







BitSet
2015.04.18 - 19
By 970655147
备注 : “[” 和”]”之间的内容是 我添加的
此类实现了一个按需增长的位向量。bitset 的每个组件都有一个 boolean 值。用非负的整数将 BitSet 的位编入索引。[1]可以对每个编入索引的位进行测试、设置或者清除。 [2]通过逻辑与、逻辑或和逻辑异或操作,可以使用一个 BitSet 修改另一个 BitSet 的内容。
默认情况下,set 中所有位的初始值都是 false。
每个位 set 都有一个当前大小,也就是该位 set 当前所用空间的位数。注意,这个大小与位 set 的实现有关,所以它可能随实现的不同而更改。位 set 的长度与位 set 的逻辑长度有关,并且是与实现无关而定义的。
除非另行说明,否则将 null 参数传递给 BitSet 中的任何方法都将导致 NullPointerException。
在没有外部同步的情况下,多个线程操作一个 BitSet 是不安全的。
start ->
声明
/**
* This class implements a vector of bits that grows as needed. Each
* component of the bit set has a {@code boolean} value. The
* bits of a {@code BitSet} are indexed by nonnegative integers.
* Individual indexed bits can be examined, set, or cleared. One
* {@code BitSet} may be used to modify the contents of another
* {@code BitSet} through logical AND, logical inclusive OR, and
* logical exclusive OR operations.
*
* <p>By default, all bits in the set initially have the value
* {@code false}.
*
* <p>Every bit set has a current size, which is the number of bits
* of space currently in use by the bit set. Note that the size is
* related to the implementation of a bit set, so it may change with
* implementation. The length of a bit set relates to logical length
* of a bit set and is defined independently of implementation.
*
* <p>Unless otherwise noted, passing a null parameter to any of the
* methods in a {@code BitSet} will result in a
* {@code NullPointerException}.
*
* <p>A {@code BitSet} is not safe for multithreaded use without
* external synchronization.
*
* @author Arthur van Hoff
* @author Michael McCloskey
* @author Martin Buchholz
* @since JDK1.0
*/
public class BitSet implements Cloneable, java.io.Serializable
BitSet. 属性
sizeIsSticky 上面的这段注释对于理解其作用非常关键
// 计算给定的bitIdx对应的long的索引, 每一个long存放的数据的个数
// 计算bitIdx在对应的long位置索引, -1
private final static int ADDRESS_BITS_PER_WORD = 6;
private final static int BITS_PER_WORD = 1 << ADDRESS_BITS_PER_WORD;
private final static int BIT_INDEX_MASK = BITS_PER_WORD - 1;
private static final long WORD_MASK = 0xffffffffffffffffL;
// 存放数据, 当前使用的long的个数[每一次对于当前集合进行更新之后, 会重新计算wordInUse], 是否容量固定[假设], 序列化id
private long[] words;
private transient int wordsInUse = 0;
/**
* Whether the size of "words" is user-specified. If so, we assume
* the user knows what he's doing and try harder to preserve it.
