





文章:Traffic Signs and Pedestrians Vision with Multi-Scale Convolutional Networks(Snowbird 11)(2页)
作者:Pierre Sermanet , Koray Kavukcuoglu and Yann LeCun
卷积网络:
卷积网络是受生物启发的多阶段体系结构,能够自动学习不变特征的层次结构。目前多种主流的方法使用手工提取的特征,比如HOG或者SIFT特征,卷积网络能够从数据中学习每个层次上的特征,这些特征能够根据任务的不同进行去微调。
传统的卷积网络只是将第2个阶段的特征送入到分类器中,本文中改进了此方法,同时将第1个阶段的特征送入到分类器中。我们将这种多尺度的卷积网络应用到交通路标分类和行人检测中;在道路标志方面,其效果比人为表现(human performance)优秀,创造了新的准确度记录。在行人检测方面,如果配合使用无监督的预训练(pre-training)和 卷积预测稀疏编码(Convolutional Predictive Sparse Coding)[1],也能使得精度显著增加。
卷积网络的实现:EBLearn C++ open-source package [2].
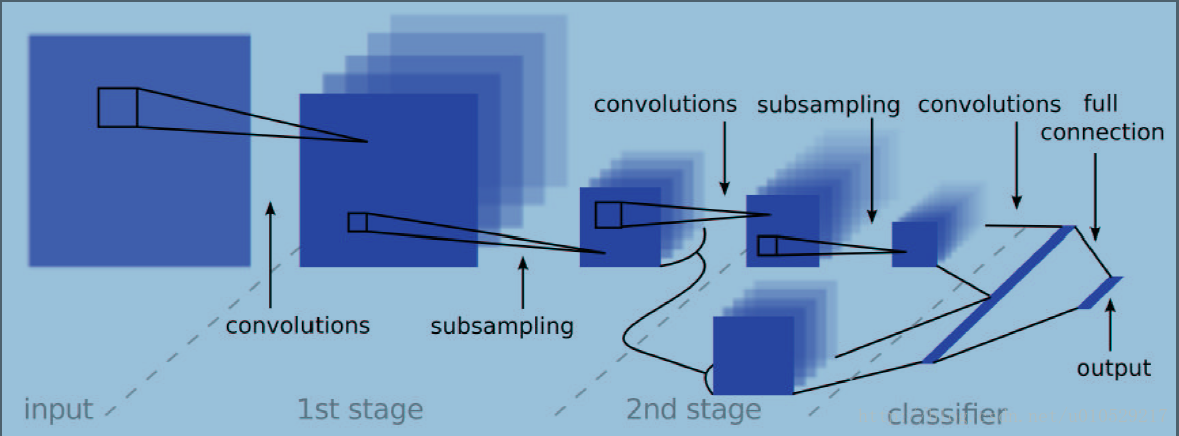
图1: A 2-stage multi-scale ConvNet architecture.The input is processed in a feed-forward manner through two stage of convolutions and subsampling, and finally classified with a linear classifier. The output of the 1st stage is also fed directly to the classifier as higher-scale features.
任务一:交通路标的识别
交通路标的识别是一个相对受限的问题,因为每个路标都是唯一的、死板的、表面没什么变化,GTSRB是一个新的realistic数据库,库中的图像被现实世界的因素所影响,比如角度变化,照明条件(饱和度、低对比度),运动模糊,遮挡,阳光耀眼,物理伤害,颜色褪色,涂鸦,贴纸和一个分辨率低至15 x15的输入。如图2a所示:

图2a. Difficult road sign examples in GTSRB coming from real-word perturbations
GTSRB交通图标分类任务第一阶段的比赛在2011年1月召开,我们的系统获得了第二名,准确率为98.97%(第一名为98.98%),高于人为表现,使用的是:32*32的彩色输入图像。之后的实验中,通过改用灰度图像和增加网络容量(network capacity),准确率达到99.17%。见图2b。

