







集合和数组的区别
- 数组的长度是固定的。集合的长度是可变的。
- 数组中存储的是同一类型的元素,可以存储基本数据类型值,也可以是引用类型,集合存储的都是对象(引用类型)。而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储。
//数组
int[] arr = new int[10];
Student[] arr = new Student[3];
//集合
Arraylist<Integer> a= new Arraylist<>();集合
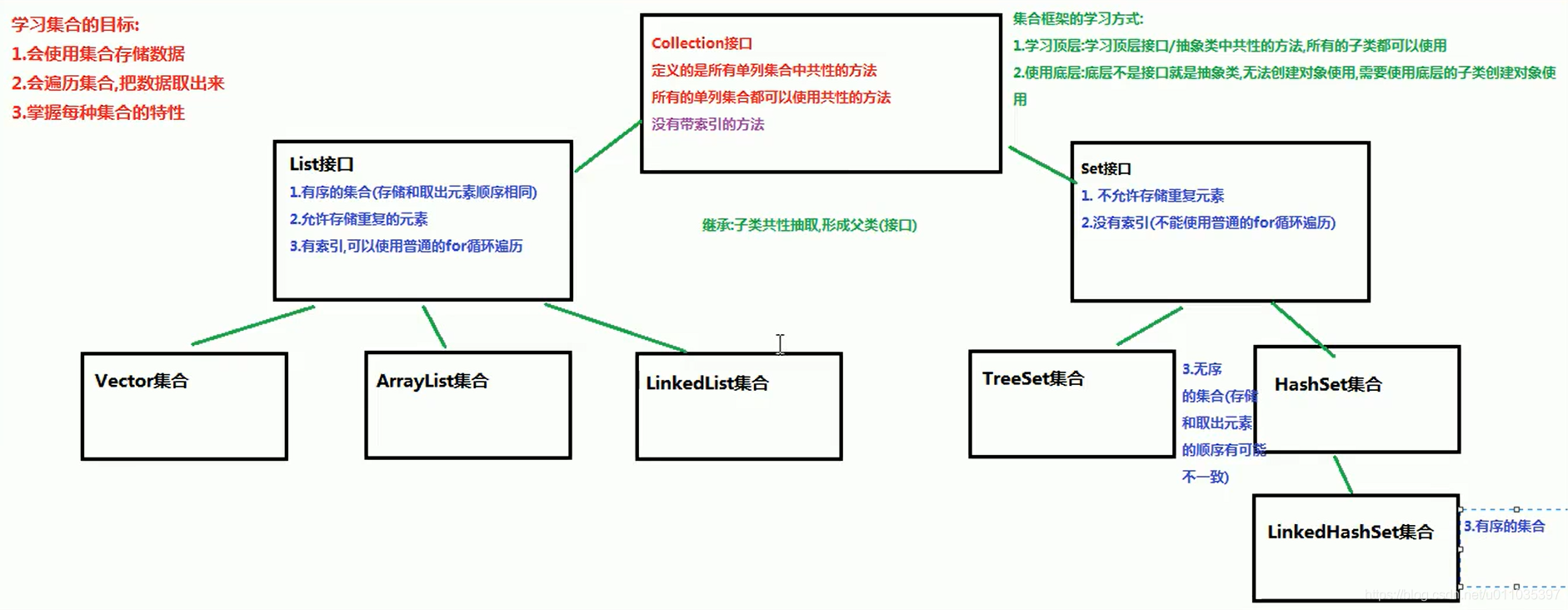
Collection集合
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
/*
java.util.Collection接口
所有单列集合的最顶层的接口,里边定义了所有单列集合共性的方法
任意的单列集合都可以使用Collection接口中的方法
共性的方法:
public boolean add(E e): 把给定的对象添加到当前集合中 。
public void clear() :清空集合中所有的元素。
public boolean remove(E e): 把给定的对象在当前集合中删除。
public boolean contains(E e): 判断当前集合中是否包含给定的对象。
public boolean isEmpty(): 判断当前集合是否为空。
public int size(): 返回集合中元素的个数。
public Object[] toArray(): 把集合中的元素,存储到数组中。
*/
public class Demo01Collection {
public static void main(String[] args) {
//创建集合对象,可以使用多态
//Collection<String> coll = new ArrayList<>();
Collection<String> coll = new HashSet<>();
System.out.println(coll);//重写了toString方法 []
/*
public boolean add(E e): 把给定的对象添加到当前集合中 。
返回值是一个boolean值,一般都返回true,所以可以不用接收
*/
boolean b1 = coll.add("张三");
System.out.println("b1:"+b1);//b1:true
System.out.println(coll);//[张三]
coll.add("李四");
coll.add("李四");
coll.add("赵六");
coll.add("田七");
System.out.println(coll);//[张三, 李四, 赵六, 田七]
/*
public boolean remove(E e): 把给定的对象在当前集合中删除。
返回值是一个boolean值,集合中存在元素,删除元素,返回true
集合中不存在元素,删除失败,返回false
*/
boolean b2 = coll.remove("赵六");
System.out.println("b2:"+b2);//b2:true
boolean b3 = coll.remove("赵四");
System.out.println("b3:"+b3);//b3:false
System.out.println(coll);//[张三, 李四, 田七]
/*
public boolean contains(E e): 判断当前集合中是否包含给定的对象。
包含返回true
不包含返回false
*/
boolean b4 = coll.contains("李四");
System.out.println("b4:"+b4);//b4:true
boolean b5 = coll.contains("赵四");
System.out.println("b5:"+b5);//b5:false
//public boolean isEmpty(): 判断当前集合是否为空。 集合为空返回true,集合不为空返回false
boolean b6 = coll.isEmpty();
System.out.println("b6:"+b6);//b6:false
//public int size(): 返回集合中元素的个数。
int size = coll.size();
System.out.println("size:"+size);//size:3