*/
private transient boolean sizeIsSticky = false;
private static final long serialVersionUID = 7997698588986878753L;
BitSet. BitSet()
public BitSet() {
initWords(BITS_PER_WORD);
sizeIsSticky = false;
}
BitSet. initWords(int nbits)
private void initWords(int nbits) {
// 创建能够包含nBits个位的long数组
words = new long[wordIndex(nbits-1) + 1];
}
BitSet. wordIndex(int bitIndex)
private static int wordIndex(int bitIndex) {
// 相当于除以64, 返回bitIndex在的数组[words]中的索引
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
private final static int ADDRESS_BITS_PER_WORD = 6;
BitSet. BitSet(int nbits)
public BitSet(int nbits) {
// nbits can't be negative; size 0 is OK
if (nbits < 0)
throw new NegativeArraySizeException("nbits < 0: " + nbits);
initWords(nbits);
sizeIsSticky = true;
}
BitSet. valueOf(long[] longs)
public static BitSet valueOf(long[] longs) {
// 统计longs中最后一个非0的long的索引 然后构造一个BitSet
int n;
for (n = longs.length; n > 0 && longs[n - 1] == 0; n--)
;
return new BitSet(Arrays.copyOf(longs, n));
}
Arrays. copyOf(long[] original, int newLength)
public static long[] copyOf(long[] original, int newLength) {
// 复制original的前n个数据 到copy中
long[] copy = new long[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
BitSet. BitSet(long[] words)
private BitSet(long[] words) {
// 设置words 并校验
this.words = words;
this.wordsInUse = words.length;
checkInvariants();
}
BitSet. checkInvariants()
private void checkInvariants() {
assert(wordsInUse == 0 || words[wordsInUse - 1] != 0);
assert(wordsInUse >= 0 && wordsInUse <= words.length);
assert(wordsInUse == words.length || words[wordsInUse] == 0);
}
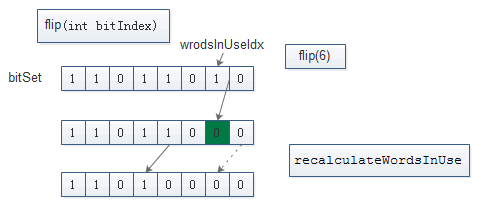
BitSet.flip(int bitIndex)
public void flip(int bitIndex) {
// 将bitIndex处的值 设置为其补码
// 获取该bitIndex所在words中的索引 确保存在wordIndex个数组长度
// 将bitIndex出的数据 设置为原来数据的补码[这里操作为0 -> 1, 1 –> 0]
// 重新计算wordsInUse 并校验
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] ^= (1L << bitIndex);
recalculateWordsInUse();
checkInvariants();
}
BitSet. expandTo(int wordIndex)
private void expandTo(int wordIndex) {
// 如果空间不够 扩容
int wordsRequired = wordIndex+1;
if (wordsInUse < wordsRequired) {
ensureCapacity(wordsRequired);
wordsInUse = wordsRequired;
}
}
BitSet. ensureCapacity(int wordsRequired)
private void ensureCapacity(int wordsRequired) {
if (words.length < wordsRequired) {
// Allocate larger of doubled size or required size
// 扩容算法为 选取words长度的2倍 和 wordsRequired中的较大者
// 并复制words中的数据[一般来说是2倍扩容]
// 并修改sizeIsSticky [用于优化]
int request = Math.max(2 * words.length, wordsRequired);
words = Arrays.copyOf(words, request);
sizeIsSticky = false;
}
}
BitSet. recalculateWordsInUse()
private void recalculateWordsInUse() {
// Traverse the bitset until a used word is found
int i;
