






#第一步:程序引用包import cv2import selectivesearchimport matplotlib.pyplot as pltimport matplotlib.patches as mpatchesimport numpy as np#原始图片为拿画板随便写的几个数字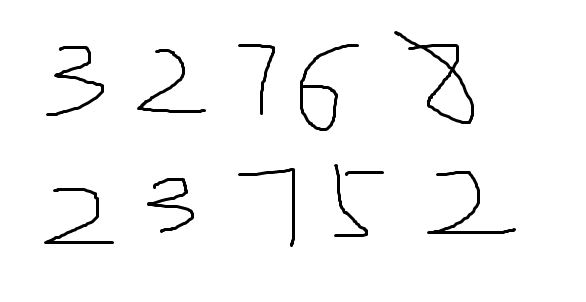 #第二步:执行搜索工具,展示搜索结果image2="test2.png"#用cv2读取图片img = cv2.imread(image2)#白底黑字图 改为黑底白字图img=255-img#selectivesearch 调用selectivesearch函数 对图片目标进行搜索img_lbl, regions =selectivesearch.selective_search(img, scale=500, sigma=0.9, min_size=20)print (regions[0]) #{'labels': [0.0], 'rect': (0, 0, 585, 301), 'size': 160699} 第一个为原始图的区域print (len(regions)) #共搜索到199个区域# 接下来我们把窗口和图像打印出来,对它有个直观认识fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img)for reg in regions:x, y, w, h = reg['rect']rect = mpatches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1)ax.add_patch(rect)plt.show()#搜索完成后展示图
#第二步:执行搜索工具,展示搜索结果image2="test2.png"#用cv2读取图片img = cv2.imread(image2)#白底黑字图 改为黑底白字图img=255-img#selectivesearch 调用selectivesearch函数 对图片目标进行搜索img_lbl, regions =selectivesearch.selective_search(img, scale=500, sigma=0.9, min_size=20)print (regions[0]) #{'labels': [0.0], 'rect': (0, 0, 585, 301), 'size': 160699} 第一个为原始图的区域print (len(regions)) #共搜索到199个区域# 接下来我们把窗口和图像打印出来,对它有个直观认识fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img)for reg in regions:x, y, w, h = reg['rect']rect = mpatches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1)ax.add_patch(rect)plt.show()#搜索完成后展示图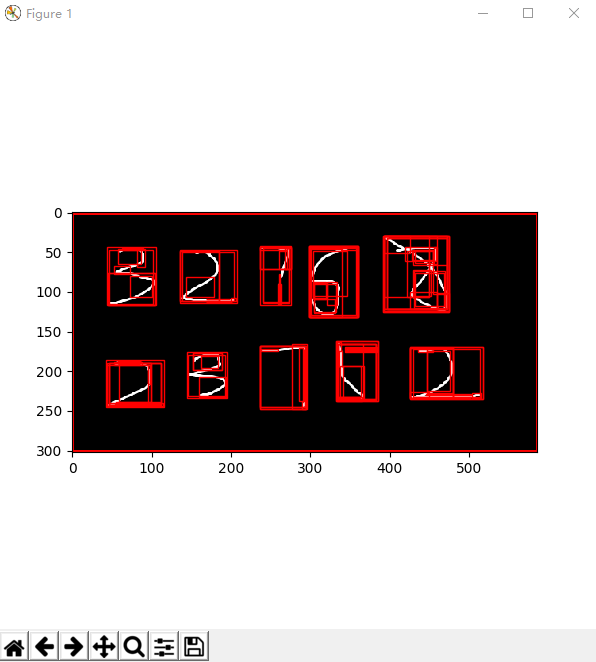 #第三步:过滤掉冗余的窗口#1)第一次多虑candidates = []for r in regions:# 重复的不要if r['rect'] in candidates:continue# 太小和太大的不要if r['size'] < 200 or r['size']>20000:continuex, y, w, h = r['rect']# 太不方的不要if w / h > 1.2 or h / w > 1.2:continuecandidates.append((x,y,w,h))##('len(candidates)', 34) 一次过滤后剩余34个窗print ('len(candidates)',len(candidates))#2)第二次过滤 大圈套小圈的目标 只保留大圈num_array=[]for i in candidates:if len(num_array)==0:num_array.append(i)else:content=Falsereplace=-1index=0for j in num_array:##新窗口在小圈 则滤除if i[0]>=j[0] and i[0]+i[2]<=j[0]+j[2]and i[1]>=j[1] and i[1]+i[3]<=j[1]+j[3]:content=Truebreak##新窗口不在小圈 而在老窗口外部 替换老窗口elif i[0]<=j[0] and i[0]+i[2]>=j[0]+j[2]and i[1]<=j[1] and i[1]+i[3]>=j[1]+j[3]:replace=indexbreakindex+=1if not content:if replace>=0:num_array[replace]=ielse:num_array.append(i)#窗口过滤完之后的数量len=len(num_array)#二次过滤后剩余10个窗print 'len====',len#3)对过滤完的窗口进行展示fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img)for x, y, w, h in num_array:rect = mpatches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1)ax.add_patch(rect)plt.show()
