







最近折腾文件系统,用到了Hadoop,虽然项目是部署在Linux下的。但自己平时开发用的是windows系统(本人用的是win10 64bit)。为了方便开发和调试,所以打算在windows环境下安装hadoop。
往上找了几篇文章,都说得不是很详细。安装过程中遇到了一些问题,索性自己折腾了一番,终于搞好了。
准备条件:
首先需要下载 hadoop的tar.gz包,目前最新版本是2.7.3 下载地址:http://hadoop.apache.org/releases.html
然后确保操作系统是64bit,已安装.netframework,要4.0以上版本,一般现在的windows系统都有自带的。
第三是配置好Java环境,至于java环境的配置这里不介绍,百度一下就知道了。我这里用的是JDK1.7.80。
重点:因为是在windows下面安装的,跟linux下不一样,所以我们需要windows下运行的链接库。这个库我已经基本配置好,直接覆盖就可以使用了。除了JDK路径,一般不需要改其他东西。
下载地址:http://download.csdn.NET/detail/kokjuis/9706480
开始:
确保上述的条件以后,我们开始来安装hadoop。
1)解压下载好的 hadoop-2.7.3.tar.gz 到某个盘下,注意路径里不要带空格,否则可能会无法正确识别。
2)解压hadooponwindows-master.zip,直接覆盖到hadoop-2.7.3根目录。
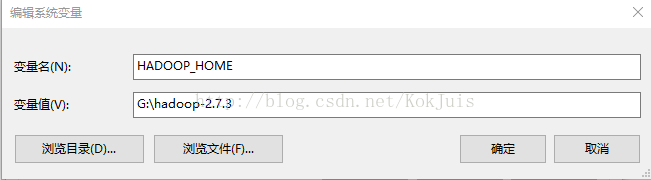
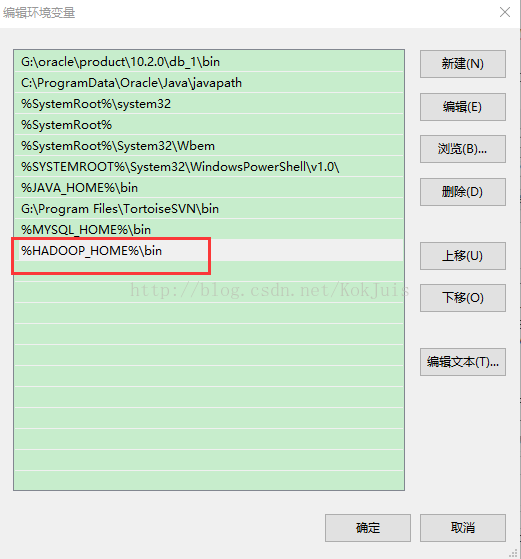
3)配置hadoop环境变量(跟配置JAVA环境变量类似)。 创建HADOOP_HOME,另外在Path下添加 %HADOOP_HOME%\bin
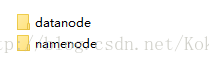
4)到hadoop根目录,如果没有data文件夹的话就新建一个,然后在data下分别创建datanode、namenode两个文件夹
5)用记事本打开 \hadoop-2.7.3\etc\hadoop\hadoop-env.cmd文件,修改JAVA_HOME为你自己jdk路径。注意:如果你的JDK安装在Program Files目录下,名称用\PROGRA~1\Java 否则中间的空格可能会识别失败。

到这里,配置基本已经完成,如果你想改访问路径,可以到etc/hadoop目录下的core-site.xml文件修改:
最后,点击命令提示符(管理员)运行命令提示符,切换到hadoop的安装目录。进行以下操作
1、切换到etc/hadoop目录,运行hadoop-env.cmd
2、格式化HDFS文件系统,切换到bin目录然后执行命令:hdfs namenode -format
到这里,你的hadoop就可以正常使用了。可以查看一下版本 hadoop version

启动:
切换到 sbin目录 执行:start-dfs.cmd
查看hadoop管理页面:http://localhost:50070















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









