









YOLO 是 2016 年提出来的目标检测算法,在当时比较优秀的目标检测算法有 R-CNN、Fast R-CNN 等等,但 YOLO 算法还是让人感到很新奇与兴奋。
YOLO 是 You only look once 几个单词的缩写,大意是你看一次就可以预测了,灵感就来自于我们人类自己,因为人看一张图片时,扫一眼就可以得知这张图片不同类型目标的位置。
1.创新
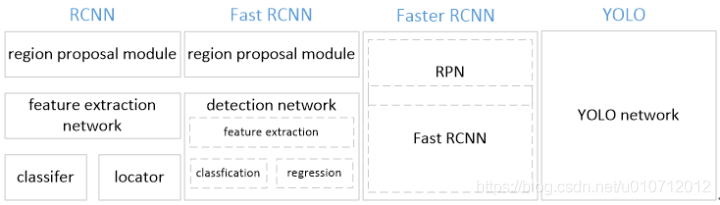
YOLO将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。从网络设计上,YOLO与rcnn、fast rcnn及faster rcnn的区别如下:
[1]
YOLO训练和检测均是在一个单独网络中进行。YOLO没有显示地求取region proposal的过程。而rcnn/fast rcnn 采用分离的模块(独立于网络之外的selective search方法)求取候选框(可能会包含物体的矩形区域),训练过程因此也是分成多个模块进行。Faster rcnn使用RPN(region proposal network)卷积网络替代rcnn/fast rcnn的selective
search模块,将RPN集成到fast rcnn检测网络中,得到一个统一的检测网络。尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络(注意这两个网络核心卷积层是参数共享的)。
[2]
YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
2.设计理念
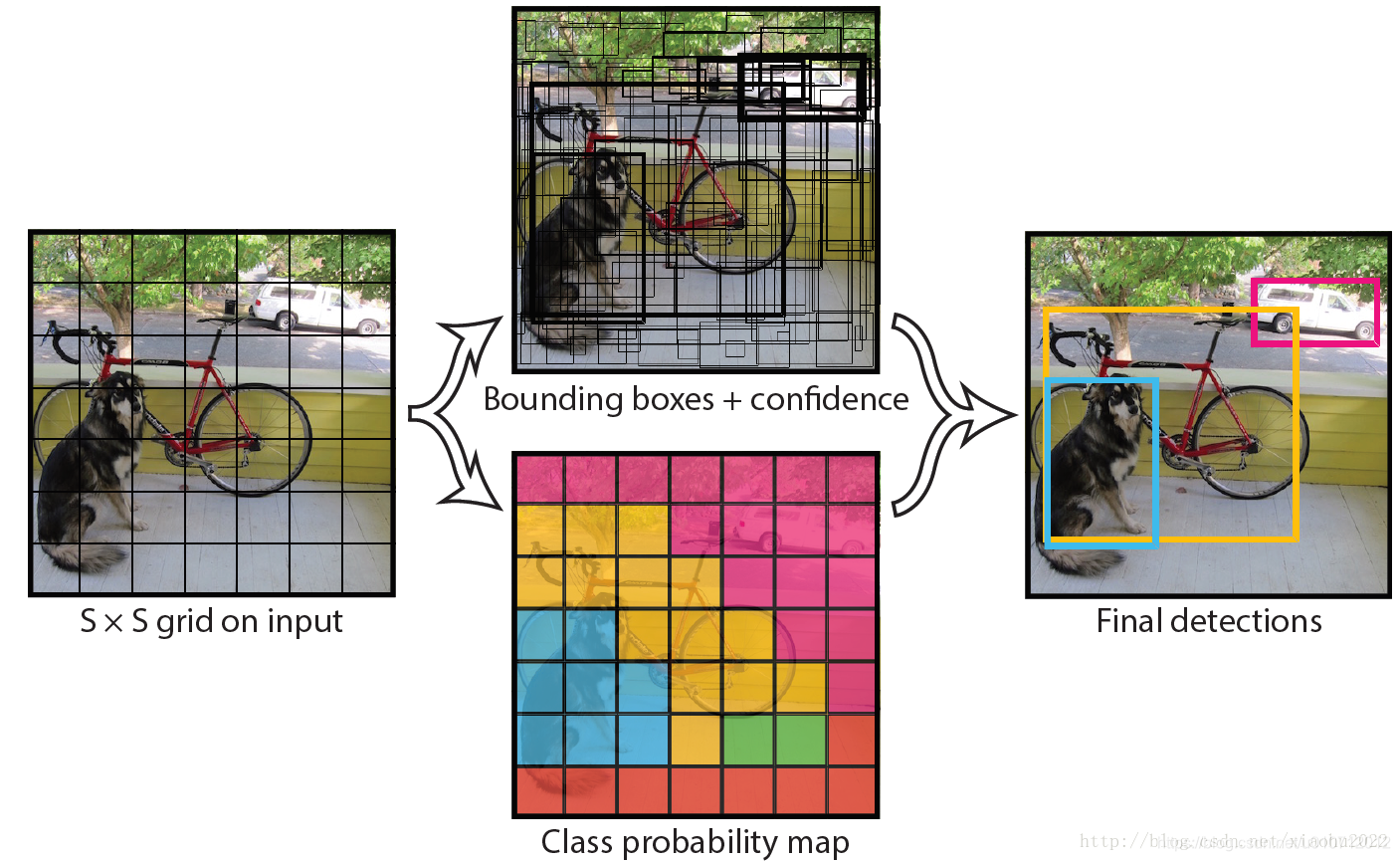
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如下图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。

YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗。

每个格子输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。
Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内;x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1]。
confidence反映当前bounding box是否包含物体以及物体位置的准确性,计算方式如下: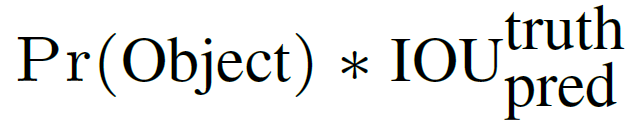
若bounding box包含物体,则P(object) = 1;否则P(object) = 0. IOU(intersection over union)为预测boundingbox与物体真实区域的交集面积(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)。
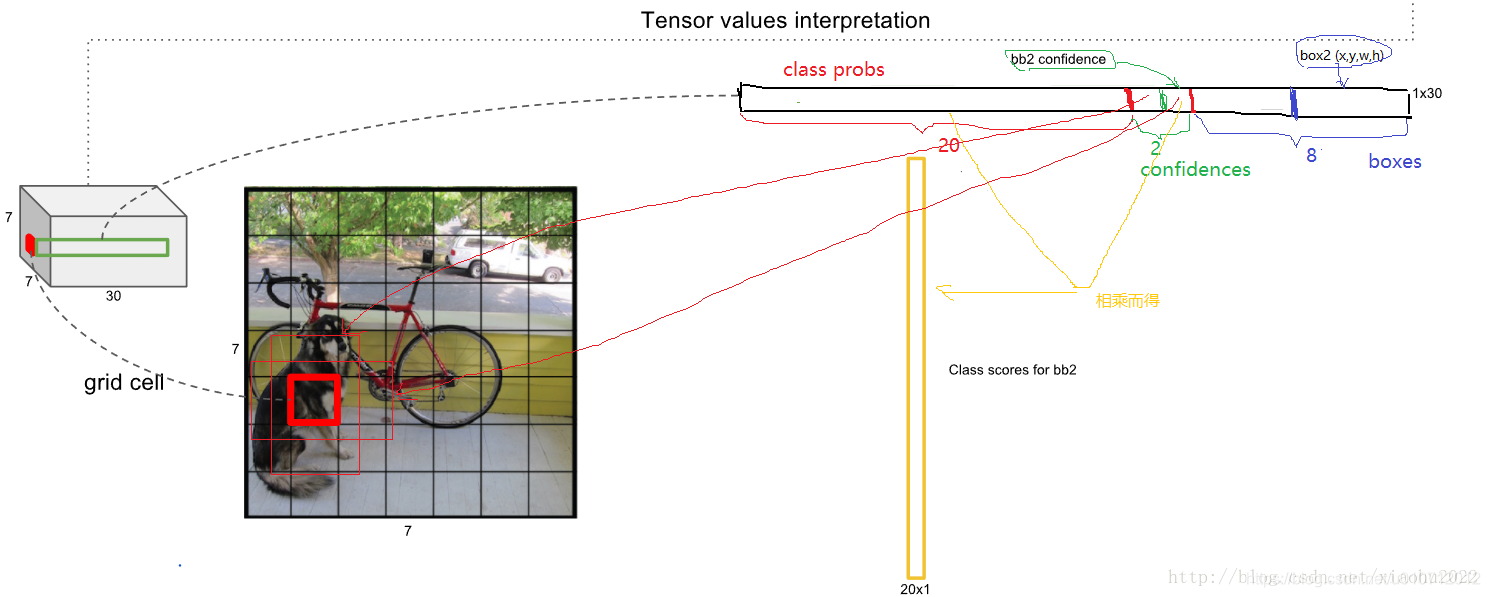
因此,YOLO网络最终的全连接层的输出维度是 S * S * (B * 5 + C)。YOLO论文中,作者训练采用的输入图像分辨率是448x448,S=7,B=2;采用VOC 20类标注物体作为训练数据,C=20。因此输出向量为7 * 7 * (20 + 2 * 5)=1470维。作者开源出的YOLO代码中,全连接层输出特征向量各维度对应内容如下:

注:
由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。
虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
总结一下,每个单元格需要预测大小的张量。在下面的网络结构中我们会详细讲述每个单元格的预测值的分布位置。
3.网络设计
YOLO检测网络包括24个卷积层和2个全连接层,如下图所示。

YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception
module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
YOLO论文中,作者还给出一个更轻快的检测网络fast YOLO,它只有9个卷积层和2个全连接层。使用titan x GPU,fast YOLO可以达到155fps的检测速度,但是mAP值也从YOLO的63.4%降到了52.7%,但却仍然远高于以往的实时物体检测方法(DPM)的mAP值。