#第三步:过滤掉冗余的窗口#1)第一次多虑candidates = []for r in regions:# 重复的不要if r['rect'] in candidates:continue# 太小和太大的不要if r['size'] < 200 or r['size']>20000:continuex, y, w, h = r['rect']# 太不方的不要if w / h > 1.2 or h / w > 1.2:continuecandidates.append((x,y,w,h))##('len(candidates)', 34) 一次过滤后剩余34个窗print ('len(candidates)',len(candidates))#2)第二次过滤 大圈套小圈的目标 只保留大圈num_array=[]for i in candidates:if len(num_array)==0:num_array.append(i)else:content=Falsereplace=-1index=0for j in num_array:##新窗口在小圈 则滤除if i[0]>=j[0] and i[0]+i[2]<=j[0]+j[2]and i[1]>=j[1] and i[1]+i[3]<=j[1]+j[3]:content=Truebreak##新窗口不在小圈 而在老窗口外部 替换老窗口elif i[0]<=j[0] and i[0]+i[2]>=j[0]+j[2]and i[1]<=j[1] and i[1]+i[3]>=j[1]+j[3]:replace=indexbreakindex+=1if not content:if replace>=0:num_array[replace]=ielse:num_array.append(i)#窗口过滤完之后的数量len=len(num_array)#二次过滤后剩余10个窗print 'len====',len#3)对过滤完的窗口进行展示fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img)for x, y, w, h in num_array:rect = mpatches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1)ax.add_patch(rect)plt.show() #第四步:搜索完后的窗口,上下是有序的 左右是无序的,所以上下分别进行排序 并合并L1=num_array[0:len//2]L2=num_array[len//2:]L1.sort(lambda x,y:cmp(x[0],y[0]))print 'L1',L1L2.sort(lambda x,y:cmp(x[0],y[0]))print 'L2',L2L1.extend(L2)print 'num_array===',num_arrayprint u"最终筛选后的窗口是:",L1#第五步:提取窗口图片后转化为28*28的标准图Width=28Height=28#横向图片数组img_sample = np.zeros((len, Width*Height))i = 0for rect in num_array:x, y, w, h = rect#大图中截图窗口图片img_cut = img[y :y+h, x:x +w,:]#截取后的小图添加padding 生成方形图if w > h:real_size=welse:real_size=htop_padding=int( (real_size - h) / 2)left_padding=int( (real_size - w) /2)#加padding方法img_cut = cv2.copyMakeBorder(img_cut,top_padding,top_padding,left_padding,left_padding,borderType=cv2.BORDER_REPLICATE)#把方形图 压缩成28*28的图img_resize = cv2.resize(img_cut, (Width, Height), interpolation=cv2.INTER_NEAREST)#压缩后的图转化成灰度图gray = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)#生成的小图保存到本地cv2.imwrite('images/img_'+str(i)+'.png',gray)#生成的小图展平 放到img_sample里img_sample[i, :] = gray.ravel()i += 1#第六步:把转换后的数据用长图来显示img_s = np.zeros((Width, Height * img_sample.shape[0]))for i in xrange(img_sample.shape[0]):img_s[:, i * Width:Height * (i + 1)] =img_sample[i, :].reshape(Width, Height)fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img_s, cmap='gray')plt.savefig("number.jpg", bbox_inch="tight")plt.show()
#第四步:搜索完后的窗口,上下是有序的 左右是无序的,所以上下分别进行排序 并合并L1=num_array[0:len//2]L2=num_array[len//2:]L1.sort(lambda x,y:cmp(x[0],y[0]))print 'L1',L1L2.sort(lambda x,y:cmp(x[0],y[0]))print 'L2',L2L1.extend(L2)print 'num_array===',num_arrayprint u"最终筛选后的窗口是:",L1#第五步:提取窗口图片后转化为28*28的标准图Width=28Height=28#横向图片数组img_sample = np.zeros((len, Width*Height))i = 0for rect in num_array:x, y, w, h = rect#大图中截图窗口图片img_cut = img[y :y+h, x:x +w,:]#截取后的小图添加padding 生成方形图if w > h:real_size=welse:real_size=htop_padding=int( (real_size - h) / 2)left_padding=int( (real_size - w) /2)#加padding方法img_cut = cv2.copyMakeBorder(img_cut,top_padding,top_padding,left_padding,left_padding,borderType=cv2.BORDER_REPLICATE)#把方形图 压缩成28*28的图img_resize = cv2.resize(img_cut, (Width, Height), interpolation=cv2.INTER_NEAREST)#压缩后的图转化成灰度图gray = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)#生成的小图保存到本地cv2.imwrite('images/img_'+str(i)+'.png',gray)#生成的小图展平 放到img_sample里img_sample[i, :] = gray.ravel()i += 1#第六步:把转换后的数据用长图来显示img_s = np.zeros((Width, Height * img_sample.shape[0]))for i in xrange(img_sample.shape[0]):img_s[:, i * Width:Height * (i + 1)] =img_sample[i, :].reshape(Width, Height)fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img_s, cmap='gray')plt.savefig("number.jpg", bbox_inch="tight")plt.show()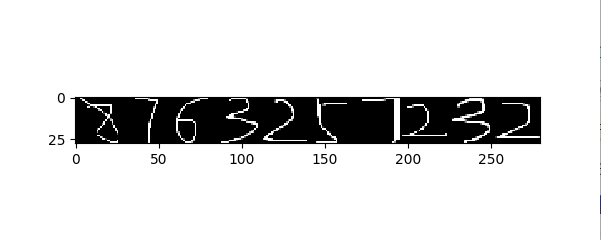 注:接下来可以使用训练好的模型来识别这些提取出来的图片,例如mnist数据集的训练模型。利用MNIST数据集进行模型训练,然后进行识别。模型主要由三部分构成,卷积,池化,全连接,用三层卷积,前两层卷积完后进行池化,最后一次卷积完直接reshape,用两层全连接就行,测试正确率能达到99.1%,暂时不需要加入L2损失,或者dropout。
注:接下来可以使用训练好的模型来识别这些提取出来的图片,例如mnist数据集的训练模型。利用MNIST数据集进行模型训练,然后进行识别。模型主要由三部分构成,卷积,池化,全连接,用三层卷积,前两层卷积完后进行池化,最后一次卷积完直接reshape,用两层全连接就行,测试正确率能达到99.1%,暂时不需要加入L2损失,或者dropout。














 330
330
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









