







根据caffe官网教程我们知道,caffe是通过层来定义网络的,layer既是model基础,也是计算的基本单元。而layer的操作对象就是之前学习的Blob。以后像在caffe框架下实现自己的算法,应该主要是添加自己的layer了,这也是我学习caffe源码的主要原因之一。
还是先通过caffe官网教程对layer有个整体的认识,为了方便还是把它贴过来。
Layer computation and connections
The layer is the essence of a model and the fundamental unit of computation. Layers convolve filters, pool, take inner products, apply nonlinearities like rectified-linear and sigmoid and other elementwise transformations, normalize, load data, and compute losses like softmax and hinge. See the layer catalogue for all operations. Most of the types needed for state-of-the-art deep learning tasks are there.
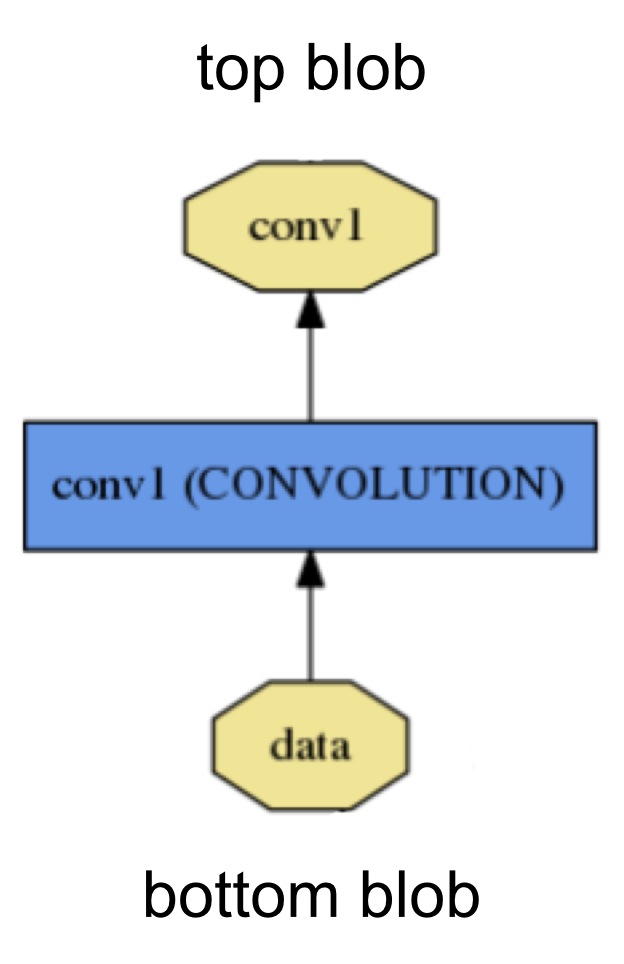
A layer takes input through bottom connections and makes output through top connections.
Each layer type defines three critical computations: setup, forward, and backward.
1.Setup: initialize the layer and its connections once at model initialization.
2.Forward: given input from bottom compute the output and send to the top.
3.Backward: given the gradient w.r.t. the top output compute the gradient w.r.t. to the input and send to the bottom. A layer with parameters computes the gradient w.r.t. to its parameters and stores it internally.
More specifically, there will be two Forward and Backward functions implemented, one for CPU and one for GPU. If you do not implement a GPU version, the layer will fall back to the CPU functions as a backup option. This may come handy if you would like to do quick experiments, although it may come with additional data transfer cost (its inputs will be copied from GPU to CPU, and its outputs will be copied back from CPU to GPU).
Layers have two key responsibilities for the operation of the network as a whole: a forward pass that takes the inputs and produces the outputs, and a backward pass that takes the gradient with respect to the output, and computes the gradients with respect to the parameters and to the inputs, which are in turn back-propagated to earlier layers. These passes are simply the composition of each layer’s forward and backward.
Developing custom layers requires minimal effort by the compositionality of the network and modularity of the code. Define the setup, forward, and backward for the layer and it is ready for inclusion in a net.
