







这是第二次课堂的笔记
本节课主要的主题是 When Can Machines Learn?

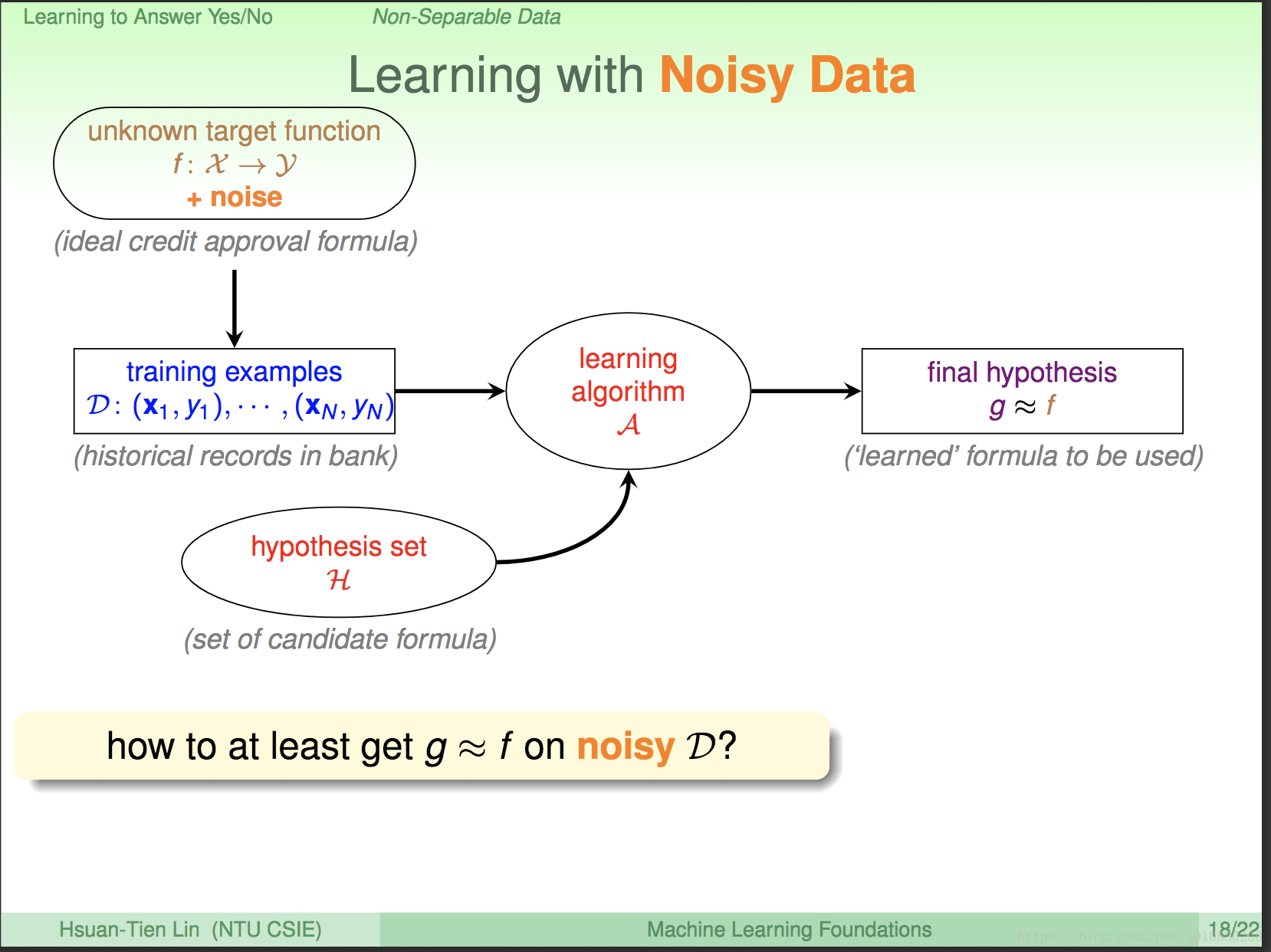
学习的主要目的是: 通过数据D(data)和 H(hupothesis,就是里面包含所有可能的函数的集合),运用算法A(algorithm) ,从H中找到最佳的函数g。 (如下图)
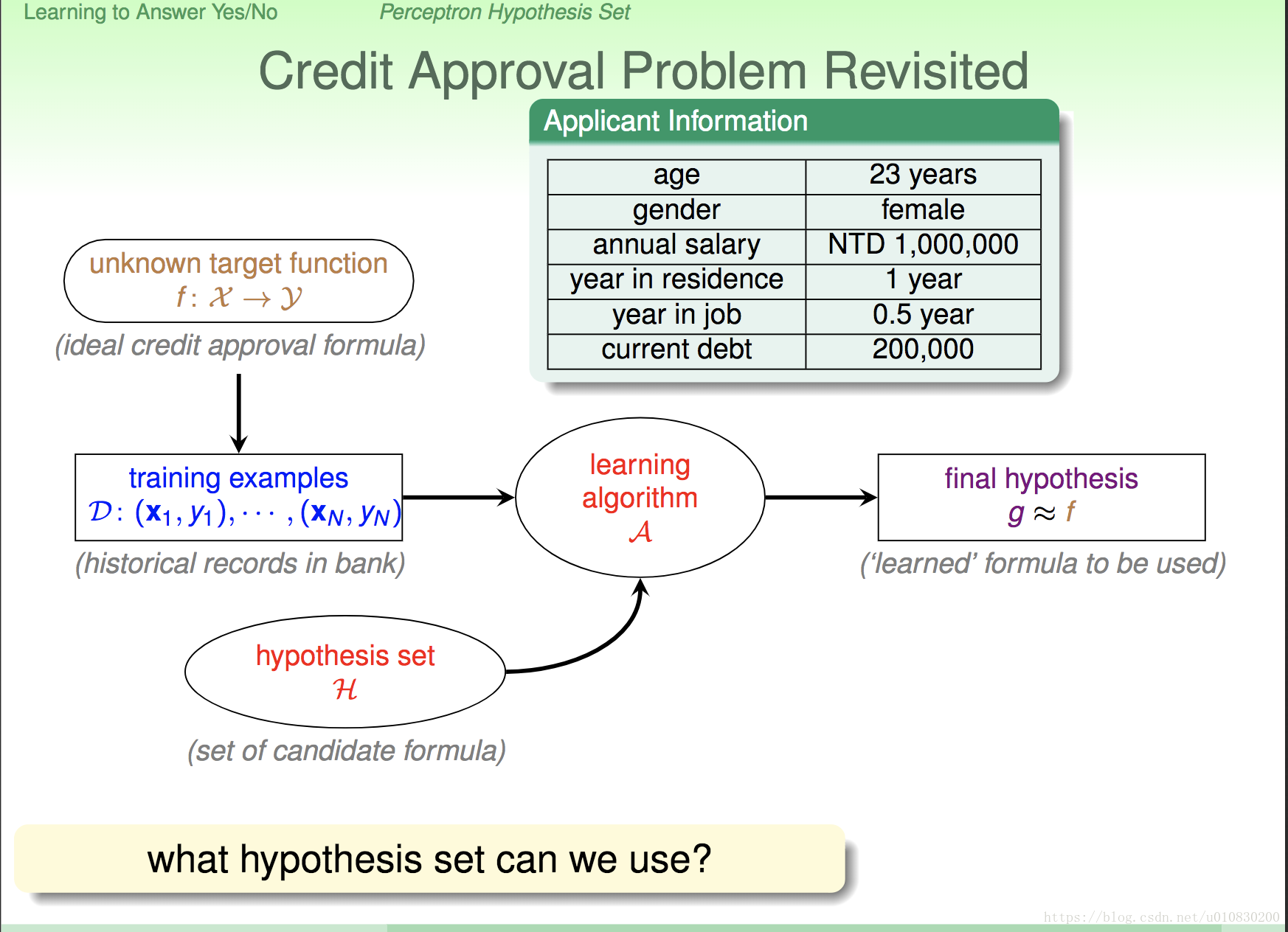
