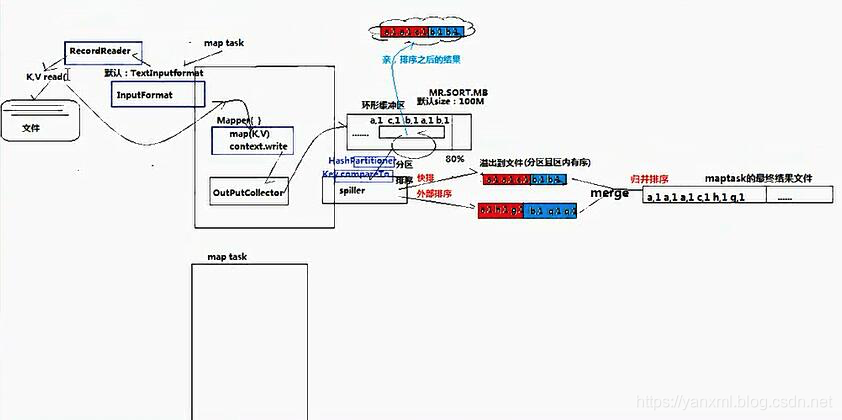
根据上图我们可以知道, Mapper主要经历如下流程:
Mapper通过InputFormat进行读取文件内容;Mapper在setup()完成后,按行依次进行map()方法,结束后完成cleanup()方法.- 其中, 后续的数据通过
context.write()写入OutPutCollector.
Shuffle处理流程
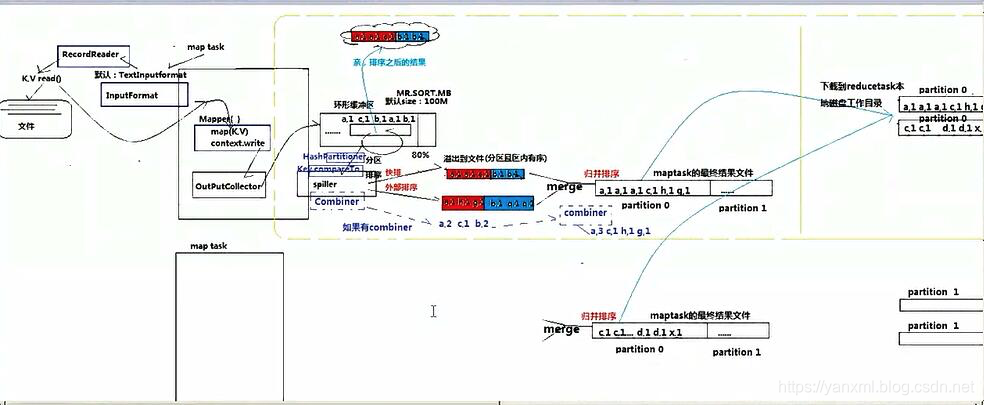
Shuffle流程通常指数据从Mapper端流出,到流入Reducer端的中间过程. 其过程如上图所示, 其主要流程包括:
-
OutputCollector将输出的数据写入环形缓冲区. (注:环形缓冲区有一个溢出阈值. 默认容量为100M, 溢出指数为0.8. 也就是超过80%就会溢出.) -
环形缓冲区内的溢出的数据根据Partiton算法进行分片. 于此同时, 默认根据<key,value>中的key进行排序. (我们可以使其继承CompareWritable值得排序规则.) 随后,将处理后的数据存储到文件内. -
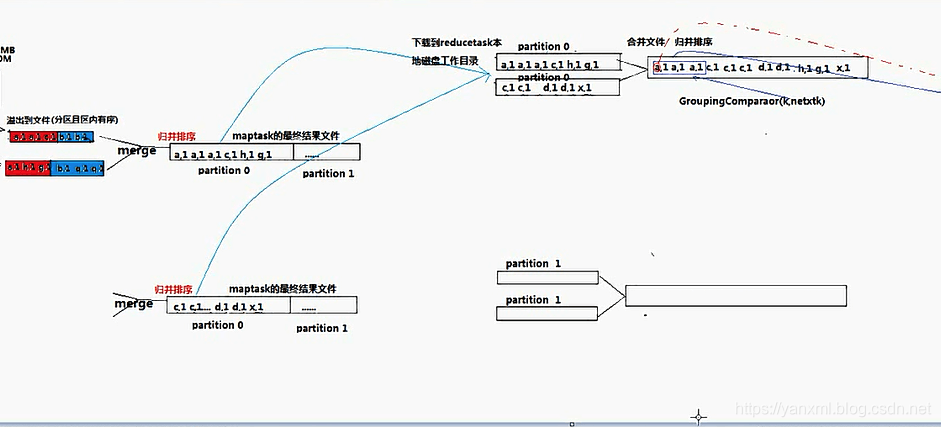
之后, 我们对于这些文件做归并排序. 使其合并并有序. 此时, 我们获取的为
Maptask的最终结果文件. -
之后, 我们将
MapTask的最终结果文件, 都在ReduceTask所在的主机上进行下载.(此时,也是一个归并排序). 随后即将进行ReduceTask的过程.