// 从wordsInUse开始计算 (选取最后一个一个不为0的long的索引 + 1) 为wordsInUse
for (i = wordsInUse-1; i >= 0; i--)
if (words[i] != 0)
break;
wordsInUse = i+1; // The new logical size
}
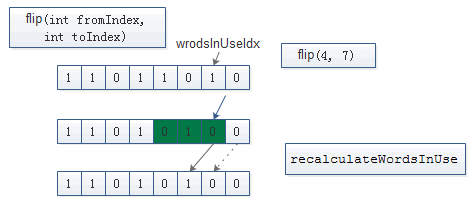
BitSet. flip(int fromIndex, int toIndex)
public void flip(int fromIndex, int toIndex) {
checkRange(fromIndex, toIndex);
if (fromIndex == toIndex)
return;
// 获取fromIndex, toIndex对应words中的索引 并进行扩容
// 获取fromIndex, lastIndex对应long的mask
// 如果fromIndex和toIndex所在的words中的索引相同 words[startWordIndex] 异或上 (firstMask &lastMask)
// 否则处理formIndex所在的long, toIndex所在的long 以及其之间的long
// 重新计算wordInUse 并校验
int startWordIndex = wordIndex(fromIndex);
int endWordIndex = wordIndex(toIndex - 1);
expandTo(endWordIndex);
// 下面的算法没有怎么懂起..?? --2015.04.18
// 哦 原来右边的为低位啊,,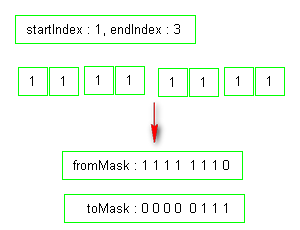
long firstWordMask = WORD_MASK << fromIndex;
long lastWordMask = WORD_MASK >>> -toIndex;
if (startWordIndex == endWordIndex) {
// Case 1: One word
words[startWordIndex] ^= (firstWordMask & lastWordMask);
} else {
// Case 2: Multiple words
// Handle first word
words[startWordIndex] ^= firstWordMask;
// Handle intermediate words, if any
for (int i = startWordIndex+1; i < endWordIndex; i++)
words[i] ^= WORD_MASK;
// Handle last word
words[endWordIndex] ^= lastWordMask;
}
recalculateWordsInUse();
checkInvariants();
}
BitSet. checkRange(int fromIndex, int toIndex)
private static void checkRange(int fromIndex, int toIndex) {
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex < 0: " + fromIndex);
if (toIndex < 0)
throw new IndexOutOfBoundsException("toIndex < 0: " + toIndex);
if (fromIndex > toIndex)
throw new IndexOutOfBoundsException("fromIndex: " + fromIndex +
" > toIndex: " + toIndex);
}
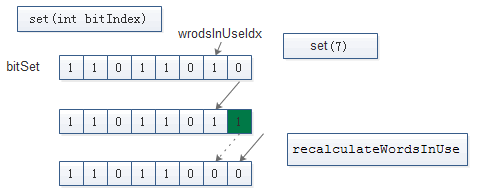
BitSet. set(int bitIndex)
public void set(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
// 获取bitIndex对应的words中的索引
// 将bitIndex处的值 更新为1
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] |= (1L << bitIndex); // Restores invariants
checkInvariants();
}
BitSet. set(int bitIndex, boolean value)
public void set(int bitIndex, boolean value) {
if (value)
set(bitIndex);
else
clear(bitIndex);
}
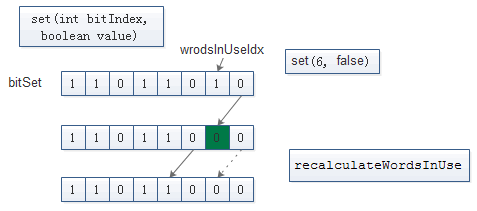
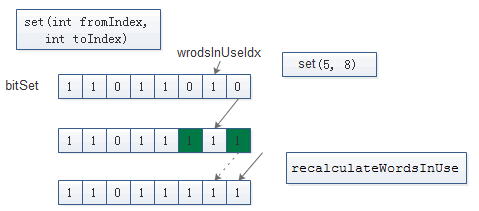
BitSet. set(int fromIndex, int toIndex)
public void set(int fromIndex, int toIndex) {
checkRange(fromIndex, toIndex);
if (fromIndex == toIndex)
return;
// Increase capacity if necessary
// 获取fromIndex, endIndex对应words中的索引
// 获取firstWordIndex, endWordIndex
// 如果fromIndex, endIndex对应words中的索引相同 处理words[startWordIndex]
// 否则 处理words[startWordIndex], 设置的fromIndex到当前long末尾的位为1, words[endWordIndex]的前endIndex个位为1, startWordIndex到endWordIndex之间的long所有的数据位为1
// 校验 int startWordIndex = wordIndex(fromIndex);