图2b. Official top 7 results and new accuracy record after GTSRB Phase 1 (99.17%).
任务二:行人检测
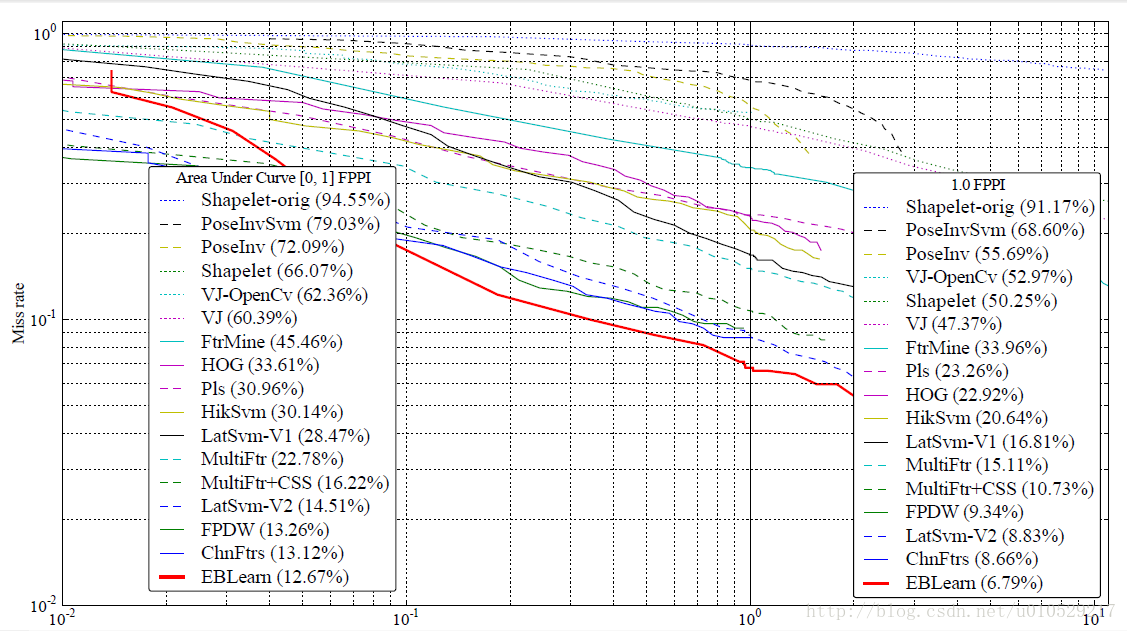
我们也将多尺度的卷积网络应用到 the INRIA 行人检测任务中。此外,我们使用ConvPSD(即Convolutional Predictive Sparse Coding:卷积预测稀疏编码)方法进行无监督的预训练,初始化网络的权重,创造了一个新的记录 of 6.79% miss rate at 1 false positive per image (FPPI) and 12.67% of area under curve (AUC) in the [0,1] FPPI range.
ps:unsupervised pre-training只是用在了pedestrian detection task。
图3比较了发表在the Caltech pedestrian website(http://www.vision.caltech.edu/Image Datasets/CaltechPedestrians)的算法.
False positives per image (FPPI)
图3.DET curves on the INRIA pedestrian test set, plotting false positives per image (FPPI) against miss rate.
Algorithms are sorted from top to bottom using 2 metrics: on the left is the area under curve (AUC) between 0 and
1 FPPI, on the right is the miss rate at 1 FPPI. Our algorithm (“EBLearn”) outperforms other algorithms published
on the Caltech pedestrian website.
在之前的一个实验中[1],通过使用无监督预训练(unsupervised pre-training),我们的错误率从14.8%降到11.5% at 1 FPPI,得到了改善。
总结:
创新点:同时将两个阶段的特征输入到分类其中,提高了准确率。
本文中参考文献:
[4] Dalal, N and Triggs, B. Histograms of oriented gradients for human detection. In Schmid, C, Soatto, S, and Tomasi, C, editors, International Conference on Computer Vision & Pattern Recognition, volume 2, pages 886–893, INRIA Rhˆone-Alpes, ZIRST-655, av. de l’Europe, Montbonnot-38334, June 2005.















 2313
2313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