//public Object[] toArray(): 把集合中的元素,存储到数组中。
Object[] arr = coll.toArray();
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
//public void clear() :清空集合中所有的元素。但是不删除集合,集合还存在
coll.clear();
System.out.println(coll);//[]
System.out.println(coll.isEmpty());//true
}
}
迭代器
Set集合没有索引,不能用for循环进行取值,所以需要使用迭代器
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
java.util.Iterator接口:迭代器(对集合进行遍历)
有两个常用的方法
boolean hasNext() 如果仍有元素可以迭代,则返回 true。
判断集合中还有没有下一个元素,有就返回true,没有就返回false
E next() 返回迭代的下一个元素。
取出集合中的下一个元素
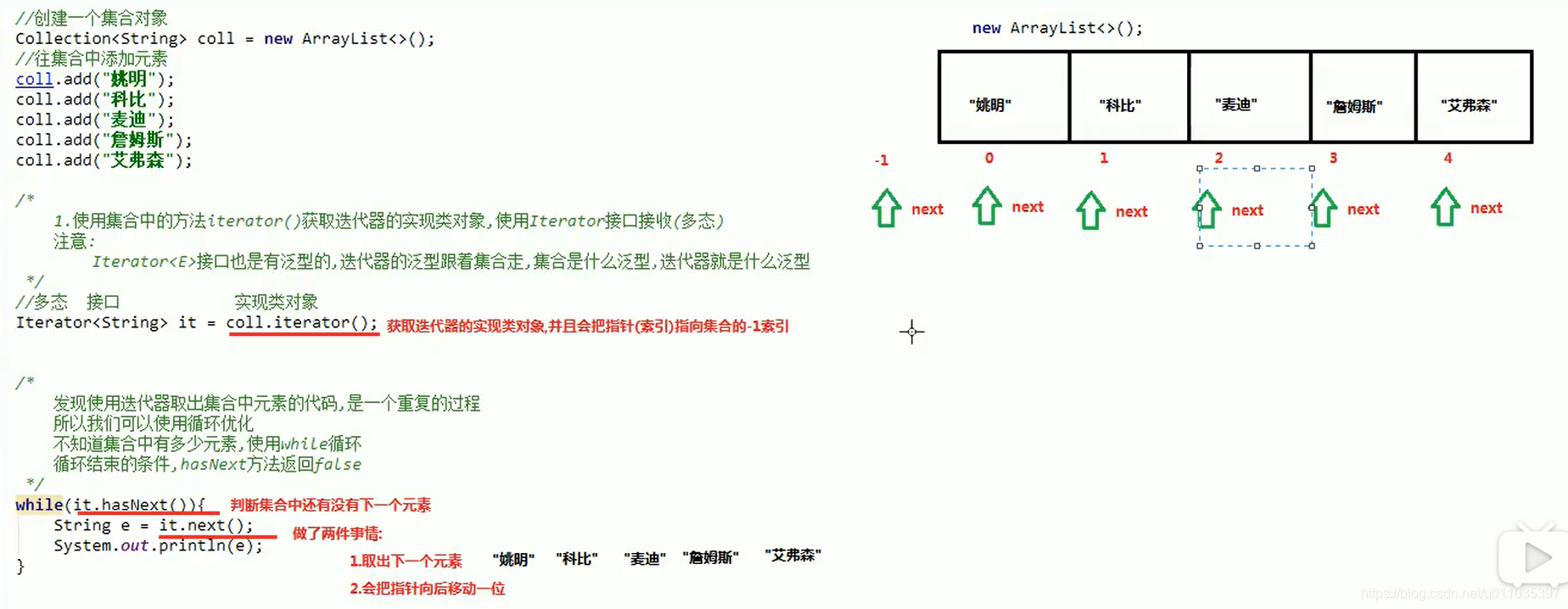
Iterator迭代器,是一个接口,我们无法直接使用,需要使用Iterator接口的实现类对象,获取实现类的方式比较特殊
Collection接口中有一个方法,叫iterator(),这个方法返回的就是迭代器的实现类对象
Iterator<E> iterator() 返回在此 collection 的元素上进行迭代的迭代器。
迭代器的使用步骤(重点):
1.使用集合中的方法iterator()获取迭代器的实现类对象,使用Iterator接口接收(多态)
2.使用Iterator接口中的方法hasNext判断还有没有下一个元素
3.使用Iterator接口中的方法next取出集合中的下一个元素
*/
public class Demo01Iterator {
public static void main(String[] args) {
//创建一个集合对象
Collection<String> coll = new ArrayList<>();
//往集合中添加元素
coll.add("姚明");
coll.add("科比");
coll.add("麦迪");
coll.add("詹姆斯");
coll.add("艾弗森");
/*
1.使用集合中的方法iterator()获取迭代器的实现类对象,使用Iterator接口接收(多态)
注意:
Iterator<E>接口也是有泛型的,迭代器的泛型跟着集合走,集合是什么泛型,迭代器就是什么泛型
*/
//多态 接口 实现类对象
Iterator<String> it = coll.iterator();
/*
发现使用迭代器取出集合中元素的代码,是一个重复的过程
所以我们可以使用循环优化
不知道集合中有多少元素,使用while循环
循环结束的条件,hasNext方法返回false
*/
while(it.hasNext()){
String e = it.next();
System.out.println(e);
}
System.out.println("----------------------");
for(Iterator<String> it2 = coll.iterator();it2.hasNext();){
String e = it2.next();
System.out.println(e);
}
/* //2.使用Iterator接口中的方法hasNext判断还有没有下一个元素
boolean b = it.hasNext();
System.out.println(b);//true
//3.使用Iterator接口中的方法next取出集合中的下一个元素
String s = it.next();
System.out.println(s);//姚明
b = it.hasNext();
System.out.println(b);
s = it.next();
System.out.println(s);
b = it.hasNext();
System.out.println(b);
s = it.next();
System.out.println(s);
b = it.hasNext();
System.out.println(b);
s = it.next();
System.out.println(s);
b = it.hasNext();
System.out.println(b);
