








表示法
一个不相交集合森林(树集合)有许多元素组成,每个元素保存一个id,一个父指针,并且在高效算法中,还保存一个size或一个rank值
这些元素的父指针被排列成一个或多个树的形式,每一个树代表一个集合。如果一个元素的父指针没有指向其他元素,那么这个元素就是这棵树的root节点,并且是该集合的代表成员。一个集合可以只由一个元素组成。不管怎样,如果元素有一个父,这个元素被标识为跟随它父指针链向上直到树的root节点代表元素(一个没有父指针的节点)集合的一部分
森林(树集合)可以在内存中被紧凑的表示为数组,父节点可以用他们的索引指示
操作
新增-MakeSet
MakeSet操作通过创建一个唯一ID,一个0的rank,并且父指针指向它自身的新元素。指向它自身的父指针表示它自己集合的代表成员元素
MakeSet操作时间复杂度O(1),所以初始化n个集合的时间复杂度为O(n)。
伪代码:
function MakeSet(x) is
if x is not already present then
add x to the disjoint-set tree
x.parent := x
x.rank := 0
x.size := 1
查找-Find
Find(x)表示沿着父指针链从x节点向树上方查找直到父指针是它自身的root元素。该root元素是x所属集合的代表元素,也可能是它自身。
路径压缩-Path compression
每当对树结构使用find查找时,路径压缩使每个节点指向root节点使树的结构变得单调平整。这是有效的,因为在访问root节点的路径上被访问的每个节点都是同一集合的一部分。扁平树结果不仅加快未来对这些元素的操作,也加快了对引用他们的元素操作。
Tarjan与Van Leeuwen也开发一种单遍查找算法,在实践中更加高效,同时保留同样最差情况的复杂度:路径拆分和路径二分。
路径二分-Path halving
路径二分使至root节点路径上每个其他(非x节点)节点指向它的祖父节点
路径拆分-Path splitting
路径拆分使至root节点路径上每个节点指向它的祖父节点