官网说自定义一个层不用花太多功夫的,只要定义setup,forward,backward就可以用了,而Layer应该就是我们写自定义层时要继承的。接下来就通过读源码学习怎样定义自己的layer吧。还是一样,以注释的方式读源码,然后总结。
1.源码
layer.hpp
官方的注释已经很清楚,还是按照自己的理解再注释一遍吧,有不对的地方,还请指正。
#ifndef CAFFE_LAYER_H_
#define CAFFE_LAYER_H_
#include <algorithm>
#include <string>
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer_factory.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/math_functions.hpp"
/**
Forward declare boost::thread instead of including boost/thread.hpp
to avoid a boost/NVCC issues (#1009, #1010) on OSX.
*/
namespace boost { class mutex; }
namespace caffe {
/**
* @brief An interface for the units of computation which can be composed into a
* Net.
*
* Layer%s must implement a Forward function, in which they take their input
* (bottom) Blob%s (if any) and compute their output Blob%s (if any).
* They may also implement a Backward function, in which they compute the error
* gradients with respect to their input Blob%s, given the error gradients with
* their output Blob%s.
*/
// Layer必须有一个Forward函数,该函数将bottom blobs作为输入,然后计算出output blobs。
// Layer可能会有一个Backward函数,该函数根据output blobs的error gradients计算出关于input blobs的
// error gradients。
template <typename Dtype>
class Layer {
public:
/**
* You should not implement your own constructor. Any set up code should go
* to SetUp(), where the dimensions of the bottom blobs are provided to the
* layer.
*/
// 不要用自己自己的构造函数,所有设置参数的代码都应该写到SetUp函数中,这个函数也会设置
// bottom blobs的维度。
// 下面是显示构造函数,其输入是在caffe.proto中定义的LayerParameter message自动生成的类的引用,
// 所以参数应该从protocol buffer文件中解析来的。
// 可以先跳到后面看看参数都是什么意思
explicit Layer(const LayerParameter& param)
: layer_param_(param), is_shared_(false) {
// Set phase and copy blobs (if there are any).
// 设置pahse,并从protobuf中拷贝所有的blobs
phase_ = param.phase();
if (layer_param_.blobs_size() > 0) {
blobs_.resize(layer_param_.blobs_size());
for (int i = 0; i < layer_param_.blobs_size(); ++i) {
blobs_[i].reset(new Blob<Dtype>());
blobs_[i]->FromProto(layer_param_.blobs(i));
}
}
}
virtual ~Layer() {}
/**
* @brief Implements common layer setup functionality.
*
* @param bottom the preshaped input blobs
* @param top
* the allocated but unshaped output blobs, to be shaped by Reshape
*
* Checks that the number of bottom and top blobs is correct.
* Calls LayerSetUp to do special layer setup for individual layer types,
* followed by Reshape to set up sizes of top blobs and internal buffers.
* Sets up the loss weight multiplier blobs for any non-zero loss weights.
* This method may not be overridden.
*/
// 实现公共层的设置功能
void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// 初始化mutex,多线程的东西,后面再仔细学习
InitMutex();
// 检查bottom和top blobs的个数是否正确
CheckBlobCounts(bottom, top);
// 设置具体的层
LayerSetUp(bottom, top);
// reshape top blob和内部的buffers
Reshape(bottom, top);
// 给具有非零loss权重的top设置loss权重乘子
SetLossWeights(top);
}
/**
* @brief Does layer-specific setup: your layer should implement this function
* as well as Reshape.
*
* @param bottom
* the preshaped input blobs, whose data fields store the input data for
* this layer
* @param top
* the allocated but unshaped output blobs
*
* This method should do one-time layer specific setup. This includes reading
* and processing relevent parameters from the <code>layer_param_</code>.
* Setting up the shapes of top blobs and internal buffers should be done in
* <code>Reshape</code>, which will be called before the forward pass to
* adjust the top blob sizes.