s = it.next();
System.out.println(s);
b = it.hasNext();
System.out.println(b);//没有元素,返回false
s = it.next();//没有元素,在取出元素会抛出NoSuchElementException没有元素异常
System.out.println(s);*/
}
}
迭代器实现原理
增强for循环
import java.util.ArrayList;
/*
增强for循环:底层使用的也是迭代器,使用for循环的格式,简化了迭代器的书写
是JDK1.5之后出现的新特性
Collection<E>extends Iterable<E>:所有的单列集合都可以使用增强for
public interface Iterable<T>实现这个接口允许对象成为 "foreach" 语句的目标。
增强for循环:用来遍历集合和数组
格式:
for(集合/数组的数据类型 变量名: 集合名/数组名){
sout(变量名);
}
*/
public class Demo02Foreach {
public static void main(String[] args) {
demo02();
}
//使用增强for循环遍历集合
private static void demo02() {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
for(String s : list){
System.out.println(s);
}
}
//使用增强for循环遍历数组
private static void demo01() {
int[] arr = {1,2,3,4,5};
for(int i:arr){
System.out.println(i);
}
}
}TreeSet和HashSet的区别
TreeSet和HashSet是无序的,这里的序指的是数据插入的顺序
但TreeSet当中的数据是自动排序好的
在java中我们通常说的集合有序无序针对的是插入顺序,是指在插入元素时,插入的顺序是否保持,当遍历集合时它是否会按照插入顺序展示。像TreeSet和TreeMap这样的集合主要实现了自动排序,我们称之为排序,而根据前面的定义它不一定是有序的。所以,在我们常见的集合类型中,有序的有ArrayList,LinkedList,LinkedHashSet,LinkedHashMap等,无序的有HashSet,HashMap,HashTable,TreeSet,TreeMap等,而同时TressSet和TressMap又是可排序的。我们有时候会听到一种笼统的说法,认为List是有序的,Set和Map是无序的,其实不然,在Set和Map中也有通过双向链表来实现有序的LinkedHashSet和LinkedHashMap。
Set中元素不可以重复,是无序的(这里无序是指存入元素的先后顺序与输出元素的先后顺序不一致)
HashSet:内部的数据结构是哈希表,是线程不安全的。
HashSet中保证集合中元素是唯一的方法:通过对象的hashCode和equals方法来完成对象唯一性的判断。
如果对象的hashCode值不同,则不用判断equals方法,就直接存到HashSet中。
如果对象的hashCode值相同,需要用equals方法进行比较,如果结果为true,则视为相同元素,不存,如果结果为false,视为不同元素,进行存储。
注意:如果元素要存储到HashCode中,必须覆盖hashCode方法和equals方法。
TreeSet:可以对Set集合中的元素进行排序,是线程不安全的。底层结构是红黑树
TreeSet中判断元素唯一性的方法是:根据比较方法的返回结果是否为0,如果是0,则是相同元素,不存,如果不是0,则是不同元素,存储。
TreeSet对元素进行排序的方式:
元素自身具备比较功能,即自然排序,需要实现Comparable接口,并覆盖其compareTo方法。
元素自身不具备比较功能,则需要实现Comparator接口,并覆盖其compare方法。
注意:LinkedHashSet是一种有序的Set集合,即其元素的存入和输出的顺序是相同的。
https://www.cnblogs.com/cxfly/p/10540959.html
https://blog.csdn.net/coding_1994/article/details/80553554















 2320
2320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











