






目标检测 (Object detection) 是一种计算机视觉技术,旨在检测汽车、建筑物和人类等目标。这些目标通常可以通过图像或视频来识别。
目标检测在视频监控、自动驾驶汽车、人体跟踪等领域得到了广泛的应用。在本文中,我们将了解目标检测的基础知识,并回顾一些最常用的算法和一些全新的方法。
转载来源
公众号:磐创AI来源:Medium “阅读本文大概需要 11 分钟。
目标检测的原理
目标检测定位图像中目标的存在,并在该目标周围绘制一个边界框 (bounding box)。这通常包括两个过程:预测目标的类型,然后在该目标周围绘制一个框。现在让我们来回顾一些用于目标检测的常见模型架构:
R-CNN
Fast R-CNN
Faster R-CNN
Mask R-CNN
SSD (Single Shot MultiBox Defender)
YOLO (You Only Look Once)
Objects as Points
Data Augmentation Strategies for Object Detection
R-CNN 模型
该技术结合了两种主要方法:使用一个高容量的卷积神经网络将候选区域 (region-proposals) 自底向上的传播,用来定位和分割目标;如果有标签的训练数据比较少,可以使用训练好的参数作为辅助,进行微调 (fine tuning),能够得到非常好的识别效果提升。
论文链接: https://arxiv.org/abs/1311.2524?source=post_page---------------------------
进行特定领域的微调,从而获得高性能的提升。由于将候选区域 (region-proposals) 与卷积神经网络相结合,论文的作者将该算法命名为 R-CNN(Regions with CNN features)。
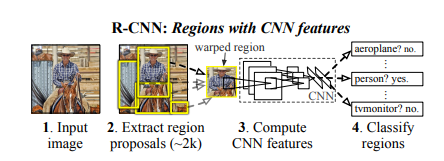
该模型在对每张图片提取了约 2000 个自底向上的候选区域。然后,它使用一个大型 CNN 计算每个区域的特征。然后,利用专门针对类别数据的线性支持向量机 (SVMs) 对每个区域进行分类。该模型在 PASCAL VOC 2010 上的平均精度达到 53.7%。
该模型中的目标检测系统由三个模块组成。第一个负责生成类别无关的候选区域,这些区域定义了一个候选检测区域的集合。第二个模块是一个大型卷积神经网络,负责从每个区域提取固定长度的特征向量。第三个模块由一个指定类别的支持向量机组成。

该模型采用选择性搜索 (selective search) 方法来生成区域类别,根据颜色、纹理、形状和大小选择搜索对相似的区域进行分组。在特征提取方面,该模型使用 CNN 的一个 Caffe 实现版本对每个候选区域抽取一个 4096 维度的特征向量。将 227×227 RGB 图像通过 5 个卷积层和 2 个完全连接层进行前向传播,计算特征。论文中所解释的模型与之前在 PASCAL VOC 2012 的结果相比,取得了 30% 的相对改进。