*/
// 具体层的设置,如果自定义层就应该实现这个函数和Reshape
// 参数bottom也就时输入blobs,其形状是提前设定好的,存储了输入数据
// 该方法就是做一次具体层的设置。其中包括从具体层的protobuf <code>layer_param_</code>中读入并处理相关参数
// 还要通过<code>Reshape</code>(不同的层用不同的名字)设置top blobs和内部buffers的形状,在调用Forward函数
// 之前要先调用该函数来调整top blobs的形状
// 该函数是虚的,利用了多态性,不同层有不同的实现方法
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {}
/**
* @brief Whether a layer should be shared by multiple nets during data
* parallelism. By default, all layers except for data layers should
* not be shared. data layers should be shared to ensure each worker
* solver access data sequentially during data parallelism.
*/
// 返回这个层在数据并行时是否应该被多个网络共享,默认是除了data layer,所有层都要不应该被共享
// data layer应该被共享,这样数据并行时,就可以保证每个worker solver有序的获取数据
virtual inline bool ShareInParallel() const { return false; }
/** @brief Return whether this layer is actually shared by other nets.
* If ShareInParallel() is true and using more than one GPU and the
* net has TRAIN phase, then this function is expected return true.
*/
// 返回这个层是否确实被替他的网络共享了。如果ShareInParallel()返回的时true,并且
// 使用多个gpu,并且是在TRAIN阶段,那么该函数就会返回true
inline bool IsShared() const { return is_shared_; }
/** @brief Set whether this layer is actually shared by other nets
* If ShareInParallel() is true and using more than one GPU and the
* net has TRAIN phase, then is_shared should be set true.
*/
// 与上面对应,它是来设置is_shared_的
inline void SetShared(bool is_shared) {
CHECK(ShareInParallel() || !is_shared)
<< type() << "Layer does not support sharing.";
is_shared_ = is_shared;
}
/**
* @brief Adjust the shapes of top blobs and internal buffers to accommodate
* the shapes of the bottom blobs.
*
* @param bottom the input blobs, with the requested input shapes
* @param top the top blobs, which should be reshaped as needed
*
* This method should reshape top blobs as needed according to the shapes
* of the bottom (input) blobs, as well as reshaping any internal buffers
* and making any other necessary adjustments so that the layer can
* accommodate the bottom blobs.
*/
// 这个函数就是根据bottom blobs的形状等信息来调整top blobs,内部buffers和其他需要调整的
// 东西,来适应bottom blobs。
// 参数 bottom, 输入blobs,它包含需要的输入形状信息
// 参数 top, 该层的top blobs,需要被reshape的
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;
/**
* @brief Given the bottom blobs, compute the top blobs and the loss.
*
* @param bottom
* the input blobs, whose data fields store the input data for this layer
* @param top
* the preshaped output blobs, whose data fields will store this layers'
* outputs
* \return The total loss from the layer.
*
* The Forward wrapper calls the relevant device wrapper function
* (Forward_cpu or Forward_gpu) to compute the top blob values given the
* bottom blobs. If the layer has any non-zero loss_weights, the wrapper
* then computes and returns the loss.
*
* Your layer should implement Forward_cpu and (optionally) Forward_gpu.
*/
// Forward函数比较清楚了,根据输入bottom blobs调用Forward_cpu or Forward_gpu函数,
// 来计算top blobs, 如果该层有非零的loss_weights,那么Forward_cpu or Forward_gpu函数
// 会计算该层的loss,并返回loss
// 参数就是我们熟悉bottom blobs 和 top blobs
inline Dtype Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
/**
* @brief Given the top blob error gradients, compute the bottom blob error
* gradients.
*
* @param top
* the output blobs, whose diff fields store the gradient of the error
* with respect to themselves
* @param propagate_down
* a vector with equal length to bottom, with each index indicating
* whether to propagate the error gradients down to the bottom blob at
* the corresponding index
* @param bottom
* the input blobs, whose diff fields will store the gradient of the error
* with respect to themselves after Backward is run
*
* The Backward wrapper calls the relevant device wrapper function
* (Backward_cpu or Backward_gpu) to compute the bottom blob diffs given the
* top blob diffs.
