







一 双向链表的基本概念
单链表的结点中,只有一个指针域,用来指示后继结点。由此,从某个结点出发只能顺时针向后寻找其他结点。若要寻找结点的前驱结点,则必须从表头指针出发。换言之,在单链表中,查找直接后继结点的执行时间为 O(1),而查找直接前驱的执行时间为 O(n)。为克服单链表这种单向性的缺点,可利用 双向链表 (Double Linked List)。
1.1 双向链表的结点(DuLNode)
结点 = 前驱指针域 + 数据域 + 后继指针域
- 前驱指针域:用来指向结点的直接前驱;
- 数据域:用来存放数据元素本身的信息;
- 后继指针域:用来指向结点的直接后继。
1.2 双向链表的数据结构定义
//双向链表元素类型定义
typedef int ElemType;
//双向链表的结点数据结构描述
typedef struct DuLNode {
ElemType data; //数据域
struct DuLNode *prior; //直接前驱
struct DuLNode *next; //直接后继
} DuLNode, *DuLinkList;和单链表的循环链表类似,双向链表也可以有循环表,称为双向循环链表,一般简称为双向链表。如图 2.19(c) 所示,链表中存在有两个环,图 2.19(b) 所示为只有一个头结点的空表。

二 双向链表的基本操作
2.0 Status模块
Status.h 模块:预定义了一些常量及类型,以增强C语言的描述功能。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
//状态码
#define TRUE 1 // 真/是
#define FALSE 0 // 假/否
#define OK 1 // 通过/成功
#define ERROR 0 // 错误/失败
//系统中已有此状态码定义,要防止冲突
#ifndef OVERFLOW
#define OVERFLOW -2 //堆栈上溢
#endif
//系统中已有此状态码定义,要防止冲突
#ifndef NULL
#define NULL ((void*)0)
#endif
//状态码类型
typedef int Status;
//布尔类型
typedef int Boolean;2.1 初始化一个空的双向链表
【算法描述】C语言实现
//初始化一个空的双向链表
Status InitList_DuL(DuLinkList *L)
{
*L = (DuLNode*)malloc(sizeof(DuLNode));
if(*L == NULL)
exit(OVERFLOW);
//头结点的前驱和后继均指向自身
(*L)->prior = (*L)->next = *L;
return OK;
}<Tips> 要想把在某个函数内动态申请的内存空间带出函数外,需要使用一个二级指针作为函数的形参,如代码中的指针 L,就是一个二级指针变量。
2.2 置空一个双向链表
所谓“置空”双向链表,即释放双向循环链表中所有非头结点的存储空间。
【算法描述】C语言实现
//置空一个双向链表
//所谓“置空”双向链表,即释放双向循环链表中所有非头结点的存储空间。
Status ClearList_DuL(DuLinkList L)
{
DuLinkList p,q;
if(L == NULL)
return ERROR;
p = L->next; //指针p为双向链表的工作指针,初始指向元结点
while(p != L) //当P的后继结点不为头结点时
{
q = p->next; //将p的后继结点地址临时存放在指针q中
free(p); //释放p当前指向的结点
p = q; //p指向下一个结点
}
L->prior = L->next = L;
return OK;
}2.3 销毁一个双向链表
所谓“销毁”双向链表,即释放双向循环链表所有结点的存储空间,包括头结点。
【算法描述】C语言实现
//销毁一个双向链表
//所谓“销毁”双向链表,即释放双向循环链表所有结点的存储空间,包括头结点。
Status DestroyList_DuL(DuLinkList L)
{
if(L == NULL)
return ERROR;
ClearList_DuL(L); //首先置空双向链表
free(L); //然后释放头结点的存储空间
return OK;
}2.4 判断一个双向链表是否为空
判空操作,就是判断双向链表中是否包含有数据结点。
【算法描述】C语言实现
//判断一个双向链表是否为空
//判空操作,就是判断双向链表中是否包含有数据结点
Status ListIsEmpty_DuL(DuLinkList L)
{
if(L != NULL && L->prior==L && L->next==L)
return TRUE;
else
return FALSE;
}2.5 计算一个双向链表的数据结点个数
【算法描述】C语言实现
//计算一个双向链表的数据结点个数
int ListLength_DuL(DuLinkList L)
{
DuLinkList p;
int count = 0;
if(!ListIsEmpty_DuL(L))
return 0;
p = p->next; //指针p为链表的工作指针,初始指向元结点
while(p != L) //遍历双向链表
{
count++;
p = p->next;
}
return count;
}2.6 获取一个双向链表第 i 个结点元素的值
获取双向链表中第 i 个元素,并将其存放在参数 e 中。
【算法描述】C语言实现
/*
* 获取双向循环链表中第i个元素,将其存储到e中。
* 如果可以找到,返回OK,否则,返回ERROR。
*【备注】
* 教材中i的含义是元素位置,从1开始计数,但这不符合编码的通用约定。
* 通常,i的含义应该指索引,即从0开始计数;则第i个元素对应的下标为(i-1)
*/
Status GetElem_DuL(DuLinkList L, int i, ElemType *e)
{
DuLinkList p;
int j;
//如果双向链表为空,或者i的值不合规(如i<=0),则返回ERROR
if(!ListIsEmpty_DuL(L) || i<=0)
return FALSE;