而 R-CNN 的一些缺点是:
训练需要多阶段: 先用 ConvNet 进行微调,再用 SVM 进行分类,最后通过 regression 对 bounding box 进行微调。
训练空间和时间成本大: 因为像 VGG16 这样的深度网络占用了大量的空间。
目标检测慢: 因为其需要对每个目标候选进行前向计算。
Fast R-CNN
下面的论文中提出了一种名为 Fast Region-based Convolutional Network(Fast R-CNN) 目标检测方法。
https://arxiv.org/abs/1504.08083?source=post_page---------------------------
它是用 Python 和 C++ 使用 Caffe 实现的。该模型在 PASCAL VOC 2012 上的平均精度为 66%,而 R-CNN 的平均精度为 62%。
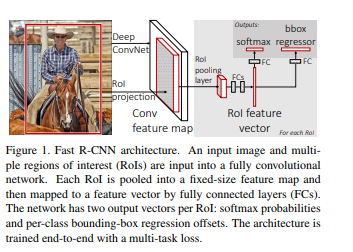
与 R-CNN 相比,Fast R-CNN 具有更高的平均精度、单阶段训练,训练更新所有网络层并且特征缓存不需要磁盘存储。
在其架构中, Fast R-CNN 接收图像以及一组目标候选作为输入。然后通过卷积层和池化层对图像进行处理,生成卷积特征映射。然后,通过针对每个推荐区域,ROI 池化层从每个特征映射中提取固定大小的特征向量。
然后将特征向量提供给完全连接层。然后这些分支成两个输出层。其中一个为多个目标类生成 softmax 概率估计,而另一个为每个目标类生成 4 个实数值。这 4 个数字表示每个目标的边界框的位置。
Faster R-CNN
论文链接: https://arxiv.org/abs/1506.01497?source=post_page---------------------------
论文提出了一种针对候选区域任务进行微调和针对目标检测进行微调的训练机制。
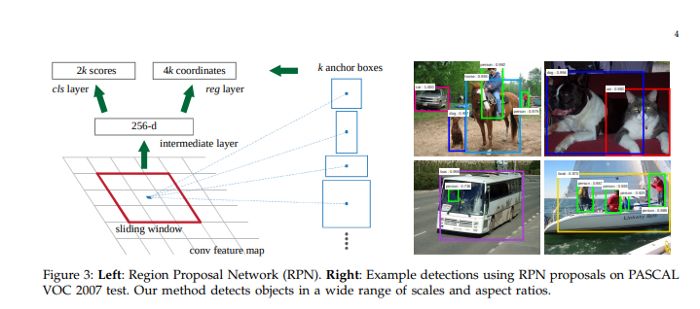
Faster R-CNN 模型由两个模块组成:负责提出区域的深度卷积网络和使用这些区域的 Fast R-CNN 探测器。候选区域网络 (Region Proposal Network) 以图像为输入,生成矩形目标候选的输出。每个矩形都有一个 objectness score。
Mask R-CNN
论文链接: https://arxiv.org/abs/1703.06870?source=post_page---------------------------
论文提出的模型是上述 Faster R-CNN 架构的扩展。它还可以用于人体姿态估计。
