







这个算法研究了一天,从理论推导到C语言实现,作为初学者,还是不太容易,尤其很多资料对于next矩阵有的从0开始有的从1开始。作为初学者尤其是在具体实现是可能会搞混,但其实其本质是一样,首先需要理解算法的本质,然后再考虑形式上差异就会比较容易。
首先简单介绍朴素的模式匹配算法,然后详细介绍KMP算法。
朴素的模式匹配算法
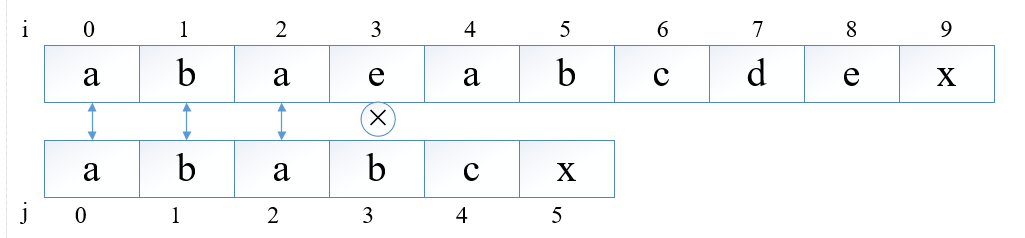
从两张图可以看出,朴素的匹配算法是在发现不完全匹配后,匹配字符串向后平移一个单位,继续匹配;不难发下i值在第一次匹配中走到3;发现不等,第二次匹配又从新从1开始;也就是说i值发生了回溯。
对于本图中的匹配字符串可以发现,ababcx中存在重复的字符;所以在第一次匹配发现i=3与j=3处的值不相等,此时由于j=0处的值和j=1处的值不相等,但是j=1处的值与i=1处的值相等,所以j=0与i=1处的值一定不相等,所以第二次的匹配是多余的,为了进一步提高匹配效率,伟大的前人提出了KMP算法。
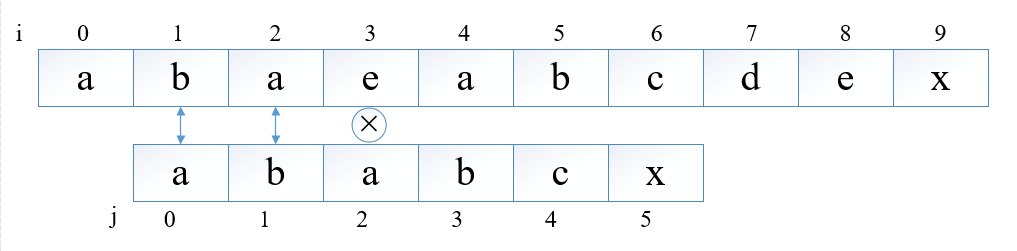
KMP算法
从上图中可以看出,有效的匹配应该是从j=0与i=2处对其开始匹配,但是由于j=0与j=2处的值是相等的,所以该位不用匹配,从j=1,i=3开始匹配
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