p = L; //指针p为双向链表的工作指针,初始指向头结点
j = 0; //从第1个数据结点开始,对应下标为0
//查找第i个结点的位置,且该结点不能为表头结点
while(p->next!=L && j<i)
{
p = p->next; //p指向下一个结点
j++; //计时器j相应加1
}
//如果遍历到头了,说明没有找到合乎目标的结点
if(p==L || j>i)
return ERROR;
*e = p->next->data; //取第i个结点的数据域
return OK;
}2.7 返回一个双向链表元素值为 e 的结点位置
返回双向循环链表中首个与 e 相等的元素的位置,用整型变量 i 表示;如果没有找到,返回 0。
【算法描述】C语言实现
/*
* 返回一个双向链表元素值为 e 的结点位置
* 返回双向循环链表中首个与 e 相等的元素的位置,用整型变量 i 表示;如果没有找到,返回 0。
*/
int LocateElem_DuL(DuLinkList L, ElemType e)
{
int i;
DuLinkList p;
//如果双向链表为空,则返回0
if(!ListIsEmpty_DuL(L) || i<=0)
return 0;
i = 1; //i的初始值为第1个元素的位序
p = p->next; //工作指针p初始指向链表的第1个元素
while(p!=L && p->data != e)
{
i++;
p = p->next;
}
if(p != L)
return i;
else
return 0;
}2.8 双向链表的插入操作
向双向链表第 i 个位置之前插入元素 e,插入成功则返回OK,否则返回ERROR。
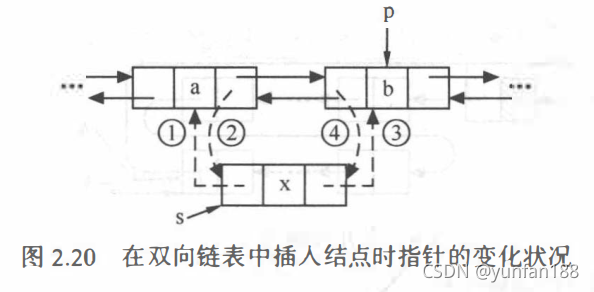
【算法思路】双向链表的插入操作,与单链表不同的是,它需要同时修改两个方向上的指针,如下图 2.20 显示了插入结点时指针修改的情况。在插入结点时,需要修改四个指针。时间复杂度为 O(n)。
【算法描述】C语言实现
/*
* 获取双向链表L上第i个结点的位置指针
*/
static DuLinkList GetElemP_DuL(DuLinkList L, int i)
{
DuLinkList p;
int count;
//如果双向链表为空或者i的值不合规(如i<=0)
if(!ListIsEmpty_DuL(L) || i<=0)
return NULL;
p = L;
count = 0;
//尝试查找第i个结点元素的位置
while(p->next!=L && count<i)
{
p = p->next;
count++;
}
//恰好找到第i个结点元素,则返回元素的位置指针;否则返回NULL
if(count == i)
return p;
else
return NULL;
}
/*
* 双向链表的插入操作
* 向双向链表第 i 个位置之前插入元素 e,插入成功则返回OK,否则返回ERROR
*/
Status ListInsert_DuL(DuLinkList L, int i, ElemType e)
{
DuLinkList p, s;
if(!ListIsEmpty_DuL(L))
return ERROR;
if(!(p=GetElemP_DuL(L, i))) //在L中确定第i个元素的位置指针p
return ERROR; //p为NULL时,第i个元素不存在
s = (DuLNode*)malloc(sizeof(DuLNode)); //生成新结点s
s->data = e; //将e赋值给新结点s的指针域
//下面四条语句是将新结点s插入到L中的操作
s->prior = p->prior; //对应图 2.20的(1)
p->prior->next = s; //对应图 2.20的(2)
p->next->next = p; //对应图 2.20的(3)
p->prior = s; //对应图 2.20的(4)
return OK;
}2.9 双向链表的删除操作
删除带头结点的双向链表 L 中第 i 个元素。
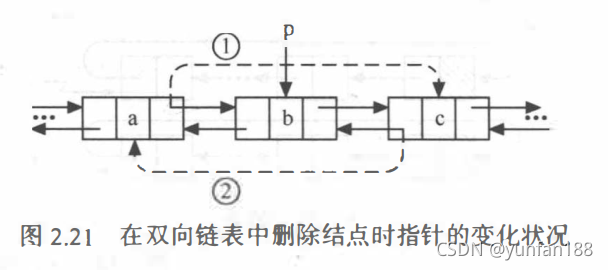
【算法思路】双向链表的删除操作,与单链表不同的是,它需要同时修改两个方向上的指针,如下图 2.21 显示了删除结点时指针修改的情况。在删除结点时,需要修改两个指针。时间复杂度为 O(n)。
【算法描述】C语言实现
/*
* 双向链表的删除操作
* 删除带头结点的双向链表 L 中第 i 个元素
*/
Status ListDelete_DuL(DuLinkList L, int i)
{
DuLinkList p;
if(!ListIsEmpty_DuL(L))
return ERROR;
if(!(p=GetElemP_DuL(L, i))) //在L中确定第i个元素的位置指针p
return ERROR; //p为NULL时,第i个元素不存在
p->prior->next = p->next; //修改被删除结点的前驱结点的后继指针,对应图2.21(1)
p->next->prior = p->prior; //修改被删除结点的后继结点的前驱指针,对应图2.21(2)
free(p);
return OK;
}2.10 遍历一个双向链表,并输出结点数据域的值
【算法描述】C语言实现
/*
* 遍历一个双向链表,并输出每个数据结点的值
*/
void ListTraverse_DuL(DuLinkList L)
{
DuLinkList p;
//确保双向链表存在且非空
if(!ListIsEmpty_DuL(L))
return;
p = L->next; //指针p为双向链表的工作指针,初始指向元结点
while(p != L)
{
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}参考
《数据结构(C语言版)》严蔚敏,吴伟民 (编著)
《数据结构(C语言版-第2版)》严蔚敏 , 李冬梅 , 吴伟民 (编著)














 1337
1337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