*
* Your layer should implement Backward_cpu and (optionally) Backward_gpu.
*/
// Backward函数也比较熟悉了,根据top blob diff调用Backward_cpu or Backward_gpu函数
// 计算bottom blobs diff,Backward_cpu or Backward_gpu就是我们自定层时要实现的函数
// 参数top, 就是输出blobs, top blobs,其中存储了关于它自己的梯度
// 参数propagate_down,bool型的vector,它的长度和bottom一样,也就时输入blob的个数,
// 该参数表示其对应的blob是否要计算梯度
// 参数bottom, 输入blobs, 它的diff指向的空间存储关于它自己的梯度信息
inline void Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom);
/**
* @brief Returns the vector of learnable parameter blobs.
*/
// 返回可学习参数blobs的vector
vector<shared_ptr<Blob<Dtype> > >& blobs() {
return blobs_;
}
/**
* @brief Returns the layer parameter.
*/
// 返回层的参数,其类型const的LayerParameter,也就时protobuf
const LayerParameter& layer_param() const { return layer_param_; }
/**
* @brief Writes the layer parameter to a protocol buffer
*/
// 将层参数写到protocol buffer中
virtual void ToProto(LayerParameter* param, bool write_diff = false);
/**
* @brief Returns the scalar loss associated with a top blob at a given index.
*/
// 返回给定index的top blob在计算loss中的权重,如果index超出范围,返回0
inline Dtype loss(const int top_index) const {
return (loss_.size() > top_index) ? loss_[top_index] : Dtype(0);
}
/**
* @brief Sets the loss associated with a top blob at a given index.
*/
// 与上面函数对应,设置相应的权重,如果超出范围,就在loss_中添加一个元素,并设置为value
inline void set_loss(const int top_index, const Dtype value) {
if (loss_.size() <= top_index) {
loss_.resize(top_index + 1, Dtype(0));
}
loss_[top_index] = value;
}
/**
* @brief Returns the layer type.
*/
// 返回layer的类型
virtual inline const char* type() const { return ""; }
/**
* @brief Returns the exact number of bottom blobs required by the layer,
* or -1 if no exact number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some exact number of bottom blobs.
*/
// 返回该层需要的准确的blob的数量,如果不需要确切的数量,则返回-1
// 如果自定义层需要确切的数量,那么这个函数应该被重写
virtual inline int ExactNumBottomBlobs() const { return -1; }
/**
* @brief Returns the minimum number of bottom blobs required by the layer,
* or -1 if no minimum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some minimum number of bottom blobs.
*/
// 与上面对应,它是返回最小的数量
virtual inline int MinBottomBlobs() const { return -1; }
/**
* @brief Returns the maximum number of bottom blobs required by the layer,
* or -1 if no maximum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some maximum number of bottom blobs.
*/
// 与上面对应,返回最大的数量
virtual inline int MaxBottomBlobs() const { return -1; }
/**
* @brief Returns the exact number of top blobs required by the layer,
* or -1 if no exact number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some exact number of top blobs.
*/
// 与bottom blobs对应
virtual inline int ExactNumTopBlobs() const { return -1; }
/**
* @brief Returns the minimum number of top blobs required by the layer,
* or -1 if no minimum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some minimum number of top blobs.
*/
// 与bottom blobs对应
virtual inline int MinTopBlobs() const { return -1; }
/**
* @brief Returns the maximum number of top blobs required by the layer,
* or -1 if no maximum number is required.
*
* This method should be overridden to return a non-negative value if your
* layer expects some maximum number of top blobs.
*/
// 与bottom blobs对应
virtual inline int MaxTopBlobs() const { return -1; }
/**
* @brief Returns true if the layer requires an equal number of bottom and
* top blobs.
*
* This method should be overridden to return true if your layer expects an
* equal number of bottom and top blobs.