(在归并的时候, 可以通过GroupingComparator指定key是否相同, 即两个对象是否可以指定在一组.) (此外, 传输的数据是以<key,Iterator>的形式进行传输和处理的.) -
补充: 在
环形缓冲区写入磁盘文件, 或从磁盘文件下载归并到ReduceTask结点的过程中. 可以使用Combiner进行优化处理过程. 但是,Combiner不能改变原有的业务逻辑. (举例:<1/2=0><1/2=0> -> <2/2=1>这样的合并流程改变了业务逻辑).Combiner具体执行几次, 何时执行, 由系统自己决定.
Reducer处理流程
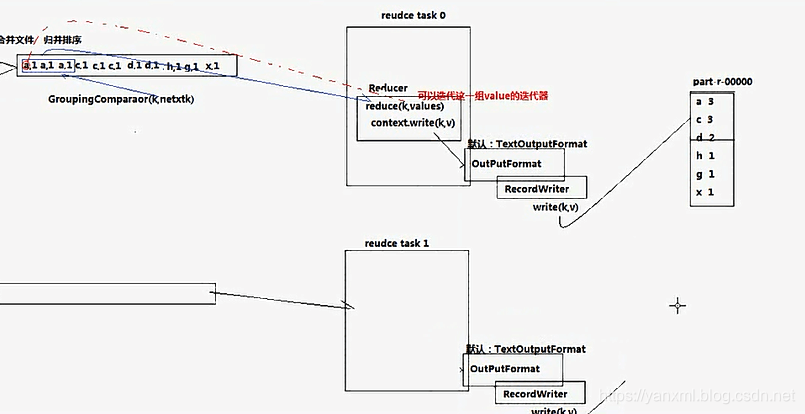
在ReducerTask端, 我们通过下载Shuffle完成后的结果, 进行Reduce的相关逻辑.
主要流程如下:
- 下载数据, 并做归并操作. (因为其中
MapTask处理好的数据可能分部在不同的机器上, 所以需要进行下载操作. 此是耗费资源的操作. 后期的Spark改良了这个过程.) 此外,同样主要数据以<key,Iterator>进行处理. - 与
ReduceTask一样,先后运行setup()->map()->cleanup()三个方法. - 最终, 将其数据输出至
OutputFormat中,OutputFormat通过调用RecordWriter将结果写到相应的位置.
小文件处理
MapTask & ReduceTask个数的指定
通过上述的流程, 我们可以发现. MapTask的数目由你的文件切片规则(默认128M一片), 文件大小决定. 而ReduceTask的个数由Partiton的数据逻辑切片规则决定.
当然, 我们指定job.setReduceTaskNum()的数目要多余数据的逻辑切片数目.(最好是等于.)
