







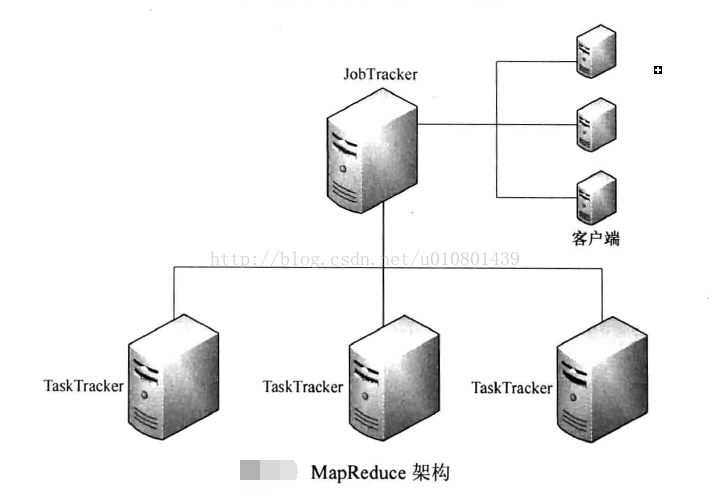
与HDFS相同的是,Hadoop的MapReduce计算框架也是主从架构,支撑MapReduce计算框架的是JobTracke:和TaskTracke:两类后台进程,如图
- JobTracker
JobTracke:在集群中扮演了主的角色,它主要负责任务调度和集群资源监控这两个功能,但并不参与具体的计算。一个Hadoop集群只有一个JobTracker,存在单点故障的可能,所以必须运行在相对可靠的节点上,一旦JobTracke:出错,将导致集群所有正在运行的任务全部失败。
与HDFS的NameNode和DataNode相似,TaskTracke:也会通过周期性的心跳向JobTracker汇报当前的健康状况和状态,心跳信息里面包括了自身计算资源的信息、被占用的计算资源的信息和正在运行中的任务的状态信息。JobTracker则会根据各TaskTracke:周期性发送过来的心跳信息综合考虑TaskTracke:的资源剩余举、作业优先级、作业提交时间等因索,为TaskCracker分配合适的任务。
JobTracker还提供了一个丛于Web的管理页面,用户以通过JobTracker:50030端口访问,如下图示,它包含了丰富的有关作业和任务的信息。
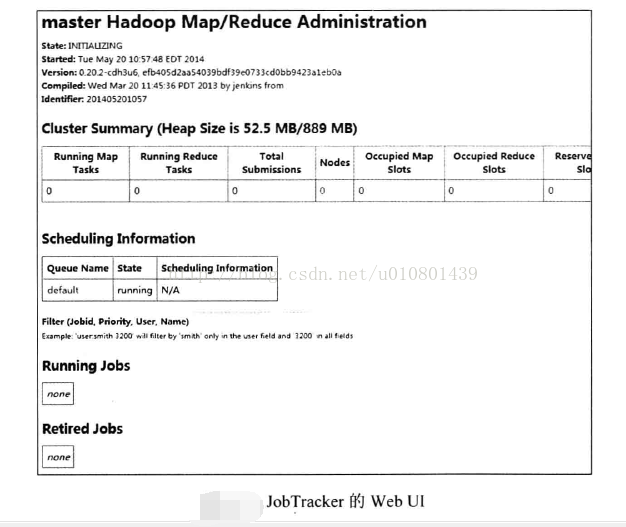
如上所说,TaskTracker会周期性地将自己的状态信息汇报给JobTracker,所以该管理界面对集群的可用资源有完整的视图。同时每一个被提交的作业都有一个作业级别的视图,如下图所示
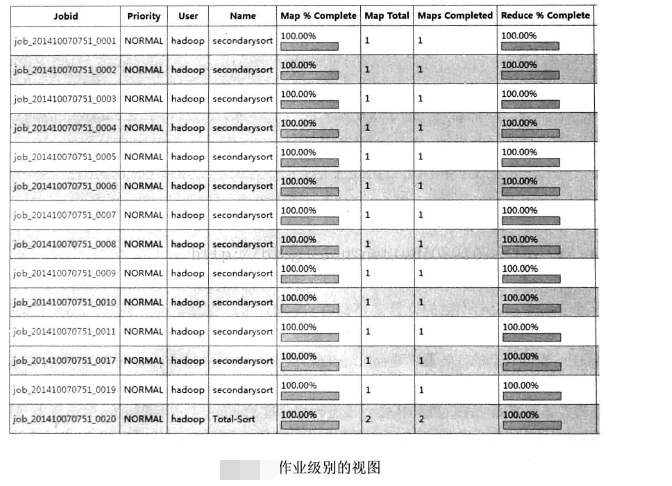
该视图提供一系列的链接用一于访问作业的配置情况,同时还提供关上进度、各种指标以及任务级别的日志,如图4-7所示。

对于Hadoop的开发人员和运维人员,这个节理界面是一个非常重要的工具。
- TaskTracker
TaskTracker在集群中扮演了从的角色,它主要负责汇报心跳和执行JobTracker的命令这两个功能。一个集群可以有多个TaskTracker,但一个节点只会有一个TaskTracker,并且TaskTracker和DataNode运行在同一个节点之中,这样,一个节点既是计算节点又是存储节点。TaskTracker
会周期性地将各种信息汇报给JobTracker,而JobTracke:收到心跳信息,会根据心跳信息和当前作业运行情况为该TaskTracker下达命令,主要包括启动任务、提交任务、杀死任务、杀死作业和重新初始化5种命令。
会周期性地将各种信息汇报给JobTracker,而JobTracke:收到心跳信息,会根据心跳信息和当前作业运行情况为该TaskTracker下达命令,主要包括启动任务、提交任务、杀死任务、杀死作业和重新初始化5种命令。
- 客户端
用户编写的MapReduce程序通过客户端提交到JobTracker。
本文参考书籍------Hadoop海量数据处理 技术详解与项目实战














 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