可以看到网络的最后输出为是边界框的预测结果。这样,提取每个部分是非常方便的,这会方面后面的训练及预测时的计算。
在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:
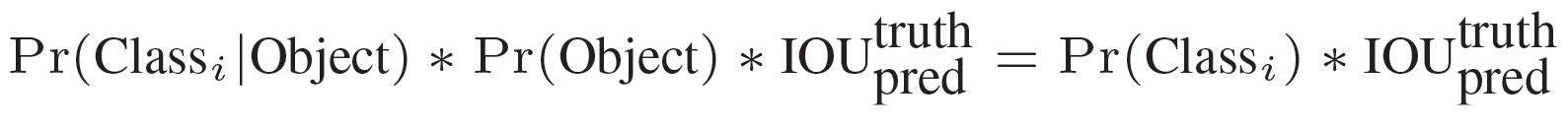
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
4.Loss函数定义
YOLO使用均方和误差作为loss函数来优化模型参数,即网络输出的S * S * (B * 5 + C)维向量与真实图像的对应S * S * (B * 5 + C)维向量的均方和误差。如下式所示。其中,coordError、iouError和classError分别代表预测数据与标定数据之间的坐标误差、IOU误差和分类误差。
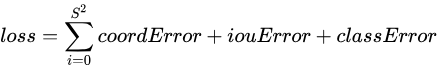
这种做法存在以下几个问题:
因为每个grid有30维,这30维中,8维是回归box的坐标,2维是box的confidence,还有20维是类别。其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。从而有以下问题:
第一,8维的localization error和20维的classification error同等重要显然是不合理的;
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决办法:
YOLO对上式loss的计算进行了如下修正。
[1] 位置相关误差(坐标、IOU)与分类误差对网络loss的贡献值是不同的,因此YOLO在计算loss时,使用 λ c o o r d = 5 \lambda _{coord} =5 λcoord=5修正coordError。
[2] 在计算IOU误差时,包含物体的格子与不包含物体的格子,二者的IOU误差对网络loss的贡献值是不同的。若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用 λ n o o b j = 0.5 \lambda _{noobj} =0.5 λnoobj=0.5修正iouError。(注此处的‘包含’是指存在一个物体,它的中心坐标落入到格子内)。