但是这有一个问题,什么样的候选公式集可以使用?(后面会介绍会介绍)
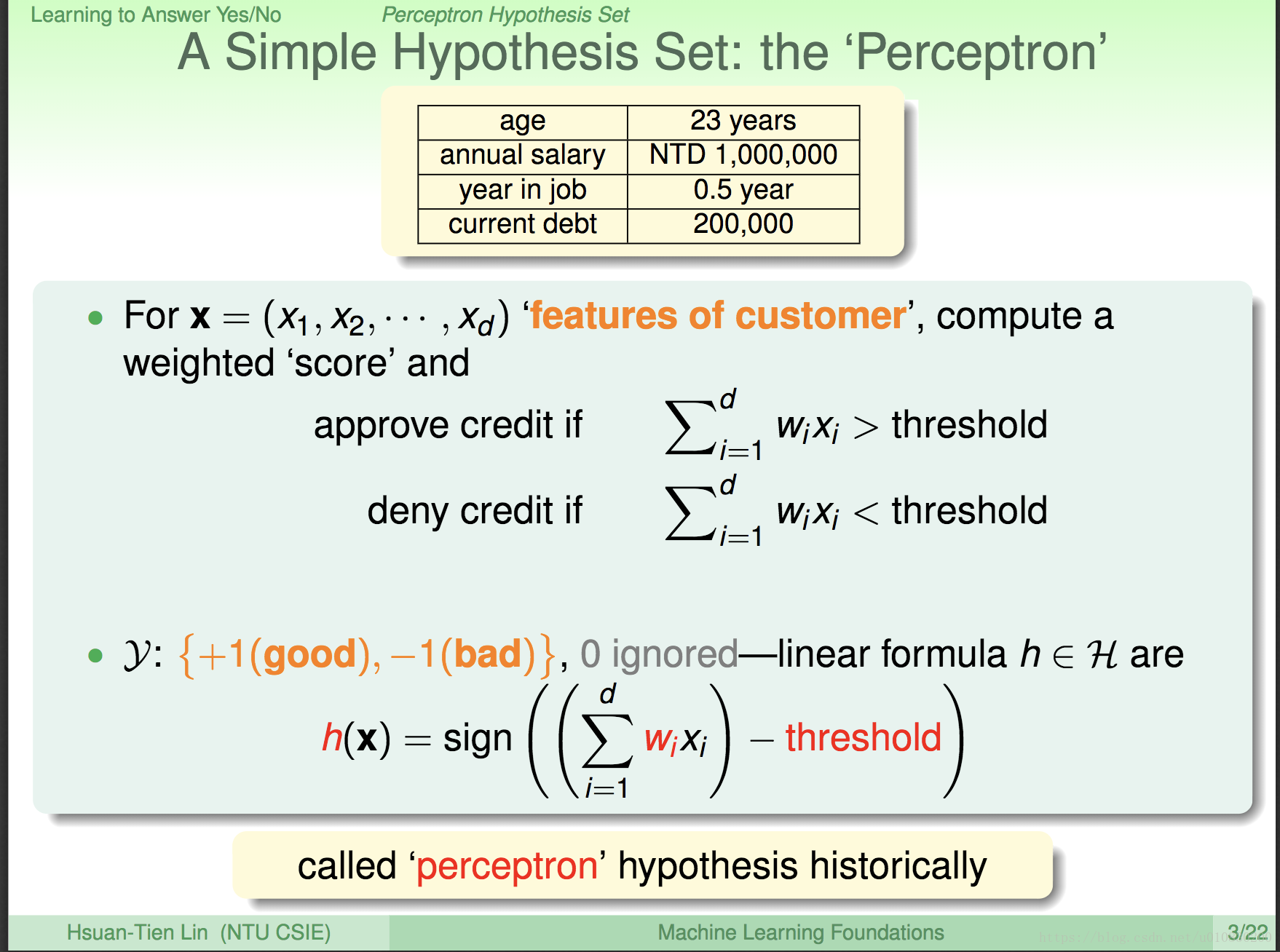
这里举的例子是一个 申请信用卡 的例子。将每一个申请人的特征 (每一个信息称为一个特征) 都符号化。
X = (x1,x2,x3…,xd)对应 申请人 = (年龄,年收入,工作年限,负债)
每一个特征都会单独分配一个权重 w (Weight),代表这个特征所占的比重,这就是所 在申请信用卡时,银行对这个特征 看不看重,看重的话,这个特征 对应的权重就大。