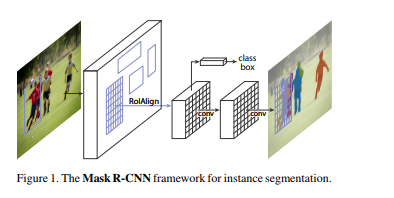
在该模型中,使用边界框和对每个像素点进行分类的语义分割对目标进行分类和定位。该模型通过在每个感兴趣区域 (ROI) 添加分割掩码 (segmentation mask) 的预测,扩展了 Faster R-CNNR-CNN。Mask R-CNN 产生两个输出:类标签和边界框。
SSD: Single Shot MultiBox Detector
论文链接: https://arxiv.org/abs/1512.02325?source=post_page---------------------------
论文提出了一种利用单个深度神经网络对图像中目标进行预测的模型。该网络使用应用于特征映射的小卷积滤波器为每个目标类别生成分数。
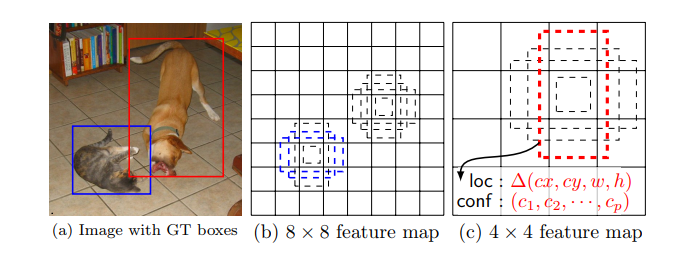
这种方法使用了一个前馈卷积神经网络,针对那些方框里的目标类别实例,产生一个固定大小的边界框的集合和分数。增加了卷积特征层,允许多比例特征映射检测。在这个模型中,每个特征映射单元 (feature map cell) 都链接到一组默认的边界框 (default box)。下图显示了 SSD512 在动物、车辆和家具上的性能。
You Only Look Once (YOLO)
论文提出了一种基于神经网络的图像边界框和类概率预测方法。
论文链接: https://arxiv.org/abs/1506.02640?source=post_page---------------------------
YOLO 模型每秒实时处理 45 帧。YOLO 将图像检测看作是一个回归问题,使得它的管道非常简单。因为这个简单的管道,它非常快。
它可以实时处理流视频,延迟小于 25 秒。在训练过程中,YOLO 可以看到整个图像,因此能够在目标检测中包含上下文。
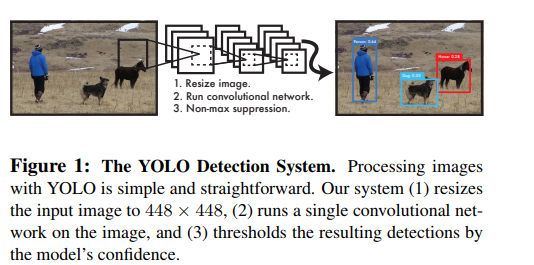
在 YOLO 中,每个边界框都由整个图像的特征来预测。每个边界框有 5 个预测: x, y, w, h 和置信度。(x, y) 表示边界框的中心相对于网格单元格的边界。w 和 h 是整个图像的预测宽度和高度。
该模型作为卷积神经网络实现,并在 PASCAL VOC 检测数据集上进行了评价。网络的卷积层负责提取特征,全连接层负责预测坐标和输出概率。
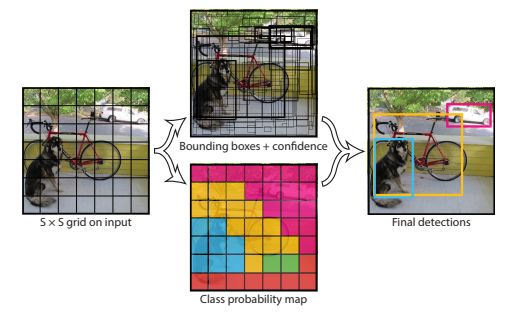
该模型的网络架构受到了用于图像分类的 GoogLeNet 模型的启发。该网络有 24 个卷积层和 2 个全连接层。该模型的主要挑战在于,它只能预测一个类,而且在鸟类等小目标上表现不佳。

该模型的平均精度达到 52.7%,但有可能达到 63.4%。
Objects as Points