伪代码
伪代码(个人理解伪代码的halving与splitting部分写反了)
Path compression
function Find(x)
if x.parent ≠ x
x.parent := Find(x.parent)
return x.parent
Path halving
function Find(x)
while x.parent ≠ x
x.parent := x.parent.parent
x := x.parent
return x
Path splitting
function Find(x)
while x.parent ≠ x
x, x.parent := x.parent, x.parent.parent
return x
路径压缩可以使用迭代法实现,通过首先找到root节点,然后更新所有的父指针:
function Find(x) is
root := x
while root.parent ≠ root
root := root.parent
while x.parent ≠ root
parent := x.parent
x.parent := root
x := parent
return root
路径拆分可以不用多重分配来表示(先求右边的值):
function Find(x)
while x.parent ≠ x
next := x.parent
x.parent := next.parent
x := next
return x
or
function Find(x)
while x.parent ≠ x
prev := x
x := x.parent
prev.parent := x.parent
return x
合并-Union
Union(x,y)使用查找确定x和y所属树的root节点。如果root节点不同,通过将一个树的root节点附加到另一个树的root节点合并。如果单纯的这样做,例如始终使x称为y的子,树的高度增长为O(n)。To prevent this union by rank or union by size is used.为了避免这样的高度增长合并可以通过使用rank或者size