当 w1x1 + w2x2 + ….wdxd > 阈值 (指定值,也就是银行设定的门槛), 就允许客户申请、否则拒绝。
申请的就过无非就是 允许(+1) 和 拒绝(-1)两种情况。
这里 sign()是一个函数。

上面的过程主要是 将 式子 矢量化。方便计算。
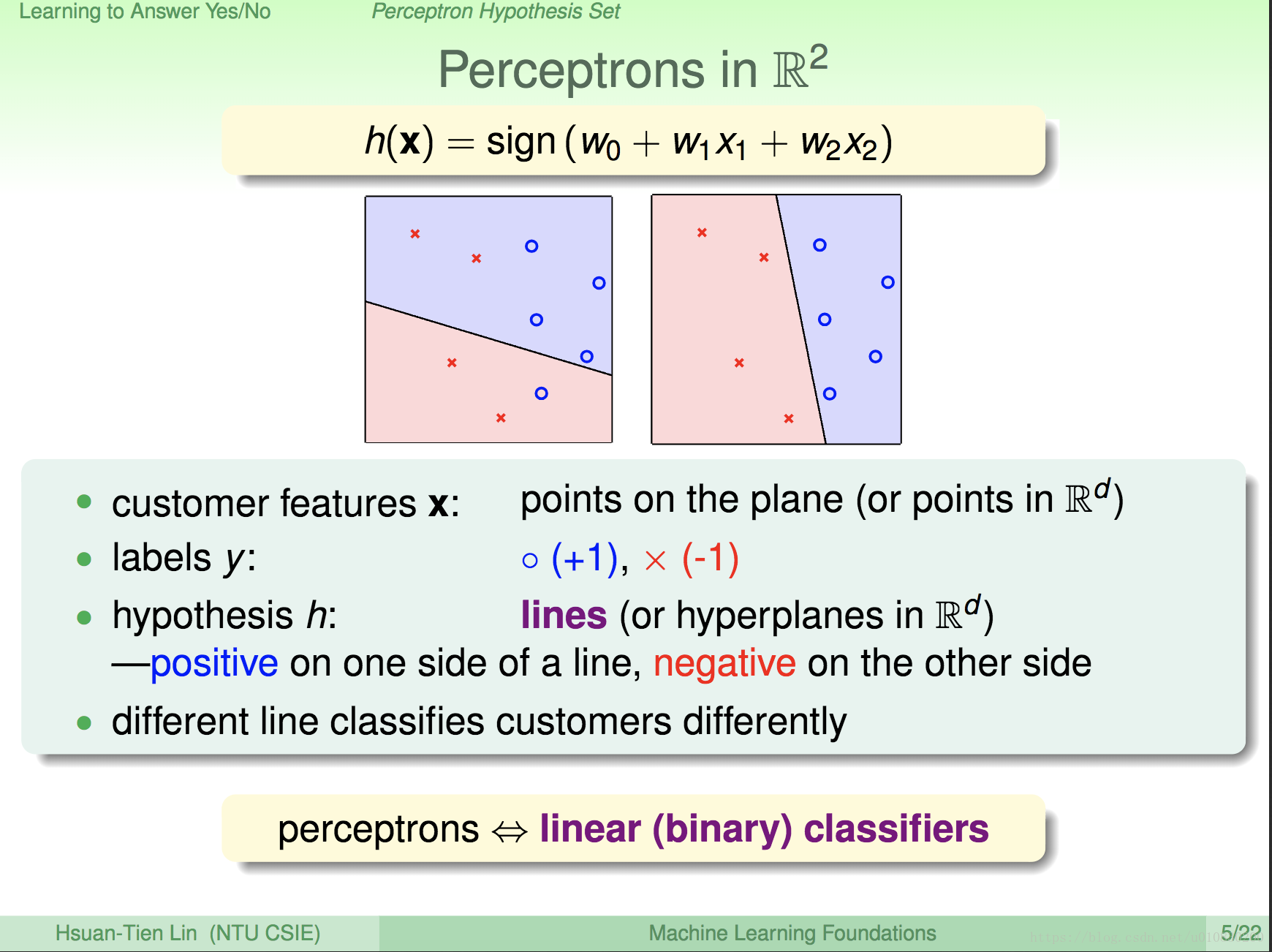
前面说过 H ,上述 PPT 就给出了H 的具体形式、。以及每个符号的意思。 H 的表现形式在图纸上画出来,也就是一条直线,所以 感知器(perceptrons) 也叫做 线性分类。

那既然知道了 H ,也拥有数据D (信用卡例子中就是以前的客户信息),那么运用 算法A 从 H 中找出g呢?
- 我们想要的函数 g 应该与 理想中的 f函数 近似 (f 我们并不知道是什么样子。只是假设f函数一定能成功分类。)
- 最起码,在已知的数据D上,g(xn) = f(xn) = yn
- 但是,H 的 形式 ,上面也列出来了,他有无穷中线条都可以表示。那么我们怎么从这么多的线条中找那条我们需要的呢?
