




1.hive-site.xml 的 Hive 服务高级配置代码段(安全阀)中添加2个参数:
hive.security.authorization.sqlstd.confwhitelist=hive.exec.pre.hooks
hive.exec.pre.hooks=org.apache.hadoop.hive.ql.hooks.UpdateInputAccessTimeHook$PreExec
2.重启hive即可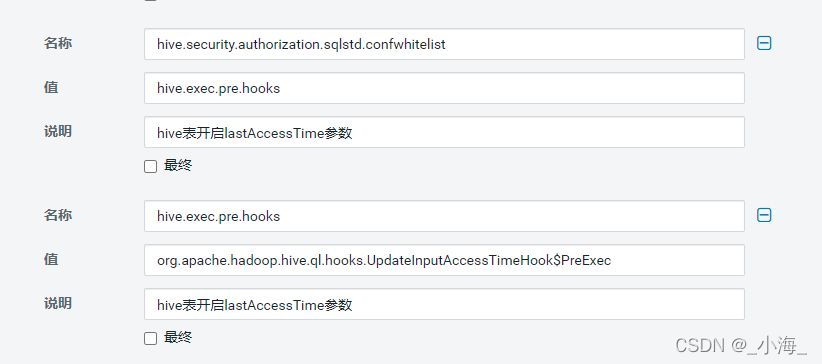
 本文介绍了如何在Hive服务的高级配置中添加安全阀参数,通过设置`hive.security.authorization.sqlstd.confwhitelist`和`hive.exec.pre.hooks`,启用`UpdateInputAccessTimeHook$PreExec`预执行钩子,以增强Hive的安全性和功能。重启Hive服务后,这些更改将生效。
本文介绍了如何在Hive服务的高级配置中添加安全阀参数,通过设置`hive.security.authorization.sqlstd.confwhitelist`和`hive.exec.pre.hooks`,启用`UpdateInputAccessTimeHook$PreExec`预执行钩子,以增强Hive的安全性和功能。重启Hive服务后,这些更改将生效。
1.hive-site.xml 的 Hive 服务高级配置代码段(安全阀)中添加2个参数:
hive.security.authorization.sqlstd.confwhitelist=hive.exec.pre.hooks
hive.exec.pre.hooks=org.apache.hadoop.hive.ql.hooks.UpdateInputAccessTimeHook$PreExec
2.重启hive即可
 315
8784
315
8784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