[3] 对于相等的误差值,大物体误差对检测的影响应小于小物体误差对检测的影响。这是因为,相同的位置偏差占大物体的比例远小于同等偏差占小物体的比例。YOLO将物体大小的信息项(w和h)进行求平方根来改进这个问题。(注:这个方法并不能完全解决这个问题)。
综上,YOLO在训练过程中Loss计算如下式所示:

其中,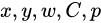 为网络预测值,
为网络预测值,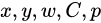 帽 为标注值。
Π
i
o
b
j
\Pi _{i}^{obj}
Πiobj (这里这个符号其实是空心的1)表示物体落入格子i中,
Π
i
j
o
b
j
\Pi _{ij}^{obj}
Πijobj和
Π
i
j
n
o
o
b
j
\Pi _{ij}^{noobj}
Πijnoobj 分别表示物体落入与未落入格子i的第j个bounding box内。
帽 为标注值。
Π
i
o
b
j
\Pi _{i}^{obj}
Πiobj (这里这个符号其实是空心的1)表示物体落入格子i中,
Π
i
j
o
b
j
\Pi _{ij}^{obj}
Πijobj和
Π
i
j
n
o
o
b
j
\Pi _{ij}^{noobj}
Πijnoobj 分别表示物体落入与未落入格子i的第j个bounding box内。
注:
- YOLO方法模型训练依赖于物体识别标注数据,因此,对于非常规的物体形状或比例,YOLO的检测效果并不理想。
- YOLO采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。
- YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
5.网络训练
在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用之前图中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。整个网络的流程如下图所示:
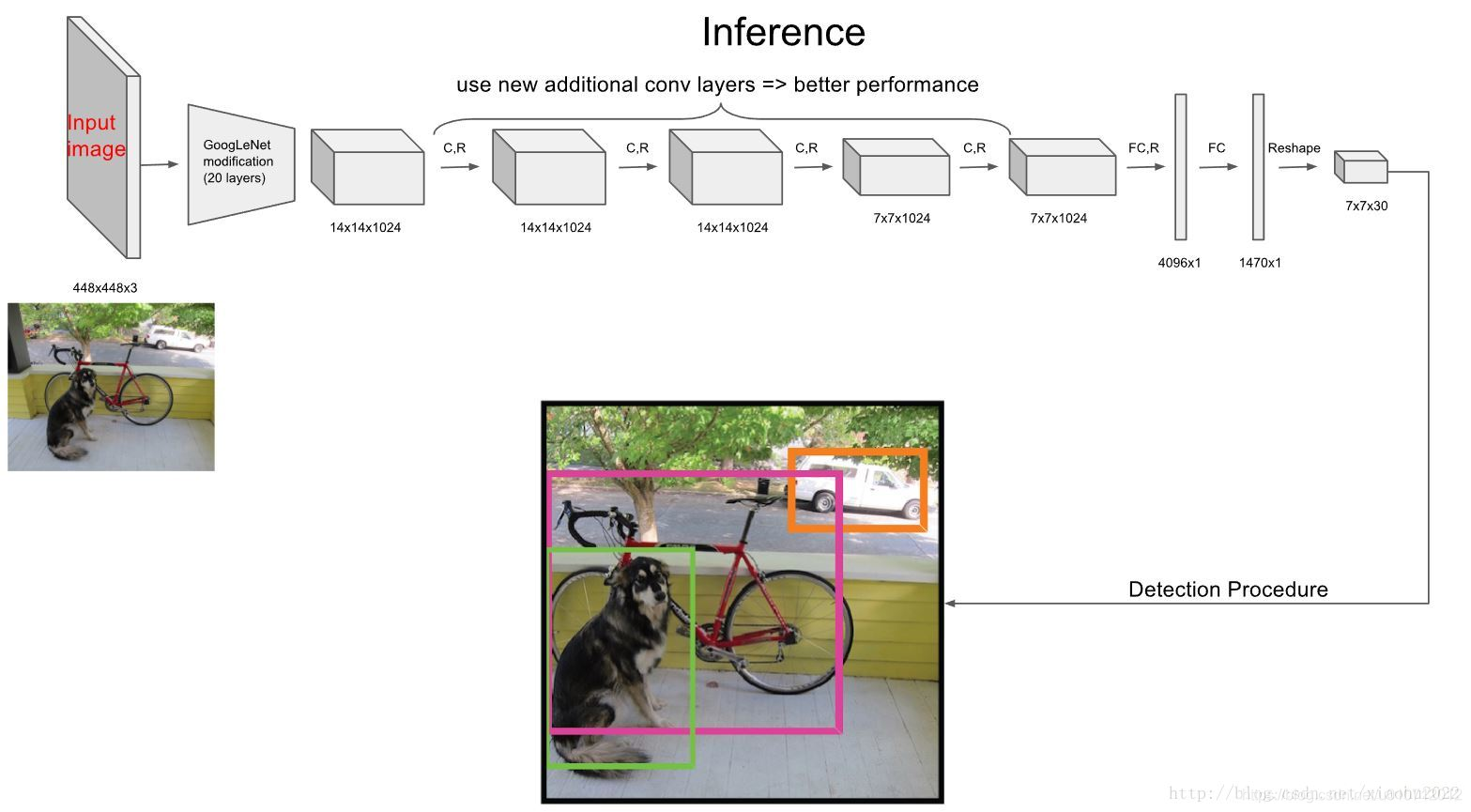
我们再来详细回顾下具体的训练流程
一幅图片分成7x7个网格(grid cell),某个物体的中心落在这个网格中此网格就负责预测这个物体。