按等级-by rank
按rank合并始终让较短小的树附加至较高大的树上。因此,合并树的结果集不会比原始树更高,除非两个树是同样的高度,在这种情况下,合并树的结果集会高出一个节点。
为实现按等级合并,每个元素需要关联一个等级。初始化一个集合有一个元素等级为0。如果两个集合被合并并且有相同的等级,合并结果的集合的等级会大一级; 否则,如果两个集合合并并且两个集合的等级不同,合并树的结果的等级是两者中较大的那个集合的等级。等级被用来代替高度或者深度,因为路径压缩会随着时间的推移而改变树的高度。
按大小-by size
按大小合并始终将较少元素的树附加到拥有较多元素的树的root节点
伪代码
伪代码
Union by rank
function Union(x, y) is
xRoot := Find(x)
yRoot := Find(y)
if xRoot = yRoot then
// x与y已经在同一个集合里,直接返回
return
// x与y不在同一个集合里,那么我们合并他们
if xRoot.rank < yRoot.rank then
xRoot, yRoot := yRoot, xRoot // 交换x的根节点与y的根节点
// 合并y根节点至x根节点
yRoot.parent := xRoot
if xRoot.rank = yRoot.rank then
xRoot.rank := xRoot.rank + 1
Union by size
function Union(x, y) is
xRoot := Find(x)
yRoot := Find(y)
if xRoot = yRoot then
// x and y are already in the same set
return
// x and y are not in same set, so we merge them
if xRoot.size < yRoot.size then
