







文章主要提出了一种简单的可缩放的识别算法,在VOC 2012上达到了53.3%的mAP( mean average precision),相较于前面的最好结果30%有很大的提升。
主要集中在解决两个问题:
使用深度神经网络定位物体&&使用少量的标签数据训练模型
1. 定位问题有两种解决办法,一是将其当做回归问题来进行定位;二是建立滑动窗口进行定位(采用了第二种)
2. 小样本的问题通过非监督预训练,监督式微调的方式解决

RCNN主要结构是利用seletive search方法从中提取出候选框,采用CNN提取特征向量,再使用SVM进行分类。如下图所示

Object proposal transformations
为了使输入的包含物体的图像能作为CNN的有效输入,需要对其进行一定的缩放。这里提出了三种方法。
- tightest square with context
使用原图像的相关内容进行缩放 - tightest square without context
直接填充图像边界 - warp
各向异性地直接缩放原图像至CNN输入的大小

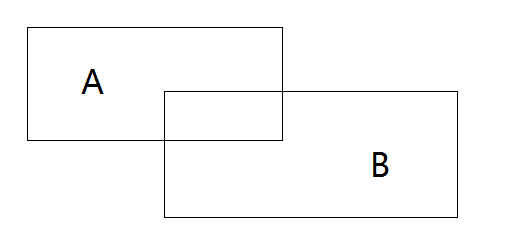
IOU
IOU是用于评价定位精度的指标,也就是
A、B
交并的面积之比。
IOU=(A∩B)/(A∪B)
Non-maximum Suppression
非极大值抑制主要用来寻找检测物体的最佳位置,由于使用滑动窗口会导致有同一个物体有多个框,NMS就是用来选择出最佳的那个框。















 6736
6736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