int endWordIndex = wordIndex(toIndex - 1);
expandTo(endWordIndex);
long firstWordMask = WORD_MASK << fromIndex;
long lastWordMask = WORD_MASK >>> -toIndex;
if (startWordIndex == endWordIndex) {
// Case 1: One word
words[startWordIndex] |= (firstWordMask & lastWordMask);
} else {
// Case 2: Multiple words
// Handle first word
words[startWordIndex] |= firstWordMask;
// Handle intermediate words, if any
for (int i = startWordIndex+1; i < endWordIndex; i++)
words[i] = WORD_MASK;
// Handle last word (restores invariants)
words[endWordIndex] |= lastWordMask;
}
checkInvariants();
}
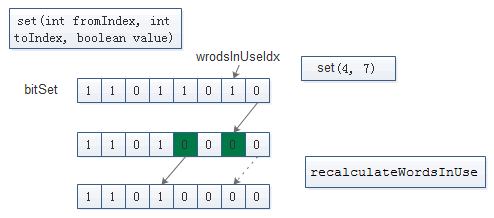
BitSet. set(int fromIndex, int toIndex, boolean value)
public void set(int fromIndex, int toIndex, boolean value) {
if (value)
set(fromIndex, toIndex);
else
clear(fromIndex, toIndex);
}
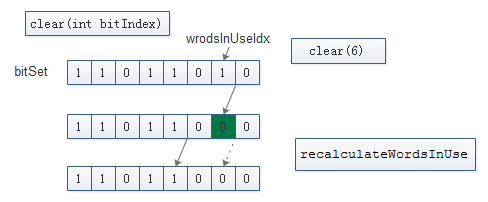
BitSet. clear(int bitIndex)
public void clear(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
// 获取bitIndex对应的words中的索引
// 将bitIndex出的数据 置为0
// 重新计算wordInUse 校验
int wordIndex = wordIndex(bitIndex);
if (wordIndex >= wordsInUse)
return;
words[wordIndex] &= ~(1L << bitIndex);
recalculateWordsInUse();
checkInvariants();
}
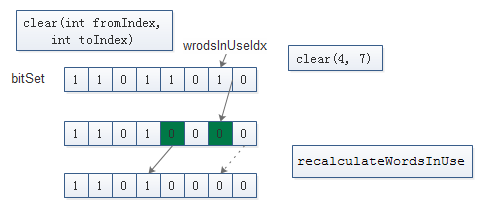
BitSet. clear(int fromIndex, int toIndex)
// 这个方法和上面的set(int fromIndex, int endIndex) 基本相同 [多了一个recalculateWordsInUse, 因为更新了数据结构]
public void clear(int fromIndex, int toIndex) {
checkRange(fromIndex, toIndex);
if (fromIndex == toIndex)
return;
int startWordIndex = wordIndex(fromIndex);
if (startWordIndex >= wordsInUse)
return;
int endWordIndex = wordIndex(toIndex - 1);
if (endWordIndex >= wordsInUse) {
toIndex = length();
endWordIndex = wordsInUse - 1;
}
long firstWordMask = WORD_MASK << fromIndex;
long lastWordMask = WORD_MASK >>> -toIndex;
if (startWordIndex == endWordIndex) {
// Case 1: One word
words[startWordIndex] &= ~(firstWordMask & lastWordMask);
} else {
// Case 2: Multiple words
// Handle first word
words[startWordIndex] &= ~firstWordMask;
// Handle intermediate words, if any
for (int i = startWordIndex+1; i < endWordIndex; i++)
words[i] = 0;
// Handle last word
words[endWordIndex] &= ~lastWordMask;
}
recalculateWordsInUse();
checkInvariants();
}
BitSet. get(int bitIndex)
public boolean get(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
// 校验
// 获取bitIndex对应words中的索引
// 获取bitIndex处的值 是否为1
checkInvariants();
int wordIndex = wordIndex(bitIndex);
return (wordIndex < wordsInUse)
&& ((words[wordIndex] & (1L << bitIndex)) != 0);
}
BitSet. get(int fromIndex, int toIndex)
public BitSet get(int fromIndex, int toIndex) {
// 校验fromIdx, toIdx
// 获取当前BitSet所有的值的个数
// 如果toIndex大于所有的1的个数 令toIndex为所有合理的值的个数
// 创建result
// 计算需要的fromIndex到toIndex需要的long的个数, fromIndex对应words的索引, wordAligned表示fromIndex是否为0