*/
// 返回输入输出blob数是否要相等
virtual inline bool EqualNumBottomTopBlobs() const { return false; }
/**
* @brief Return whether "anonymous" top blobs are created automatically
* by the layer.
*
* If this method returns true, Net::Init will create enough "anonymous" top
* blobs to fulfill the requirement specified by ExactNumTopBlobs() or
* MinTopBlobs().
*/
// 返回是否要自动创建“匿名”top blobs
// 如果返回true, Net::Init就会自动创建top blobs来满足ExactNumTopBlobs()和MinTopBlobs()
// 的需要
virtual inline bool AutoTopBlobs() const { return false; }
/**
* @brief Return whether to allow force_backward for a given bottom blob
* index.
*
* If AllowForceBackward(i) == false, we will ignore the force_backward
* setting and backpropagate to blob i only if it needs gradient information
* (as is done when force_backward == false).
*/
// 返回是否允许对制定的index的bottom blob做force_backward
// 如果llowForceBackward(i) == false,就忽略force_backward的设置
// 等价做法force_backward == false
virtual inline bool AllowForceBackward(const int bottom_index) const {
return true;
}
/**
* @brief Specifies whether the layer should compute gradients w.r.t. a
* parameter at a particular index given by param_id.
*
* You can safely ignore false values and always compute gradients
* for all parameters, but possibly with wasteful computation.
*/
// 返回对于制定的index的parameter是否需要计算梯度
// 为了安全可以计算全部的,但是会浪费计算资源
inline bool param_propagate_down(const int param_id) {
return (param_propagate_down_.size() > param_id) ?
param_propagate_down_[param_id] : false;
}
/**
* @brief Sets whether the layer should compute gradients w.r.t. a
* parameter at a particular index given by param_id.
*/
// 与上面对应,这里是设置
inline void set_param_propagate_down(const int param_id, const bool value) {
if (param_propagate_down_.size() <= param_id) {
param_propagate_down_.resize(param_id + 1, true);
}
param_propagate_down_[param_id] = value;
}
protected:
/** The protobuf that stores the layer parameters */
// 存储layer参数的protobuf
LayerParameter layer_param_;
/** The phase: TRAIN or TEST */
// 存储训练或测试的阶段参数
Phase phase_;
/** The vector that stores the learnable parameters as a set of blobs. */
// blobs_是一个vector容器,其元素是指向Blob的shared_ptr指针,将可学习的参数存在一组Blob类内,
// 可以参考[之前的学习笔记](http://blog.csdn.net/u011104550/article/details/51234256)
vector<shared_ptr<Blob<Dtype> > > blobs_;
/** Vector indicating whether to compute the diff of each param blob. */
// 是一个存储bool型元素的容器,表明对应的parm blob是否要计算导数
vector<bool> param_propagate_down_;
/** The vector that indicates whether each top blob has a non-zero weight in
* the objective function. */
// 表明在目标函数计算中,该层的每个top blob有非零的权值,也就是是否参与到目标函数的计算
vector<Dtype> loss_;
/** @brief Using the CPU device, compute the layer output. */
// cpu上的Forward 函数,纯虚函数,只能被继承不能被实例化,在子类中必须要实现
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;
/**
* @brief Using the GPU device, compute the layer output.
* Fall back to Forward_cpu() if unavailable.
*/
// gpu上的Forward 函数,如果没有定义该函数,回到cpu上计算
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// LOG(WARNING) << "Using CPU code as backup.";
return Forward_cpu(bottom, top);
}
/**
* @brief Using the CPU device, compute the gradients for any parameters and
* for the bottom blobs if propagate_down is true.
*/
// 与Forward_cpu对应
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) = 0;
/**
* @brief Using the GPU device, compute the gradients for any parameters and
* for the bottom blobs if propagate_down is true.
* Fall back to Backward_cpu() if unavailable.
*/
//与上面对应
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
// LOG(WARNING) << "Using CPU code as backup.";
Backward_cpu(top, propagate_down, bottom);
}
/**
* Called by the parent Layer's SetUp to check that the number of bottom
* and top Blobs provided as input match the expected numbers specified by
* the {ExactNum,Min,Max}{Bottom,Top}Blobs() functions.