我们首先自己 一开始先随便 定一条直线好了。在D中不断修正这条直线。
由于直线g0使用 参数 w 表示的,w改变,g0表示的直线也就改变,所以我们用 w0向量 表示 g0

这里 先理解 wtxt = w0 + w1x1 + w2x2 也就是一条直线。在这条直线的左边 为小于零,右边为大于零,在这条直线上等于0,(这是根据数据定的 哪里为大于零,哪里为小于零)。也就是当点 (x1,x2)在直线上时 wx = 0。由内积公式知道: w x cos = 0, 此时 w向量 和 x向量的夹角为 90度。以此类推,当 wx < 0时,夹角大于90; wx>0,二者夹角小于 90度
如下图
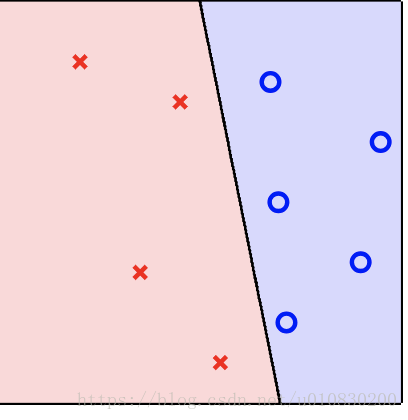
所以再看PPt, 当 wx 应该为 +1 (大于零)时,但实际 计算的 wx <0 ,那么就修正它,说明此时,二者角度过大,应该变小,所以 将 w <—- w + yx,同理当wx > 0时。

依次遍历所有的数据点x, 一直到 对所有的数据,都没有错误发生,则停止。