// 处理除了最后一个long的数据
// 处理最后一个long
// 计算result的wordInUse 校验result
checkRange(fromIndex, toIndex);
checkInvariants();
int len = length();
// If no set bits in range return empty bitset
if (len <= fromIndex || fromIndex == toIndex)
return new BitSet(0);
// An optimization
if (toIndex > len)
toIndex = len;
BitSet result = new BitSet(toIndex - fromIndex);
int targetWords = wordIndex(toIndex - fromIndex - 1) + 1;
int sourceIndex = wordIndex(fromIndex);
boolean wordAligned = ((fromIndex & BIT_INDEX_MASK) == 0);
// Process all words but the last word
for (int i = 0; i < targetWords - 1; i++, sourceIndex++)
result.words[i] = wordAligned ? words[sourceIndex] :
(words[sourceIndex] >>> fromIndex) |
(words[sourceIndex+1] << -fromIndex);
// Process the last word
long lastWordMask = WORD_MASK >>> -toIndex;
result.words[targetWords - 1] =
((toIndex-1) & BIT_INDEX_MASK) < (fromIndex & BIT_INDEX_MASK)
? /* straddles source words */
((words[sourceIndex] >>> fromIndex) |
(words[sourceIndex+1] & lastWordMask) << -fromIndex)
:
((words[sourceIndex] & lastWordMask) >>> fromIndex);
// Set wordsInUse correctly
result.wordsInUse = targetWords;
result.recalculateWordsInUse();
result.checkInvariants();
return result;
}
BitSet. nextSetBit(int fromIndex)
public int nextSetBit(int fromIndex) {
// 返回fromIndex之后的下一个1的索引
// 校验合法性
// 获取fromIndex对应words中的索引
// 获取fromIndex之后的数据[u中fromIndex之后的数据]
// 如果word不为0 表示word中存在1 返回u * 64 + word尾部的0[低位的0]
// 否则如果word == wordsInUse 表示遍历完了
// 否则继续遍历
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex < 0: " + fromIndex);
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return -1;
long word = words[u] & (WORD_MASK << fromIndex);
while (true) {
if (word != 0)
return (u * BITS_PER_WORD) + Long.numberOfTrailingZeros(word);
if (++u == wordsInUse)
return -1;
word = words[u];
}
}
BitSet. nextClearBit(int fromIndex)
public int nextClearBit(int fromIndex) {
// Neither spec nor implementation handle bitsets of maximal length.
// See 4816253.
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex < 0: " + fromIndex);
// 与nextSetBit类似, 不过注意 获取word的获取方式
// 取fromIndex所在long的fromIndex之后的数据 并取非[0 -> 1, 1 -> 0]
// 然后找到第一个1 <=> [取非之前的第一个0]
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return fromIndex;
long word = ~words[u] & (WORD_MASK << fromIndex);
while (true) {
if (word != 0)
return (u * BITS_PER_WORD) + Long.numberOfTrailingZeros(word);
if (++u == wordsInUse)
return wordsInUse * BITS_PER_WORD;
word = ~words[u];
}
}
BitSet. previousSetBit(int fromIndex)
public int previousSetBit(int fromIndex) {
// 逻辑和上面的nextSetBit方法的逻辑基本一致 不过是向前遍历, 去偏移的时候 取得是该word的前面的0
if (fromIndex < 0) {
if (fromIndex == -1)
return -1;