论文提出将目标建模为单个点。它使用关键点估计来找到中心点,并回归到其他目标属性。
论文链接: https://arxiv.org/abs/1904.07850v2?source=post_page---------------------------
这些属性包括 3D 位置、姿态和尺寸。它使用了 CenterNet,这是一种基于中心点的方法,比其他边界框探测器更快、更准确。

目标大小和姿态等属性是由图像中心位置的特征回归得到的。该模型将图像输入卷积神经网络,生成热力图。这些热力图中的峰值表示图像中目标的中心。为了估计人体姿态,该模型检测关节点(2D joint)位置,并在中心点位置对其进行回归。
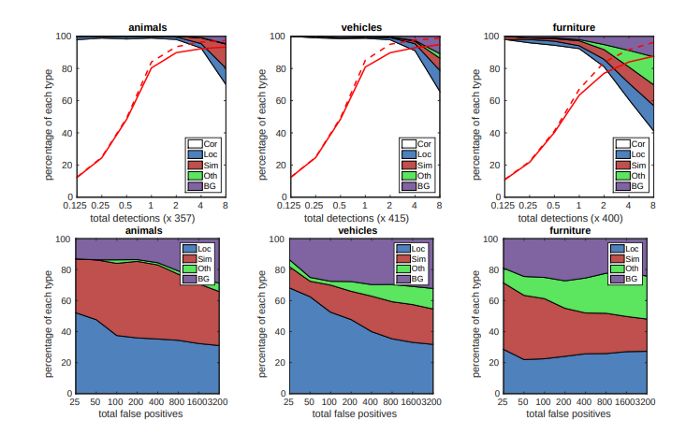
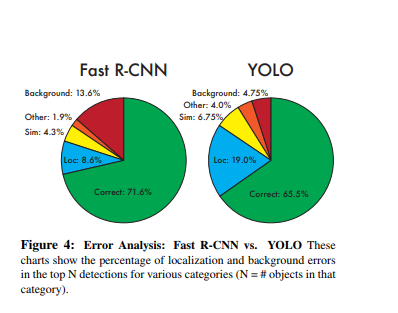
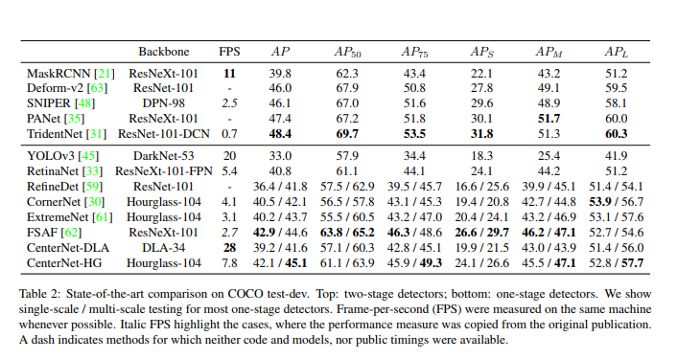
在 COCO 上,该模型以每秒 1.4 帧的速度实现了 45.1% 的平均精度。下图显示了与其他研究论文的结果进行比较的结果。
Learning Data Augmentation Strategies for Object Detection
数据增广包括通过旋转和调整大小等操作原始图像来创建新图像数据的过程。
论文链接: https://arxiv.org/abs/1906.11172v1?source=post_page---------------------------
虽然这本身不是一个模型结构,但论文提出了可以应用于可以转移到其他目标检测数据集的目标检测数据集的变换的创建。转换通常在训练时应用。
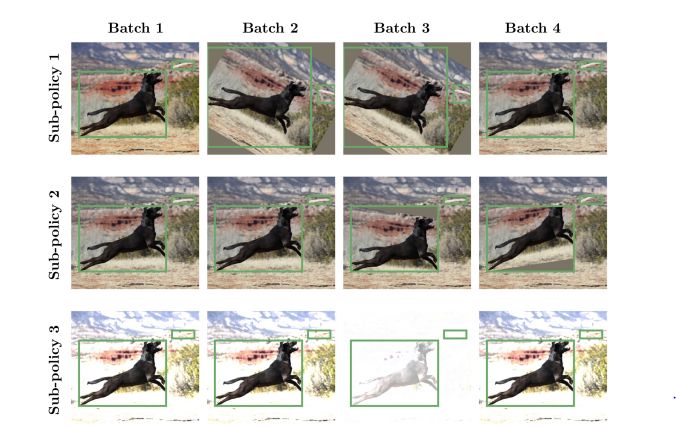
该模型将增广策略定义为训练过程中随机选择的 n 个策略集合。该模型中应用的一些操作包括颜色变化、图像几何变化以及只变化 bounding box annotations 的像素内容。
在 COCO 数据集上的实验表明,优化数据增广策略可以使检测精度提高到 +2.3 以上的平均精度。这使得单个推理模型的平均精度达到 50.7。
总结
现在,我们应该对在各种上下文中进行目标检测的一些最常见的技术(以及一些最新的技术)有所了解。
上面的论文/摘要也包含它们的代码实现的链接。希望能看到你在测试这些模型后得到的结果。
推荐阅读
1
2
跟繁琐的模型说拜拜!深度学习脚手架 ModelZoo 来袭!
3
4
妈妈再也不用担心爬虫被封号了!手把手教你搭建Cookies池
崔庆才
静觅博客博主,《Python3网络爬虫开发实战》作者
隐形字
个人公众号:进击的Coder



长按识别二维码关注














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