*/
// 该函数被父类的SetUp调用,检查blob的数量是否符合规定的要求,由前面给出的函数很容易理解
virtual void CheckBlobCounts(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
if (ExactNumBottomBlobs() >= 0) {
CHECK_EQ(ExactNumBottomBlobs(), bottom.size())
<< type() << " Layer takes " << ExactNumBottomBlobs()
<< " bottom blob(s) as input.";
}
if (MinBottomBlobs() >= 0) {
CHECK_LE(MinBottomBlobs(), bottom.size())
<< type() << " Layer takes at least " << MinBottomBlobs()
<< " bottom blob(s) as input.";
}
if (MaxBottomBlobs() >= 0) {
CHECK_GE(MaxBottomBlobs(), bottom.size())
<< type() << " Layer takes at most " << MaxBottomBlobs()
<< " bottom blob(s) as input.";
}
if (ExactNumTopBlobs() >= 0) {
CHECK_EQ(ExactNumTopBlobs(), top.size())
<< type() << " Layer produces " << ExactNumTopBlobs()
<< " top blob(s) as output.";
}
if (MinTopBlobs() >= 0) {
CHECK_LE(MinTopBlobs(), top.size())
<< type() << " Layer produces at least " << MinTopBlobs()
<< " top blob(s) as output.";
}
if (MaxTopBlobs() >= 0) {
CHECK_GE(MaxTopBlobs(), top.size())
<< type() << " Layer produces at most " << MaxTopBlobs()
<< " top blob(s) as output.";
}
if (EqualNumBottomTopBlobs()) {
CHECK_EQ(bottom.size(), top.size())
<< type() << " Layer produces one top blob as output for each "
<< "bottom blob input.";
}
}
/**
* Called by SetUp to initialize the weights associated with any top blobs in
* the loss function. Store non-zero loss weights in the diff blob.
*/
// 被SetUp函数调用,初始化计算loss时需要top blob对应的权重
inline void SetLossWeights(const vector<Blob<Dtype>*>& top) {
const int num_loss_weights = layer_param_.loss_weight_size();
if (num_loss_weights) {
CHECK_EQ(top.size(), num_loss_weights) << "loss_weight must be "
"unspecified or specified once per top blob.";
for (int top_id = 0; top_id < top.size(); ++top_id) {
const Dtype loss_weight = layer_param_.loss_weight(top_id);
if (loss_weight == Dtype(0)) { continue; }
this->set_loss(top_id, loss_weight);
const int count = top[top_id]->count();
Dtype* loss_multiplier = top[top_id]->mutable_cpu_diff();
// 将count个loss_weight存到loss_multiplier中
// 也就是将loss_multiplier的前count个值设置为loss_weight
caffe_set(count, loss_weight, loss_multiplier);
}
}
}
private:
/** Whether this layer is actually shared by other nets*/
// 表明是否可以被其他网络共享
bool is_shared_;
// 下面是关于多线程的变量和函数
/** The mutex for sequential forward if this layer is shared */
shared_ptr<boost::mutex> forward_mutex_;
/** Initialize forward_mutex_ */
void InitMutex();
/** Lock forward_mutex_ if this layer is shared */
void Lock();
/** Unlock forward_mutex_ if this layer is shared */
void Unlock();
DISABLE_COPY_AND_ASSIGN(Layer);
}; // class Layer
// Forward and backward wrappers. You should implement the cpu and
// gpu specific implementations instead, and should not change these
// functions.
