






 本文介绍了如何使用pyspark的SparkSQL和DataFrame解决社交网络中寻找用户间接好友的问题。首先通过SQL查询找出非直接联系的配对,然后通过DataFrame操作剔除直接好友并去重,最后展示了一个实际操作步骤和测试结果。
本文介绍了如何使用pyspark的SparkSQL和DataFrame解决社交网络中寻找用户间接好友的问题。首先通过SQL查询找出非直接联系的配对,然后通过DataFrame操作剔除直接好友并去重,最后展示了一个实际操作步骤和测试结果。
一.问题描述
有这么一个类通讯录的数据集如下截图:
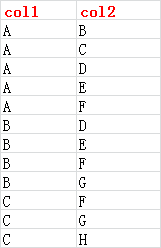
我们想进行好友,例如B和C同是A的好友,但是C不时B的好友,此时我们可以向B推荐一个间接好友C。
希望的输出:
tmp2.id2_1 id2_new
B C
C B,D,E
这个场景只是一个简单的数据场景,真实的场景会比这个复杂很多。
二. 解决方案
首先我们不要把问题想得复杂了,将问题一步一步拆解开:
第一步:
如何定义间接好友?
如下图,B,C,D,E,F同是A的好友,那么 B可以通过A获得间接好友 C,D,E,F,其它的以此类推。
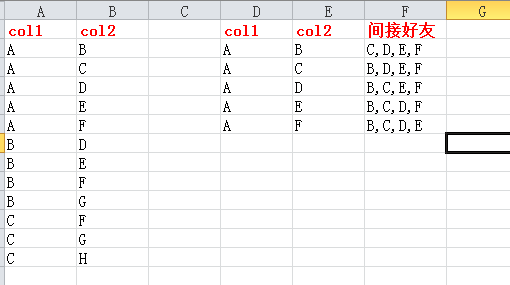
需要注意本例较为简单,真实情况较为复杂,B除了通过A可以获得间接好友,还可以通过其它的用户获得间接好友,然后需要进行去重,才能获得B初步的间接好友名单。
第二步:
剔除B的直接好友,获取到的最终的间接好友名单,然后才可以进行推荐。
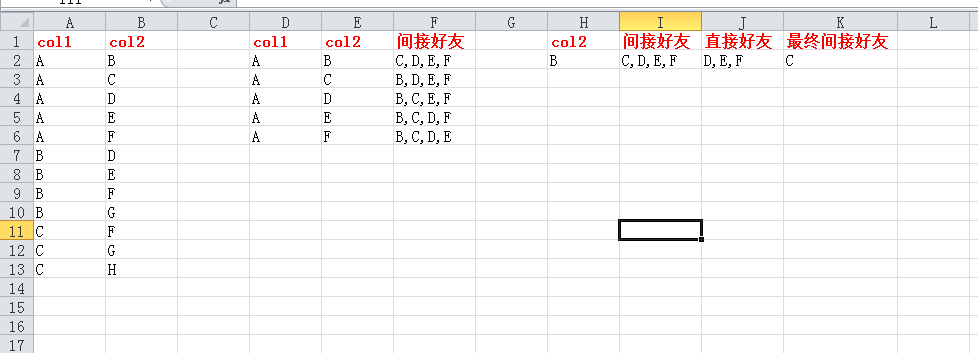
2.1 pyspark 的 Spark SQL的解决方案
将数据录入到Hive
create table test1(id1 string,id2 string);
insert into test1 values ('A','B');
insert into test1 values ('A','C');
insert into test1 values ('A','D');
insert into test1 values ('A','E');
insert into test1 values ('A','F');
insert into test1 values ('B','D');
insert into test1 values ('B','E');
insert into test1 values ('B','F');
insert into test1 values ('B','G');
insert into test1 values ('C','F');
insert into test1 values ('C','G');
insert into test1 values ('C','H');
代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
# 创建一个连接
spark = SparkSession. \
Builder(). \
appName('sql'). \
master('local'). \
getOrCreate()
sc = spark.sparkContext
sql1 = " create table tmp1 as " \
" select distinct t1.id2 as id2_1, " \
" t2.id2 as id2_2 " \
" from test1 t1 " \
" inner join test1 t2 " \
" on t1.id1 = t2.id1 " \
" where t1.id2 != t2.id2 "
sql2 = "create table tmp2 as " \
" SELECT id2_1, id2_2 " \
" from tmp1 " \
" left join test1 " \
" on tmp1.id2_1 = test1.id1 " \
" and tmp1.id2_2 = test1.id2 " \
" where test1.id1 is null"
sql3 = "create table tmp3 as " \
"SELECT tmp2.id2_1, " \
"concat_ws(',', collect_set(id2_2) ) as id2_new " \
"from tmp2 " \
"inner join test1 " \
"on tmp2.id2_1 = test1.id1 " \
"group by tmp2.id2_1"
# 运行sql语句
df1 = spark.sql(sql1)
df2 = spark.sql(sql2)
df3 = spark.sql(sql3)
# 关闭spark回话
spark.stop()
测试记录:
hive>
>
>
> select * from tmp1;
OK