最后一层输出为 (7 * 7)* 30的维度。每个 1 * 1 * 30的维度对应原图7 * 7个cell中的一个,1 * 1 * 30中含有类别预测和bbox坐标预测。总得来讲就是让网格负责类别信息,bounding box主要负责坐标信息(部分负责类别信息:confidence也算类别信息)。具体如下:
-
每个网格(1 * 1 * 30维度对应原图中的cell)要预测2个bounding box (图中黄色实线框)的坐标 ( x c e n t e r , y c e n t e r , w , h ) (x_{center},y_{center},w,h) (xcenter,ycenter,w,h) ,其中:中心坐标的 x c e n t e r , y c e n t e r x_{center},y_{center} xcenter,ycenter 相对于对应的网格归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。 每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息: c o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h confidence = Pr(Object) \ast IOU^{truth}_{pred} confidence=Pr(Object)∗IOUpredtruth。其中如果有ground true box(人工标记的物体)落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的ground truth box之间的IOU值。即:每个bounding box要预测 x c e n t e r , y c e n t e r , w , h , c o n f i d e n c e x_{center},y_{center},w,h,confidence xcenter,ycenter,w,h,confidence共5个值 ,2个bounding box共10个值,对应 1 * 1 * 30维度特征中的前10个。
-
每个网格还要预测类别信息,论文中有20类。7x7的网格,每个网格要预测2个 bounding box 和 20个类别概率,输出就是 7x7x(5x2 + 20) 。 (通用公式: SxS个网格,每个网格要预测B个bounding box还要预测C个categories,输出就是S x S x (5*B+C)的一个tensor。 注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的)