throw new IndexOutOfBoundsException(
"fromIndex < -1: " + fromIndex);
}
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return length() - 1;
long word = words[u] & (WORD_MASK >>> -(fromIndex+1));
while (true) {
if (word != 0)
return (u+1) * BITS_PER_WORD - 1 - Long.numberOfLeadingZeros(word);
if (u-- == 0)
return -1;
word = words[u];
}
}
BitSet. previousClearBit(int fromIndex)
public int previousClearBit(int fromIndex) {
// 逻辑和上面的nextClearBit方法的逻辑基本一致 不过是向前遍历, 去偏移的时候 取得是该word的前面的0
if (fromIndex < 0) {
if (fromIndex == -1)
return -1;
throw new IndexOutOfBoundsException(
"fromIndex < -1: " + fromIndex);
}
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return fromIndex;
long word = ~words[u] & (WORD_MASK >>> -(fromIndex+1));
while (true) {
if (word != 0)
return (u+1) * BITS_PER_WORD -1 - Long.numberOfLeadingZeros(word);
if (u-- == 0)
return -1;
word = ~words[u];
}
}
BitSet. valueOf(LongBuffer lb)
public static BitSet valueOf(LongBuffer lb) {
// 创建一个共享lb的数据的LongBuffer 清空标记
// 从最后一个元素开始遍历 n为最后一个不为0的元素
// 获取words lb中0 ~ n的数据 并根据words创建BitSet
lb = lb.slice();
int n;
for (n = lb.remaining(); n > 0 && lb.get(n - 1) == 0; n--)
;
long[] words = new long[n];
lb.get(words);
return new BitSet(words);
}
LongBuffer. get(long[] dst)
public LongBuffer get(long[] dst) {
return get(dst, 0, dst.length);
}
LongBuffer. get(long[] dst, int offset, int length)
public LongBuffer get(long[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
// 如果length大于剩余的数据 抛出异常
// 否则 获取数据到dst offset偏移的length个long
if (length > remaining())
throw new BufferUnderflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
dst[i] = get();
return this;
}
Buffer. checkBounds(int off, int len, int size)
static void checkBounds(int off, int len, int size) { // package-private
if ((off | len | (off + len) | (size - (off + len))) < 0)
throw new IndexOutOfBoundsException();
}
BitSet. valueOf(byte[] bytes)
public static BitSet valueOf(byte[] bytes) {
return BitSet.valueOf(ByteBuffer.wrap(bytes));
}
BitSet. valueOf(ByteBuffer bb)
public static BitSet valueOf(ByteBuffer bb) {
// 创建一个bb对应的副本 并清空标记
// 获取最后一个非0 的数据的索引
// 获取bb中的数据直到bb.remainning < 8 通过getLong的方式 传输快点
// 获取剩余的数据到words[i]中 获取剩余的字节
// 根据words创建BitSet
bb = bb.slice().order(ByteOrder.LITTLE_ENDIAN);
int n;
for (n = bb.remaining(); n > 0 && bb.get(n - 1) == 0; n--)
;
long[] words = new long[(n + 7) / 8];
bb.limit(n);
int i = 0;
while (bb.remaining() >= 8)
words[i++] = bb.getLong();
for (int remaining = bb.remaining(), j = 0; j < remaining; j++)
words[i] |= (bb.get() & 0xffL) << (8 * j);
return new BitSet(words);
}
BitSet. intersects(BitSet set)
public boolean intersects(BitSet set) {
// 判断当前bitSet和给定的bitSet是否存在某一位均为1
for (int i = Math.min(wordsInUse, set.wordsInUse) - 1; i >= 0; i--)