tmp1.id2_1 tmp1.id2_2
G E
E B
H F
B C
D C
D E
G F
F C
B F
F H
C F
G D
D G
E F
C B
D F
E C
F B
E D
C D
H G
D B
F E
F G
G H
F D
E G
C E
B D
B E
Time taken: 0.065 seconds, Fetched: 30 row(s)
hive> select * from tmp2;
OK
tmp2.id2_1 tmp2.id2_2
G E
E B
H F
B C
D C
D E
G F
F C
F H
G D
D G
E F
C B
D F
E C
F B
E D
C D
H G
D B
F E
F G
G H
F D
E G
C E
Time taken: 0.065 seconds, Fetched: 26 row(s)
hive>
> select * from tmp3;
OK
tmp3.id2_1 tmp3.id2_new
B C
C E,B,D
Time taken: 0.059 seconds, Fetched: 2 row(s)
hive>
2.2 pyspark的DataFrame的解决方案
将数据录入到Hive
create table test1(id1 string,id2 string);
insert into test1 values ('A','B');
insert into test1 values ('A','C');
insert into test1 values ('A','D');
insert into test1 values ('A','E');
insert into test1 values ('A','F');
insert into test1 values ('B','D');
insert into test1 values ('B','E');
insert into test1 values ('B','F');
insert into test1 values ('B','G');
insert into test1 values ('C','F');
insert into test1 values ('C','G');
insert into test1 values ('C','H');
代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql.functions import collect_list
# 创建一个连接
spark = SparkSession. \
Builder(). \
appName('sql'). \
master('local'). \
getOrCreate()
# spark.sql执行默认是取值Hive表,类型是DataFrame类型
# spark.sql("use test")
df1 = spark.sql("select id1,id2 as id2_1 from test1")
df2 = spark.sql("select id1,id2 as id2_2 from test1")
df = spark.sql("select distinct id1 as id1 from test1")
# 首先通过表连接 t1.id1 = t2.id1 and t1.id2 != t2.id2 构造一个需要的多行数据
df3 = df1.join(df2,df1.id1 == df2.id1 ,'inner').select(df1.id1, df1.id2_1, df2.id2_2)
df4 = df3.select("id1", "id2_1", "id2_2").where(" id2_1 != id2_2 ")
# 其次剔除掉id1这个多余的列,id2_1可以有id2_2 这么多个间接好友,因为可能存在重复,进行去重操作
df5 = df4.drop('id1')
df6 = df5.distinct()
# 因为上述的结果集是id2_1的间接好友集,但是可能也会含有id2_1的直接好友,需要剔除
df7 = df6.select("id2_1", "id2_2").subtract(df1.select("id1", "id2_1"))
df8 = df7.groupby('id2_1').agg(collect_list(df7["id2_2"]).alias("id2_2_new"))
df9 = df8.join(df, df.id1 == df8.id2_1,'inner').select(df8.id2_1, df8.id2_2_new)
df9.show()
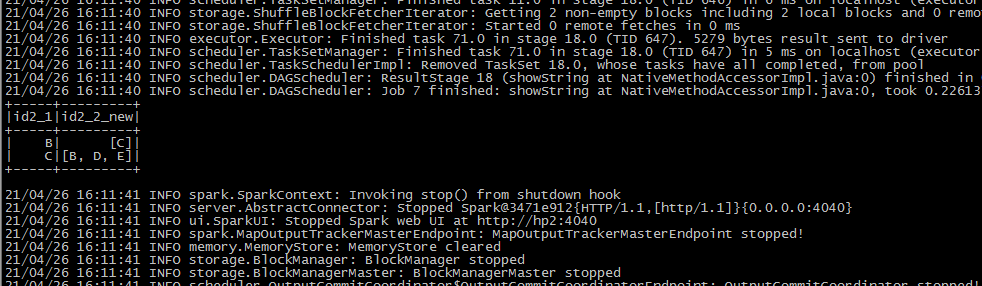
测试记录:

















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