// 下面两个函数是Forward and backward wrappers。具体实现时定义自己的cpu和gpu版本的,
// 然后会被这两个函数调用,不要修改这两个函数
template <typename Dtype>
inline Dtype Layer<Dtype>::Forward(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Lock during forward to ensure sequential forward
Lock();
Dtype loss = 0;
Reshape(bottom, top);
switch (Caffe::mode()) {
case Caffe::CPU:
Forward_cpu(bottom, top);
// 计算总的loss值,即将所有top blobs的loss累加
// 每个top blob的loss是loss_weights和data对应相乘
for (int top_id = 0; top_id < top.size(); ++top_id) {
if (!this->loss(top_id)) { continue; }
const int count = top[top_id]->count();
const Dtype* data = top[top_id]->cpu_data();
const Dtype* loss_weights = top[top_id]->cpu_diff();
loss += caffe_cpu_dot(count, data, loss_weights);
}
break;
// GPU版本
case Caffe::GPU:
Forward_gpu(bottom, top);
#ifndef CPU_ONLY
for (int top_id = 0; top_id < top.size(); ++top_id) {
if (!this->loss(top_id)) { continue; }
const int count = top[top_id]->count();
const Dtype* data = top[top_id]->gpu_data();
const Dtype* loss_weights = top[top_id]->gpu_diff();
Dtype blob_loss = 0;
caffe_gpu_dot(count, data, loss_weights, &blob_loss);
loss += blob_loss;
}
#endif
break;
default:
LOG(FATAL) << "Unknown caffe mode.";
}
Unlock();
return loss;
}
// Backward比较好理解
template <typename Dtype>
inline void Layer<Dtype>::Backward(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
switch (Caffe::mode()) {
case Caffe::CPU:
Backward_cpu(top, propagate_down, bottom);
break;
case Caffe::GPU:
Backward_gpu(top, propagate_down, bottom);
break;
default:
LOG(FATAL) << "Unknown caffe mode.";
}
}
// Serialize LayerParameter to protocol buffer
// 将layer_param_和Blob数据写入protocol buffer中,
// 在message LayerParameter中定义了repeated BlobProto blobs = 7;
// 所以blobs存数值信息,layer_param_存层的一些参数
template <typename Dtype>
void Layer<Dtype>::ToProto(LayerParameter* param, bool write_diff) {
param->Clear();
param->CopyFrom(layer_param_);
param->clear_blobs();
for (int i = 0; i < blobs_.size(); ++i) {
blobs_[i]->ToProto(param->add_blobs(), write_diff);
}
}
} // namespace caffe
#endif // CAFFE_LAYER_H_
终于读完layer.hpp了,其实基本上已经了解Layer这个基类了,下面我们看到layer.cpp文件中就只剩下几个多线程的函数了。多线程的东西后面单独来学习。
layer.cpp
#include <boost/thread.hpp>
#include "caffe/layer.hpp"
namespace caffe {
template <typename Dtype>
void Layer<Dtype>::InitMutex() {
forward_mutex_.reset(new boost::mutex());
}
template <typename Dtype>
void Layer<Dtype>::Lock() {
if (IsShared()) {
forward_mutex_->lock();
}
}
template <typename Dtype>
void Layer<Dtype>::Unlock() {
if (IsShared()) {
forward_mutex_->unlock();
}
}
INSTANTIATE_CLASS(Layer);
} // namespace caffe
2.总结
阅读完源代码,总结一下Layer的主要部分吧,首先,就是SetUp,包括InitMutex(初始化Mutex),CheckBlobCounts(检查blob个数是否符合条件),LayerSetUp(调用子类也就是具体的层的设置函数完成具体层的设置),Reshape(reshape top blobs,内部buffer和其他必要的东西符合bottom blobs的形状信息),SetLossWeights(设置top blobs在计算loss时对应的参数)。第二,Forward,给定bottom blobs计算top blobs和loss,具体实现时定义自己的cpu和gpu版本的,然后会被这个函数调用,不要修改这修改它,这和torch的实现方式是一样的。第三,Backward,给定top blobs的error diff计算bottom blobs的error diff,存到bottom blobs中的diff中。最后,应该是多线程,并行训练了,这个后面再进一步学习。
这样后面就知道怎样用Layer这个基类了,而且离添加自己的层也就更进一步了。
个人理解,如有错误,请指正。














 9962
9962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