if ((words[i] & set.words[i]) != 0)
return true;
return false;
}
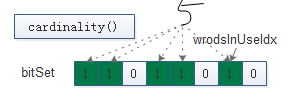
BitSet. cardinality()
public int cardinality() {
// 统计当前bitSet总共有多少给位为1
int sum = 0;
for (int i = 0; i < wordsInUse; i++)
sum += Long.bitCount(words[i]);
return sum;
}
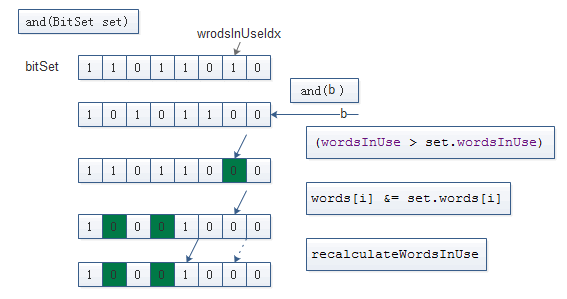
BitSet. and(BitSet set)
public void and(BitSet set) {
if (this == set)
return;
// 如果当前bitSet的wordsInUse比给定的bitSet的wordsInUse大 清空set. wordsInUse之后的位
// 对0 ~ wordsInUse之间的位 进行&操作
// 重新计算wordsInUse 校验
while (wordsInUse > set.wordsInUse)
words[--wordsInUse] = 0;
// Perform logical AND on words in common
for (int i = 0; i < wordsInUse; i++)
words[i] &= set.words[i];
recalculateWordsInUse();
checkInvariants();
}
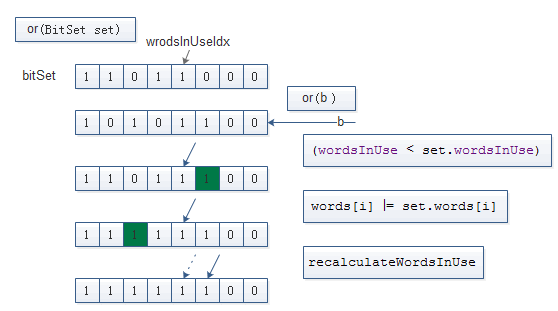
BitSet. or(BitSet set)
public void or(BitSet set) {
if (this == set)
return;
// 获取当前bitSet.wordsInUse 和给定的bitSet.wordsInUse中的较小者
// 如果当前的bitSet.wordsInUse小于给定的bitSet.wordsInUse 扩容
// 按位|
// 如果当前bitSet. wordsInUse较小 复制给定的bitSet 当前bitSet. wordInUse之后的数据
// 校验
int wordsInCommon = Math.min(wordsInUse, set.wordsInUse);
if (wordsInUse < set.wordsInUse) {
ensureCapacity(set.wordsInUse);
wordsInUse = set.wordsInUse;
}
// Perform logical OR on words in common
for (int i = 0; i < wordsInCommon; i++)
words[i] |= set.words[i];
// Copy any remaining words
if (wordsInCommon < set.wordsInUse)
System.arraycopy(set.words, wordsInCommon,
words, wordsInCommon,
wordsInUse - wordsInCommon);
// recalculateWordsInUse() is unnecessary
checkInvariants();
}
BitSet. xor(BitSet set)
public void xor(BitSet set) {
// 这里和上面的方法类似 不过核心操作有区别[这里是异或]
int wordsInCommon = Math.min(wordsInUse, set.wordsInUse);
if (wordsInUse < set.wordsInUse) {
ensureCapacity(set.wordsInUse);
wordsInUse = set.wordsInUse;
}
// Perform logical XOR on words in common
for (int i = 0; i < wordsInCommon; i++)
words[i] ^= set.words[i];
// Copy any remaining words
if (wordsInCommon < set.wordsInUse)
System.arraycopy(set.words, wordsInCommon,
words, wordsInCommon,
set.wordsInUse - wordsInCommon);
recalculateWordsInUse();
checkInvariants();
}

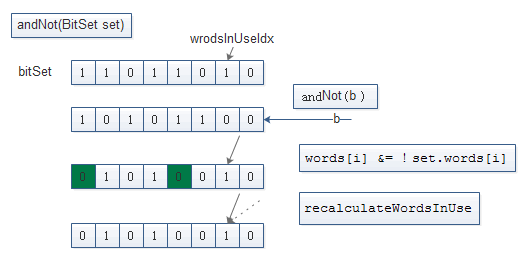
BitSet. andNot(BitSet set)
public void andNot(BitSet set) {
// Perform logical (a & !b) on words in common
// 对两个bitSet的公共部分 做this.bitSet & !bitSet的操作
// 重新计算wordsInUse 并校验
for (int i = Math.min(wordsInUse, set.wordsInUse) - 1; i >= 0; i--)
words[i] &= ~set.words[i];
recalculateWordsInUse();
checkInvariants();
}
BitSet. trimToSize()
private void trimToSize() {
// 拷贝前wordsInUse个long
if (wordsInUse != words.length) {
words = Arrays.copyOf(words, wordsInUse);
checkInvariants();
}
}
BitSet. toByteArray()
public byte[] toByteArray() {
// 如果wordsInUse为0, 返回一个空的byte数组