下面是从H 中寻找g 直线的 过程。原点定在了中间。从x1点 开始检测
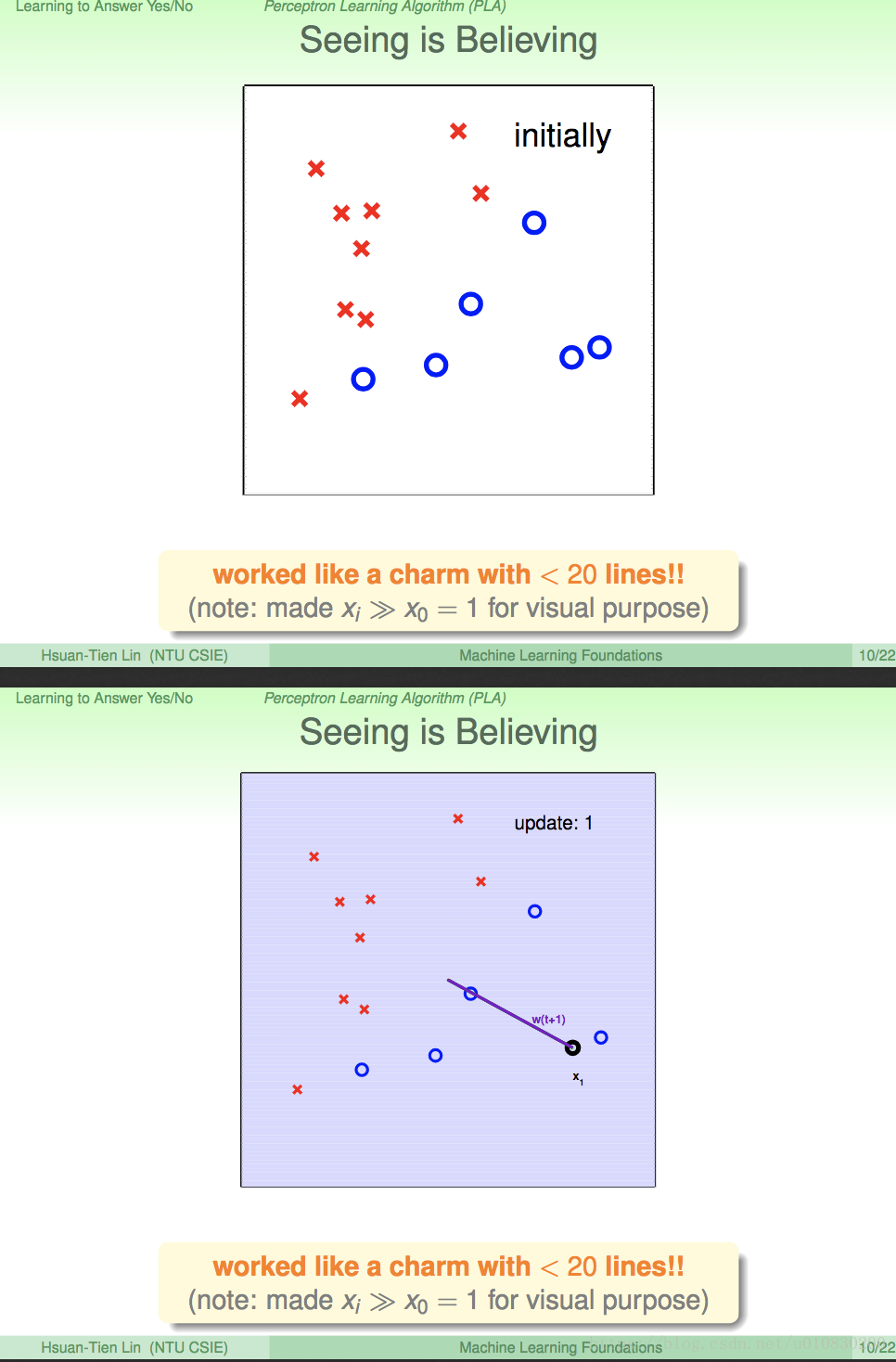
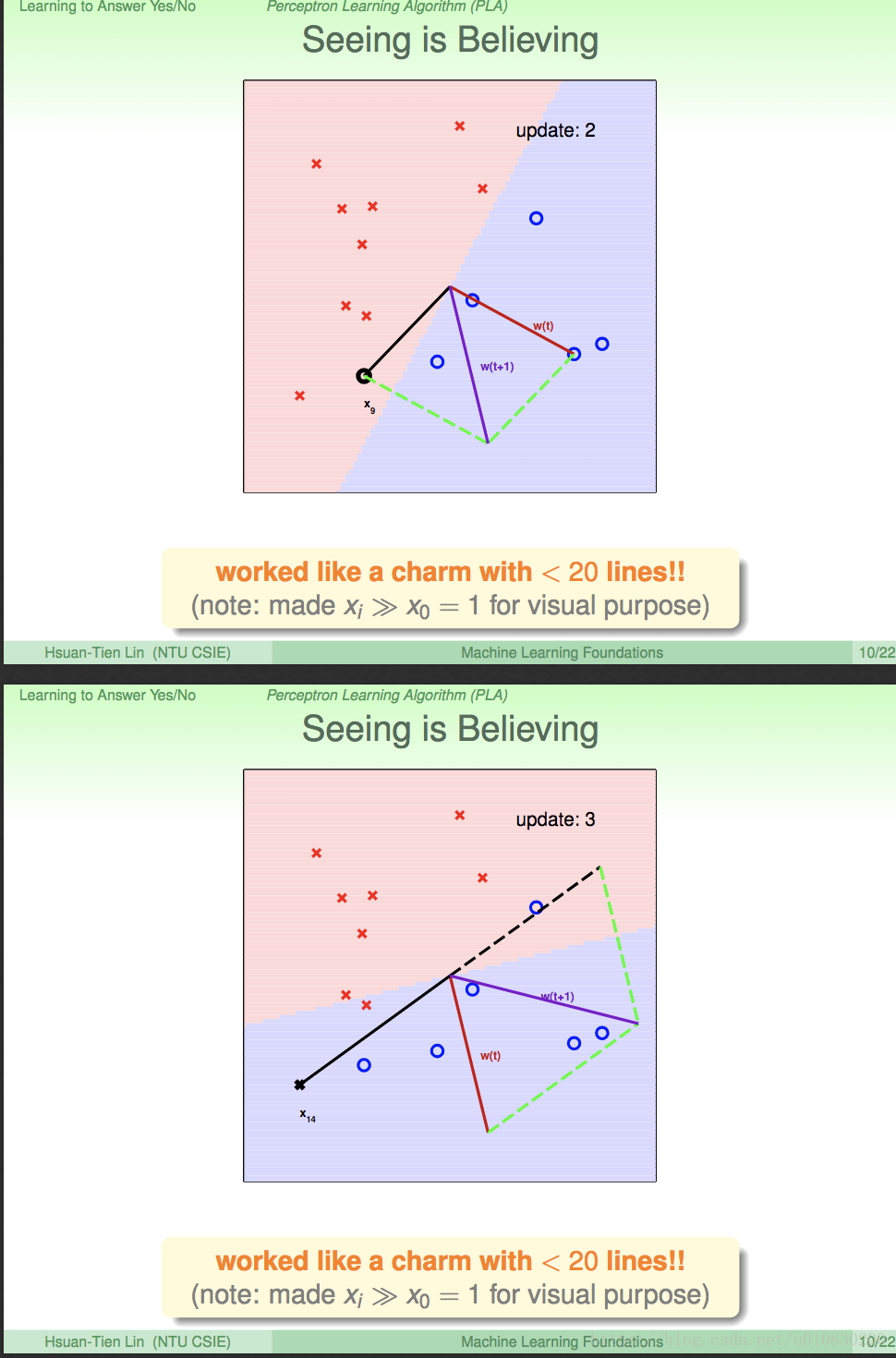
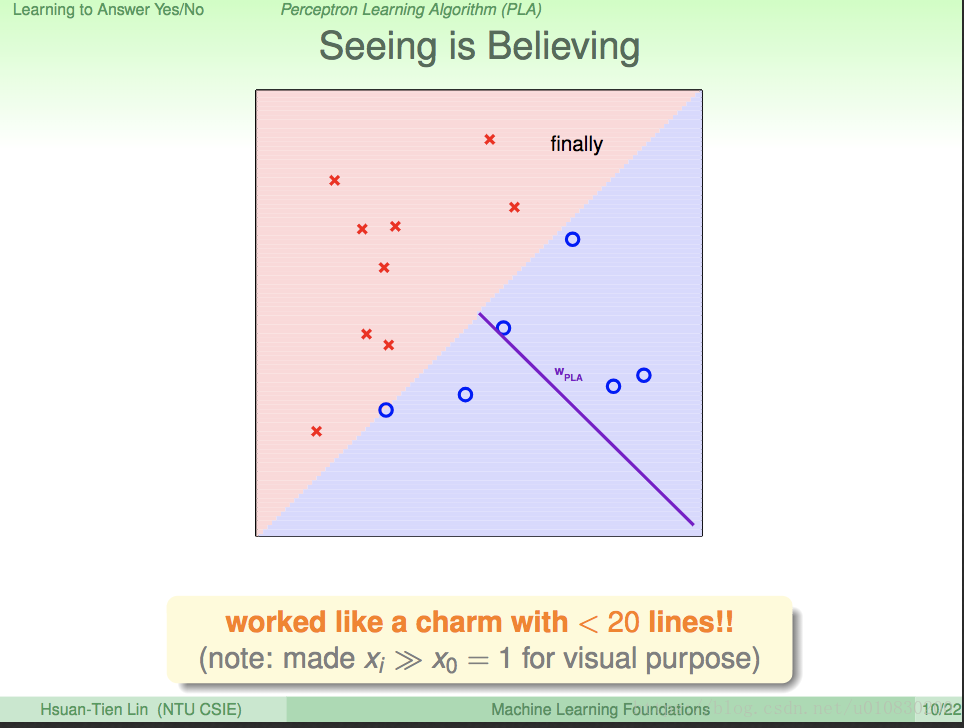
上述就是 寻找g 的整个过程。

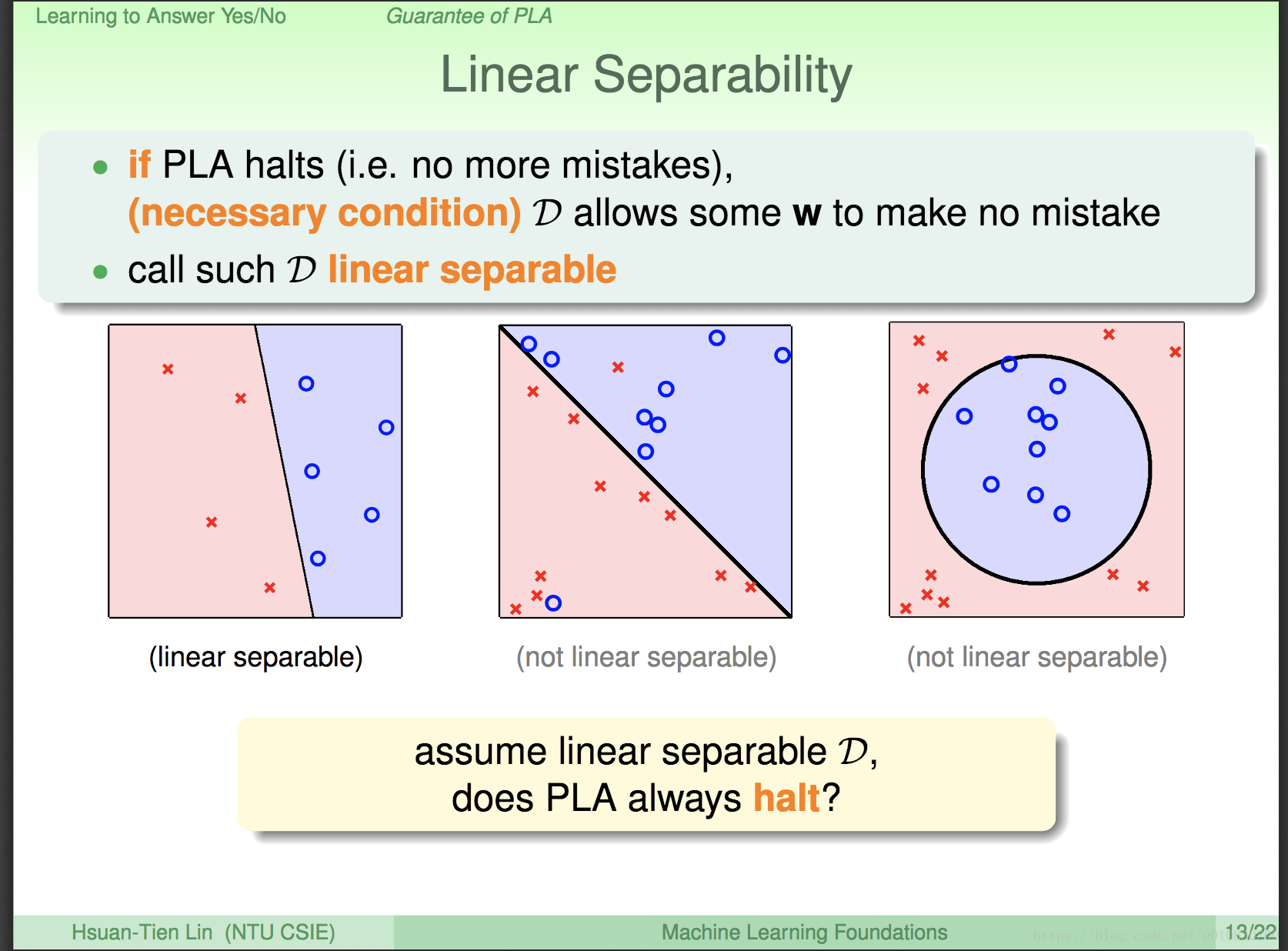
这里提出了一个问题,那就是 PLA(前面PPT有说) 是不是总能停止呢?
对于线性可分的 D,PLA 算法最终坑定会停止的,找出一个g; 但是我们并不知道 PLA 算法何时会停止。
而且,我们在拿到数据,运用PLA 之前,并不会知道 这个数据D 线性可分,如果知道线性可分,那我们就知道分类的模型了,所以,在拿到一个数据后,我们并不知道 PLA 算法最后会不会停止,何时停止。好烦恼。。。。。但是下面就会 一一解决这些问题。。。别急

以上不等式 结合前面所说,可以推导出来。