-
6.网络测试与预测
Test的时候,每个网格预测的class信息
(
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
)
( Pr(Class_i | Object) )
(Pr(Classi∣Object))和bounding box预测的confidence信息
(
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
)
( Pr(Object) \ast IOU^{truth}_{pred} )
(Pr(Object)∗IOUpredtruth)相乘,就得到每个bounding box的class-specific confidence score。
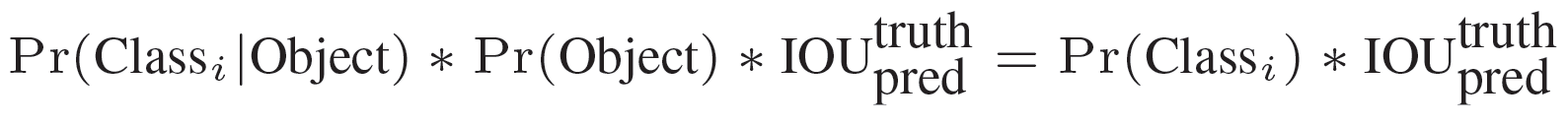
等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
对每一个网格的每一个bbox执行同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)
得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
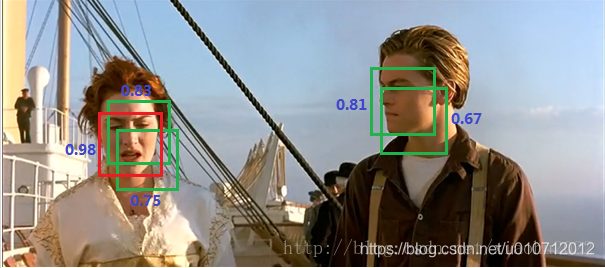
这里先介绍一下非极大值抑制算法(non maximum suppression, NMS),这个算法不单单是针对Yolo算法的,而是所有的检测算法中都会用到。NMS算法主要解决的是一个目标被多次检测的问题,如图中人脸检测,可以看到人脸被多次检测,但是其实我们希望最后仅仅输出其中一个最好的预测框,比如对于美女,只想要红色那个检测结果。那么可以采用NMS算法来实现这样的效果:首先从所有的检测框中找到置信度最大的那个框,然后挨个计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框。Yolo预测过程也需要用到NMS算法。
下面就来分析Yolo的预测过程,这里我们不考虑batch,认为只是预测一张输入图片。根据前面的分析,最终的网络输出是个边界框。