// 获取words中的字节数 [long的个数 * 8 + 剩余的字节个数]
// 创建一个len的字节数组 并将wrods中的数据复制到bytes
int n = wordsInUse;
if (n == 0)
return new byte[0];
int len = 8 * (n-1);
for (long x = words[n - 1]; x != 0; x >>>= 8)
len++;
byte[] bytes = new byte[len];
ByteBuffer bb = ByteBuffer.wrap(bytes).order(ByteOrder.LITTLE_ENDIAN);
for (int i = 0; i < n - 1; i++)
bb.putLong(words[i]);
for (long x = words[n - 1]; x != 0; x >>>= 8)
bb.put((byte) (x & 0xff));
return bytes;
}
BitSet. toLongArray()
public long[] toLongArray() {
// 获取words中的前wordsInUse个数据
return Arrays.copyOf(words, wordsInUse);
}
BitSet. length()
public int length() {
// 获取所有的已用的位的个数
if (wordsInUse == 0)
return 0;
return BITS_PER_WORD * (wordsInUse - 1) +
(BITS_PER_WORD - Long.numberOfLeadingZeros(words[wordsInUse - 1]));
}
BitSet. isEmpty()
public boolean isEmpty() {
return wordsInUse == 0;
}
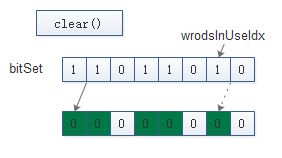
BitSet. clear()
public void clear() {
// 清空所有数据
while (wordsInUse > 0)
words[--wordsInUse] = 0;
}
BitSet. hashCode()
public int hashCode() {
long h = 1234;
for (int i = wordsInUse; --i >= 0; )
h ^= words[i] * (i + 1);
return (int)((h >> 32) ^ h);
}
BitSet. size()
public int size() {
return words.length * BITS_PER_WORD;
}
BitSet. equals(Object obj)
public boolean equals(Object obj) {
// RTTI校验
if (!(obj instanceof BitSet))
return false;
if (this == obj)
return true;
BitSet set = (BitSet) obj;
// 校验两个bitSet
// 比较wordsInUse
// 比较每一个long
checkInvariants();
set.checkInvariants();
if (wordsInUse != set.wordsInUse)
return false;
// Check words in use by both BitSets
for (int i = 0; i < wordsInUse; i++)
if (words[i] != set.words[i])
return false;
return true;
}
BitSet. clone()
public Object clone() {
// 如果容量不固定 则执行trimToSize操作 防止空间的浪费
// 复制BitSet, words
if (! sizeIsSticky)
trimToSize();
try {
BitSet result = (BitSet) super.clone();
result.words = words.clone();
result.checkInvariants();
return result;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
BitSet. toString()
public String toString() {
checkInvariants();
int numBits = (wordsInUse > 128) ?
cardinality() : wordsInUse * BITS_PER_WORD;
StringBuilder b = new StringBuilder(6*numBits + 2);
b.append('{');
// 找到所有的值为1的位的索引 拼接成字符串 返回
int i = nextSetBit(0);
if (i != -1) {
b.append(i);
for (i = nextSetBit(i+1); i >= 0; i = nextSetBit(i+1)) {
// 找到i之后到endOfRun之间的连续的1
int endOfRun = nextClearBit(i);
do { b.append(", ").append(i); }
while (++i < endOfRun);
}
}
b.append('}');
return b.toString();
}
->
这个估计是用到了所有的位操作了吧, 与, 或, 非, 异或, 与非[没有或非, 同或] 以及移位操作
其中 核心业务主要在于 get, set, flip, and, or, xor, [previous /next][Clear / Set]Bit
其中 flip对应异或的使用是非常经典的
这个数据结构 对于内存有要求的场景来说是非常适用的, hash排序啊, 去重等等














 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