从上面可以看出 wf w t+1 > wf wt 说 前者内积大于 后者,由内积的集合意义,内积越大,方向上越相似,所以可以说 wt 在不断向 wf 靠近。。。但是,有没有可能是因为 w t+1 变大的缘故,而不是方向上原因呢,(wx = |w| * |x| * cos ) 所以现在并不确定。继续证明。。。。。



(借鉴别人的话)
上一章节的PLA算法都建立在数据线性可分的基础上。对于一堆复杂的数据,如何确定这个数据是不是线性可分的呢?比如一个PLA算法运行了很长时间仍然没有停止,此时存在两种可能性,一是该数据集是线性可分的,但是还没有运行结束;另一种,压根就不存在一条直线可以将数据集分开,就是压根这个算法就不会终止。假如是后者又该如何处理?
为什么会出现后者呢?这种情况出现的概率大吗?
出现不可分的一种可能是,从未知目标函数中产生的训练样本存在噪音(noise),如录入样本时,有人工的错误等情况导致数据本身不正确。噪音占整个数据集的比例一般不会太大。
假如数据非线性可能,此时PLA算法无效。我们假设噪音较小,yn基本上等于f(xn)。我们要找一条犯错最少的线g,即:
该算法没有完美的最优解,我们用口袋算法可以得到一个还不错的解。
Pocket Algorithm(口袋/贪心算法):
随机初始化向量权值(即任找一条线),
随机使用n个点去发现是否有错误;
如果发现错误,则利用PLA算法公式Wt+1 = wt + yn(t) Xn(t) 进行纠正
对比修正错误后的权值向量与修正前的权值向量,保留错误较少的。重复2、3、4步骤…
假如很久都没能找到更好的权值向量,则自动返回当前向量作为g值。
PLA与Pocket Algorithm区别:
口袋算法需要设定执行次数;随机查找错误的数据(而不是依次遍历)。缺点在于需要花力气去存储口袋里的东西,每查找一次,要将新的错误率与以前的错误率作比较。总之,口袋算法计算开销比较大。














 1343
1343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









