







在普通的java程序中我们可以定义一个全局的静态变量,然后我们可以在各个类中去使用,实现累加器的功能,然而在mapruduce中怎么实现这一功能呢,各个map可能运行在不同的JVM中(这里不考虑JVM重用的情况),然而我们可以借助MapReduce提供的Counter功能来实现这一功能,下面我们通过一个实例来说明这一个用法。
实验要求:快速实现文件行数,以及其中错误记录的统计
实验数据:
1
2
error
3
4
5
error
6
7
8
9
10
error
11
12
13
14
error
15
16
17
18
19
解决思路:
定义一个枚举类型,每次调用map函数时,对值进行判断,把判断的结果分别写入不同的Counter,最后输出Counter的值
根据以上步骤下面是实现代码:
启动函数:
运行结果:
实验要求:快速实现文件行数,以及其中错误记录的统计
实验数据:
1
2
error
3
4
5
error
6
7
8
9
10
error
11
12
13
14
error
15
16
17
18
19
解决思路:
定义一个枚举类型,每次调用map函数时,对值进行判断,把判断的结果分别写入不同的Counter,最后输出Counter的值
根据以上步骤下面是实现代码:
map阶段:
- import java.io.IOException;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Mapper;
- public class MyMapper extends Mapper<LongWritable, Text, LongWritable, IntWritable> {
- /**
- * 定义一个枚举类型
- * @date 2016年3月25日 下午3:29:44
- * @{tags}
- */
- public static enum FileRecorder{
- ErrorRecorder,
- TotalRecorder
- }
- @Override
- protected void map(LongWritable key, Text value, Context context)
- throws IOException, InterruptedException {
- if("error".equals(value.toString())){
- /**
- * 把counter实现累加
- */
- context.getCounter(FileRecorder.ErrorRecorder).increment(1);
- }
- /**
- * 把counter实现累加
- */
- context.getCounter(FileRecorder.TotalRecorder).increment(1);
- }
- }
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import com.seven.mapreduce.counter.MyMapper.FileRecorder;
- public class JobMain {
- public static void main(String[] args) throws Exception {
- Configuration configuration = new Configuration();
- /**
- * 使NLineInputFormat来分割一个小文件,近而模拟分布式大文件的处理
- */
- configuration.setInt("mapreduce.input.lineinputformat.linespermap", 5);
- Job job = new Job(configuration, "counter-job");
- job.setInputFormatClass(NLineInputFormat.class);
- job.setJarByClass(JobMain.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(LongWritable.class);
- job.setMapOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(args[0]));
- Path outputDir = new Path(args[1]);
- FileSystem fs = FileSystem.get(configuration);
- if( fs.exists(outputDir)) {
- fs.delete(outputDir ,true);
- }
- FileOutputFormat.setOutputPath(job, outputDir);
- if(job.waitForCompletion(true) ? true: false) {
- System.out.println("Error num:" + job.getCounters().findCounter(FileRecorder.ErrorRecorder).getValue());
- System.out.println("Total num:" + job.getCounters().findCounter(FileRecorder.TotalRecorder).getValue());
- }
- }
- }
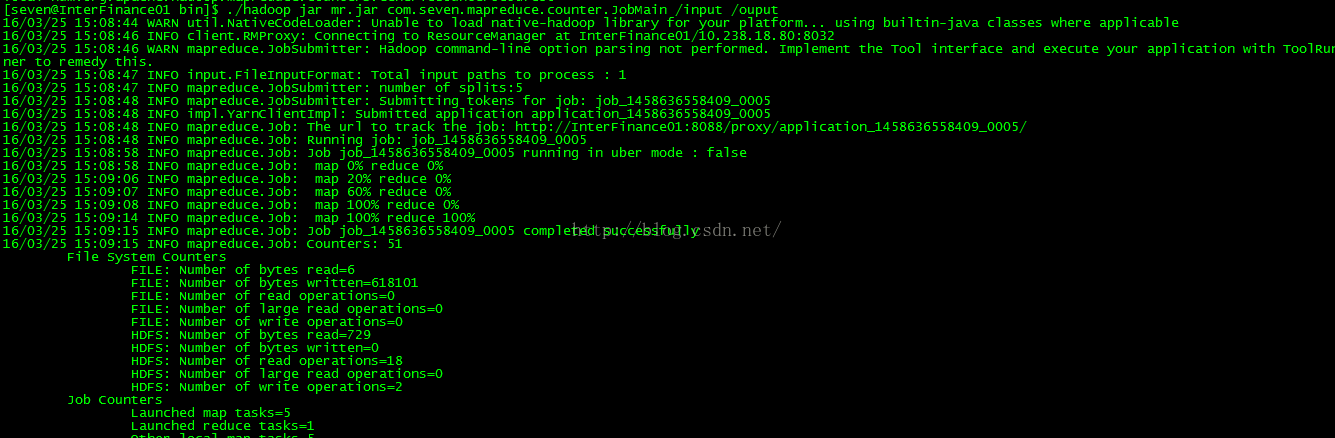
总结:
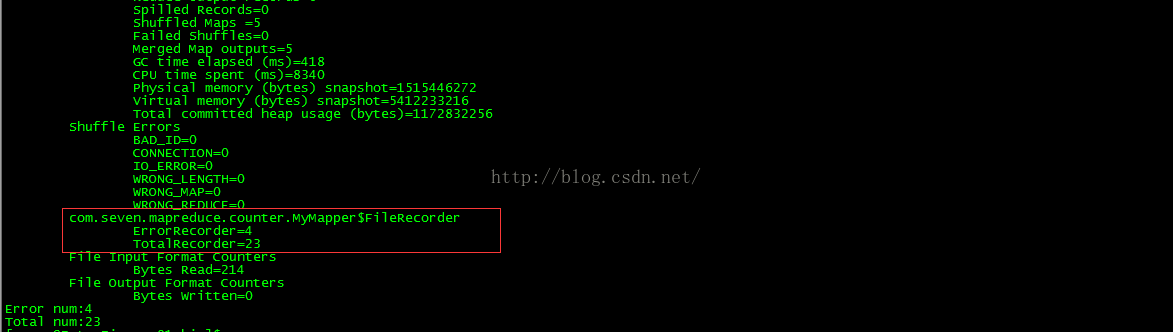
由上可以看出总共跑了5个map任务,而且通过Counter实现了不同JVM中的全局累加器的功能。关于除自定义Counter以外的其它Counter的含义
原文地址:http://blog.csdn.net/doegoo/article/details/50981196















 2584
2584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