xRoot, yRoot := yRoot, xRoot // swap xRoot and yRoot
// merge yRoot into xRoot
yRoot.parent := xRoot
xRoot.size := xRoot.size + yRoot.size
应用
- 初始化并查集,遍历所有顶点执行MakeSet
- 所有的边按照权重由小至大排序
- 遍历所有边
- 对边的两个顶点执行Find得到两个顶点的root根节点,判断两个节点是否属于同一个集合
- 如果边的两点不属于同一个集合,执行合并:Union。并将边加入最小生成树结果集
- 如果边的两点属于同一个集合,继续遍历
- 直到最短生成树集合中包含了所有顶点,结束循环,返回最小生成树
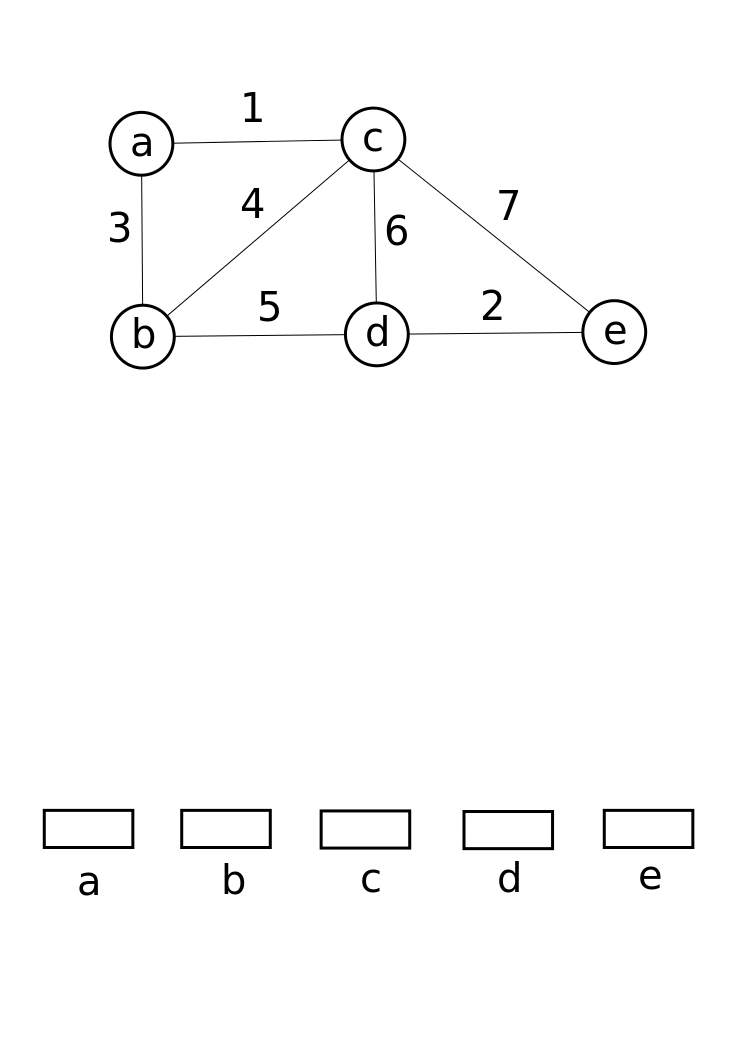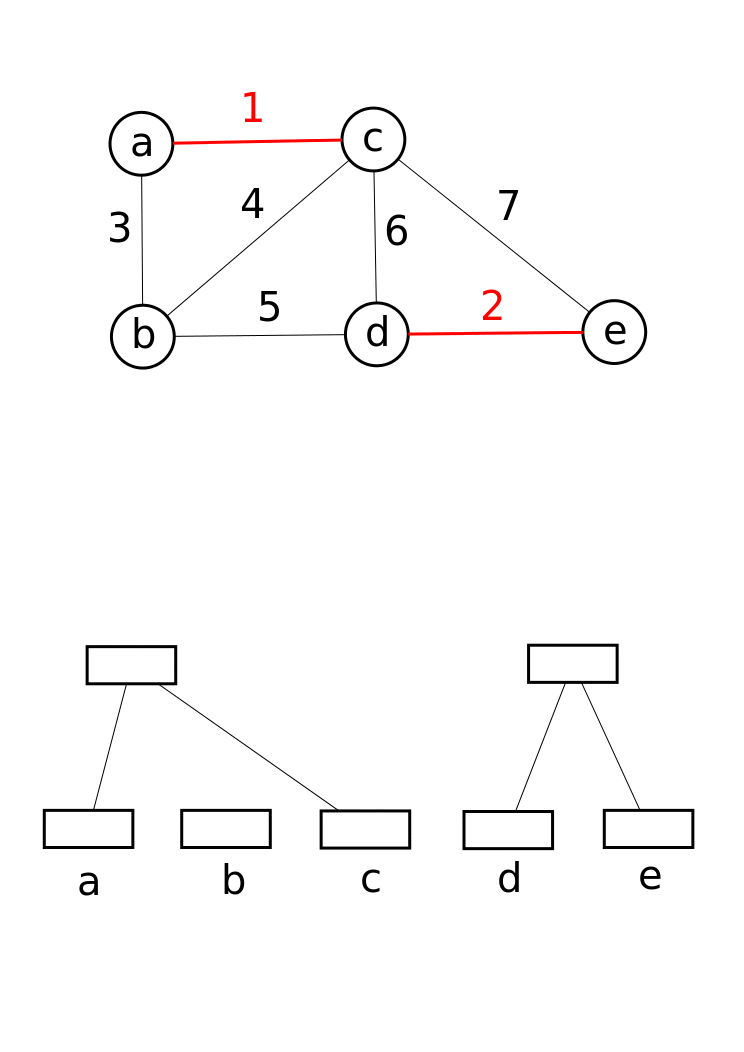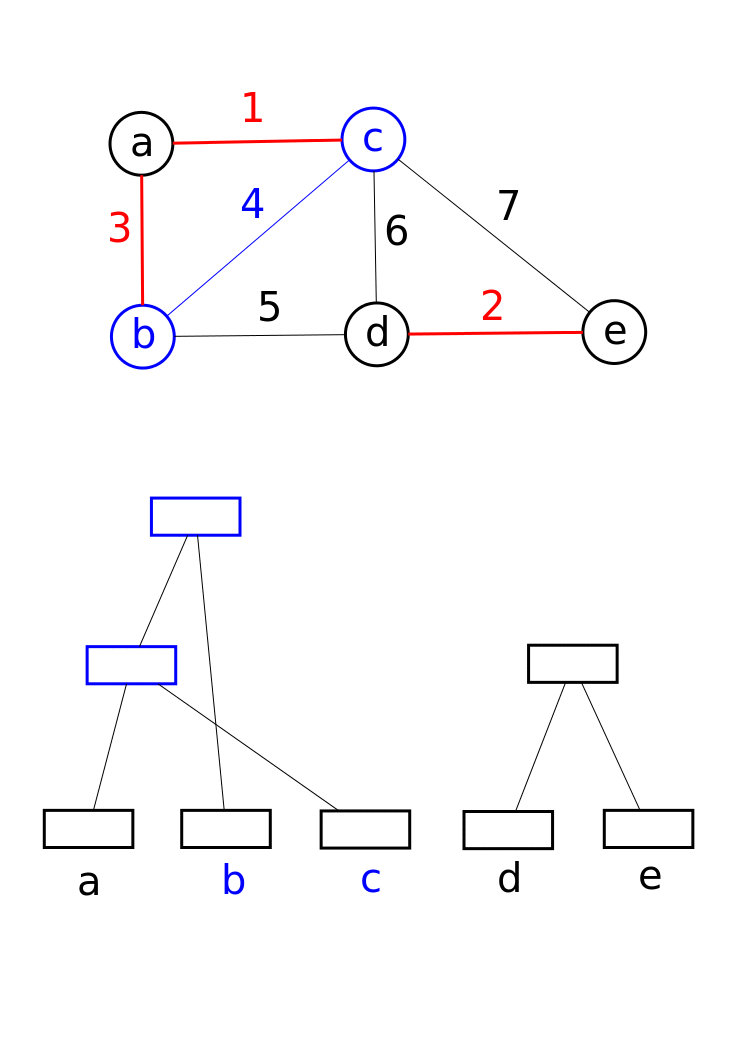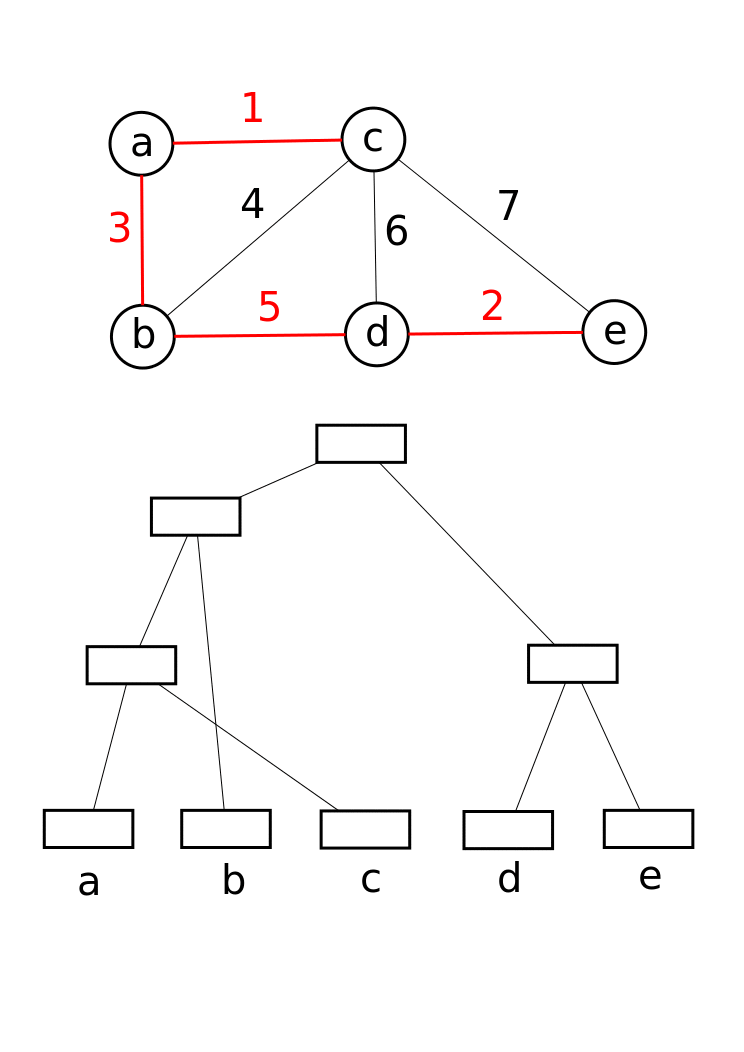
最小生成树,Kruskal算法实现,伪代码
algorithm Kruskal(G) is
A := ∅
for each v ∈ G.V do
MAKE-SET(v)
for each (u, v) in G.E ordered by weight(u, v), increasing do
if FIND-SET(u) ≠ FIND-SET(v) then
A := A ∪ {(u, v)}
UNION(FIND-SET(u), FIND-SET(v))
return A
原文
https://en.wikipedia.org/wiki/Disjoint-set_data_structure
https://en.wikipedia.org/wiki/Kruskal%27s_algorithm














 2529
2529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