Yarn的资源调度过程
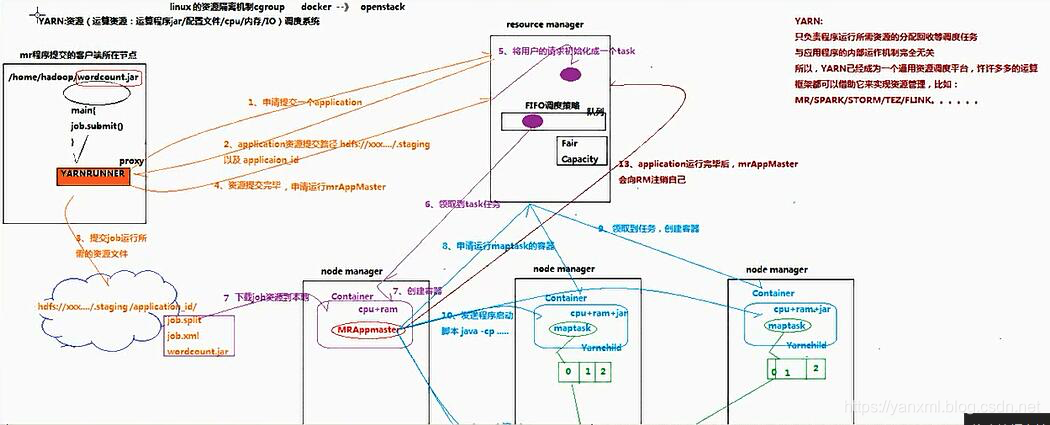
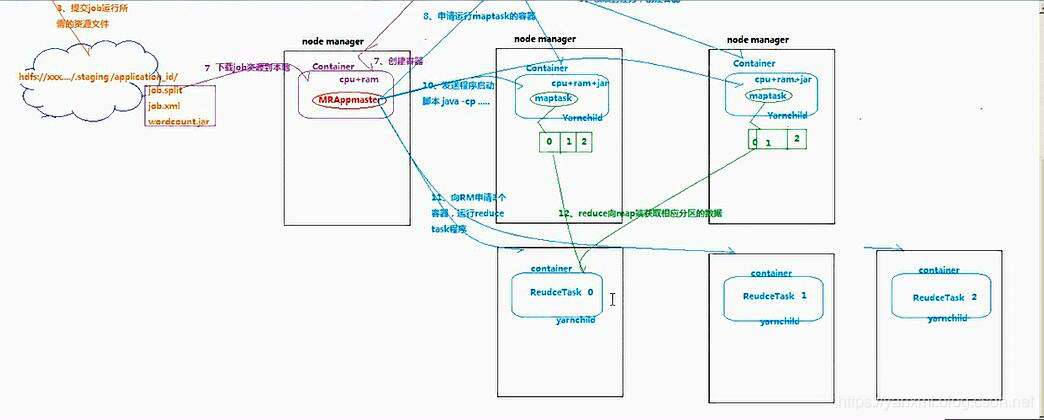
任务提交到Yarn的流程主要如下所示:
- 1- 任务通过
Job.submit()方法将其提交到YarnRunner上, 并向Yarn所在的Resource Manager发出提交任务Job的申请. - 2-
Yarn返回提交的资源路径, 以及ApplicationID. - 3-
Job通过资源逻辑与ApplicationID整合自身, 对于文件进行切片. 并将切片结果放入等待提交的文件内(a.jar/Job.split/Job.xml). - 4- 将Job切片相关文件提交至
Yarn上, 请求申请MRApplicationMaster. - 5-
Yarn将用户的请求合并为一个Task,并将其放入Task执行队列中(FIFO). - 6-
NodeManager接取任务. - 7-
NodeManager运行Task, 申请运行容器, 并下载需要的计算的资源. - 8-
NodeManager的MRApplicationMaster结点向Yarn申请资源, 即运行MapTask的结点. - 9-
NodeManager的MRApplicationMaster结点获取到资源, 创建MapTask容器. - 10- 在申请到资源的结点上运行
java -cp. 执行MapTask. - 11-
MapTask完成后, 又向Yarn申请ReduceTask所需要的资源, 创建容器. - 12-
ReduceTask容器结点, 获取MapTask的结点作为输入源. 随后进行任务计算. 之后通过OutputFormat进行输出.
注:Yarn在本架构内只充当资源调度的作用. 其上层结构还可以转变成其他的资源调度. 比如Mesos/K8s.
Hadoop1.x 架构
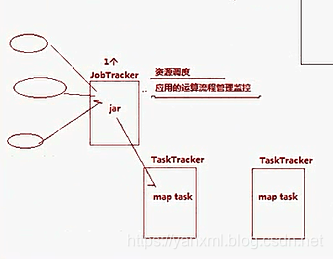
在Hadoop 1.x中, 使用JobTracker与TaskTracker进行调度. 但是从上结构可以发现, 使用的是一个JobTracker. 当运行多个Job的时候, 肯定会导致负载不均衡的问题.
OK, 关于这部分的内容. 我们就先介绍到这边. 图的话有时间自己画一遍, 自己跟一遍源码.














 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