所有的准备数据已经得到了,那么我们先说第一种策略来得到检测框的结果,我认为这是最正常与自然的处理。首先,对于每个预测框根据类别置信度选取置信度最大的那个类别作为其预测标签,经过这层处理我们得到各个预测框的预测类别及对应的置信度值,其大小都是。一般情况下,会设置置信度阈值,就是将置信度小于该阈值的box过滤掉,所以经过这层处理,剩余的是置信度比较高的预测框。最后再对这些预测框使用NMS算法,最后留下来的就是检测结果。一个值得注意的点是NMS是对所有预测框一视同仁,还是区分每个类别,分别使用NMS。Ng在deeplearning.ai中讲应该区分每个类别分别使用NMS,但是看了很多实现,其实还是同等对待所有的框,我觉得可能是不同类别的目标出现在相同位置这种概率很低吧。
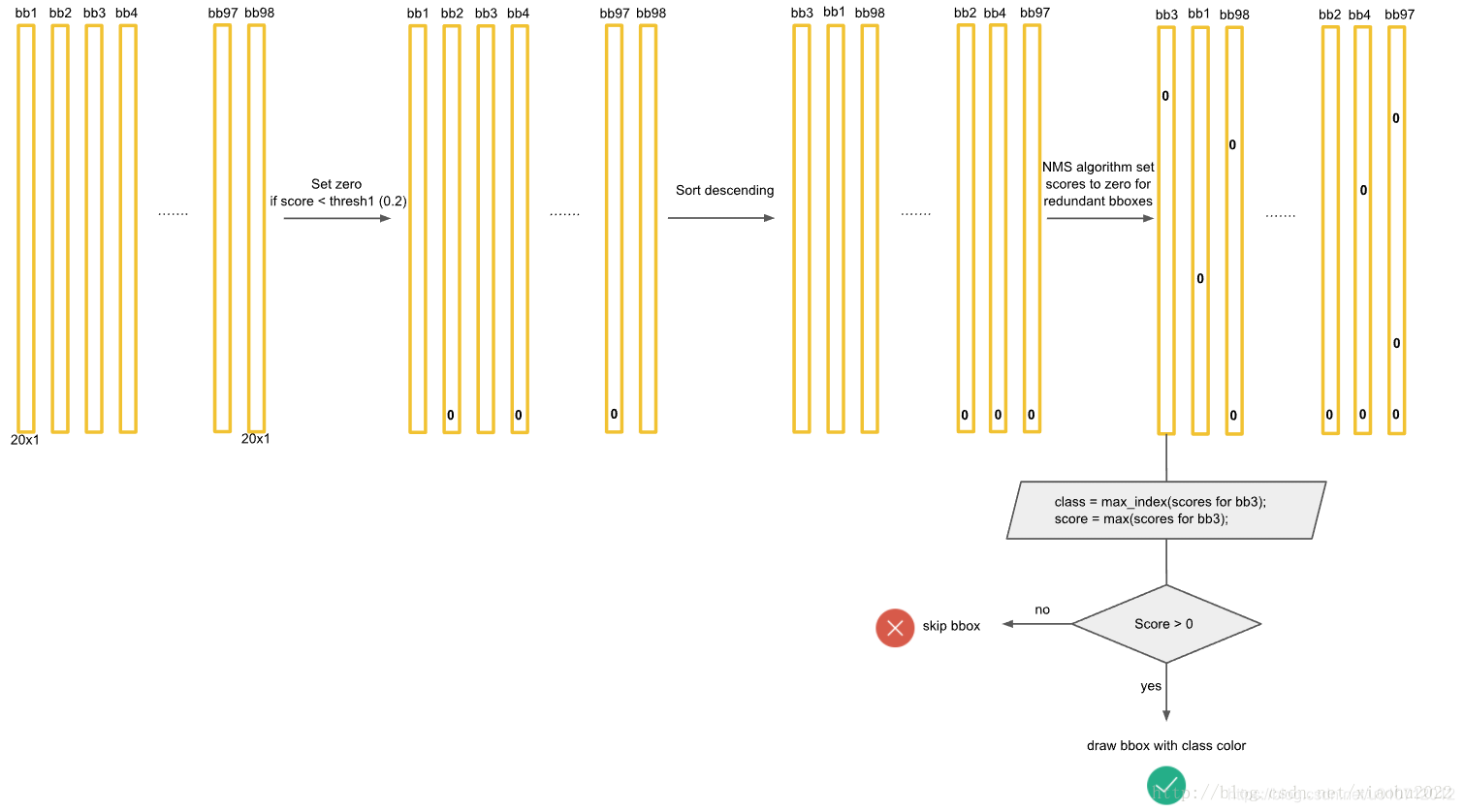
上面的预测方法应该非常简单明了,但是对于Yolo算法,其却采用了另外一个不同的处理思路(至少从C源码看是这样的),其区别就是先使用NMS,然后再确定各个box的类别。其基本过程如图所示。对于98个boxes,首先将小于置信度阈值的值归0,然后分类别地对置信度值采用NMS,这里NMS处理结果不是剔除,而是将其置信度值归为0。最后才是确定各个box的类别,当其置信度值不为0时才做出检测结果输出。这个策略不是很直接,但是貌似Yolo源码就是这样做的。Yolo论文里面说NMS算法对Yolo的性能是影响很大的,所以可能这种策略对Yolo更好。测试了普通的图片检测,两种策略结果是一样的。
7.YOLOv1的缺点
YOLO对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能力偏弱。
由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
于是,便有了后来的YOLO_v2…
参考:https://blog.csdn.net/c20081052/article/details/80236015
https://blog.csdn.net/m0_37192554/article/details/81092514














 3142
3142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









